
First add
parents
Showing
finetune_demo/finetune.py
0 → 100644
finetune_demo/inference.py
0 → 100644
model.properties
0 → 100644
resources/WECHAT.md
0 → 100644
resources/eval_needle.jpeg
0 → 100644
{kind=link}
452 KB
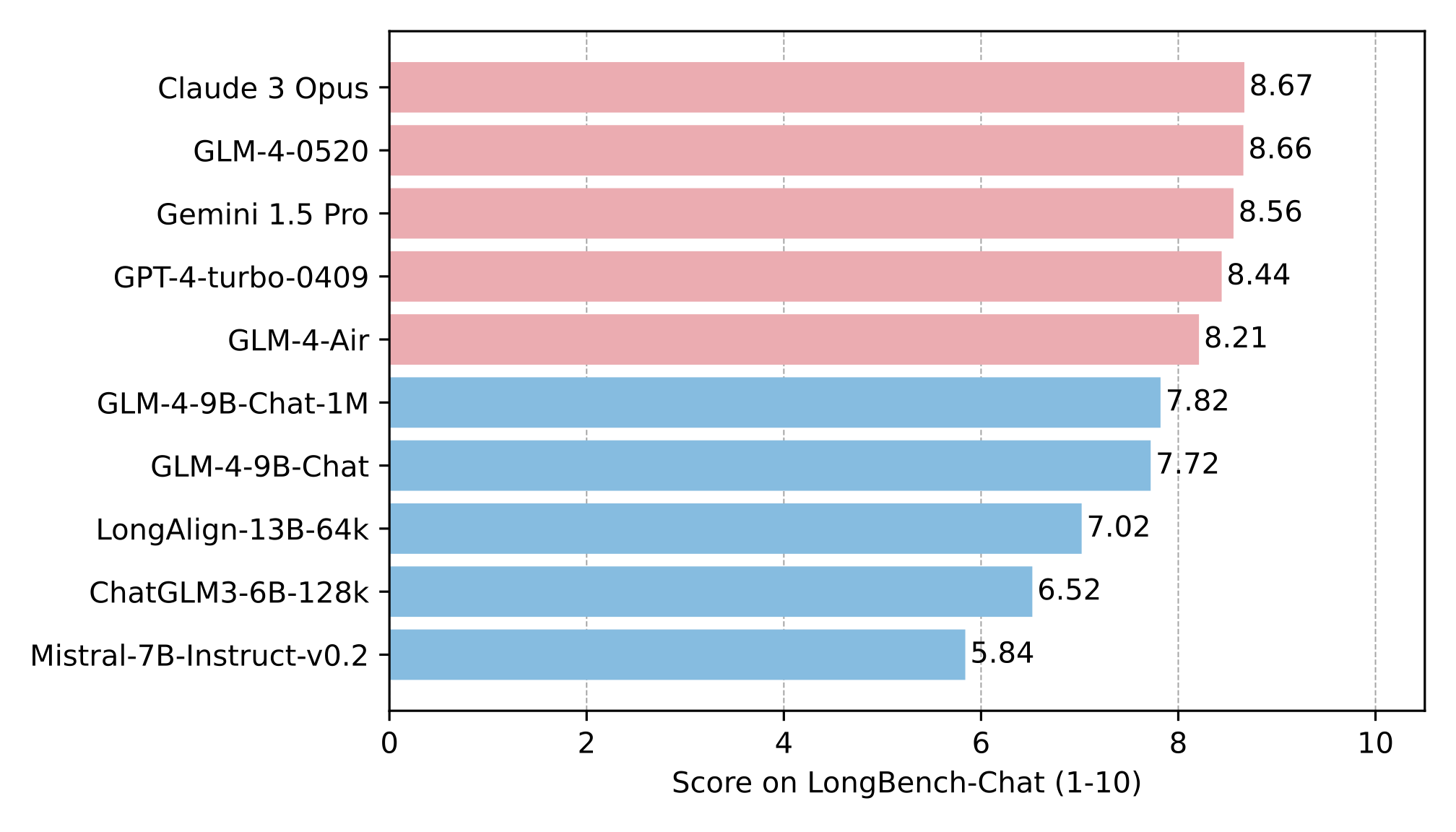
resources/longbench.png
0 → 100644
{kind=link}
164 KB
resources/wechat.jpg
0 → 100644
{kind=link}

151 KB