Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
GLM-4.6_vllm
Commits
03312b4a
Commit
03312b4a
authored
Oct 20, 2025
by
chenych
Browse files
Update README
parent
a05560f3
Changes
3
Hide whitespace changes
Inline
Side-by-side
Showing
3 changed files
with
8 additions
and
7 deletions
+8
-7
README.md
README.md
+7
-6
doc/model.png
doc/model.png
+0
-0
model.properties
model.properties
+1
-1
No files found.
README.md
View file @
03312b4a
...
@@ -4,19 +4,20 @@
...
@@ -4,19 +4,20 @@
GLM 4.6技术报告与 4.5 一致
GLM 4.6技术报告与 4.5 一致
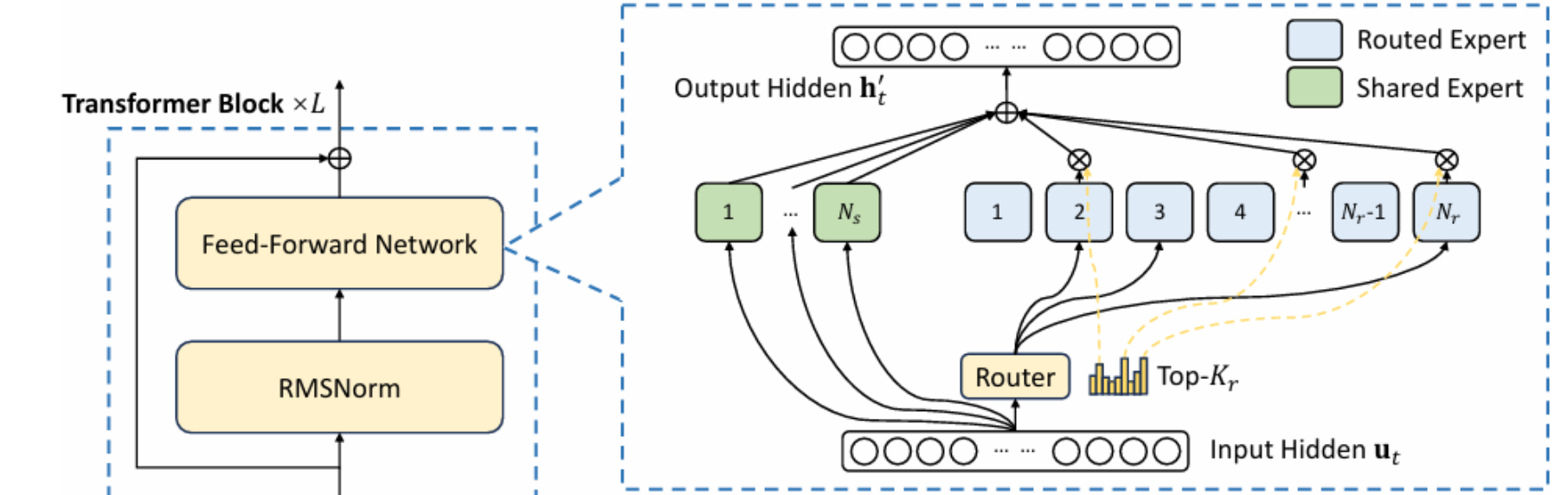
## 模型结构
## 模型结构
GLM-4.6 是智谱最新的旗舰模型,其总参数量 355B,激活参数 32B。GLM-4.6 所有核心能力上均完成了对 GLM-4.5 的超越,具体如下:
GLM-4.6 是智谱最新的旗舰
MOE
模型,其总参数量 355B,激活参数 32B。GLM-4.6 所有核心能力上均完成了对 GLM-4.5 的超越,具体如下:
高级编码能力:在公开基准与真实编程任务中,GLM-4.6 的代码能力对齐 Claude Sonnet 4,是国内已知的最好的 Coding 模型。
-
**
高级编码能力:
**
在公开基准与真实编程任务中,GLM-4.6 的代码能力对齐 Claude Sonnet 4,是国内已知的最好的 Coding 模型。
-
**上下文长度:**
上下文窗口由 128K
→
200K,适应更长的代码和智能体任务。
-
**上下文长度:**
上下文窗口由 128K
拓展到
200K,适应更长的代码和智能体任务。
-
**推理能力:**
推理能力提升,并支持在推理过程中调用工具。
-
**推理能力:**
推理能力提升,并支持在推理过程中调用工具。
-
**
搜索能力:**
增强了模型
在工具
调
用和搜索智能体
上的表现,在智能体框架中表现更好
。
-
**
智能体:**
GLM-4.6
在工具
使
用和
基于
搜索
的
智能体
方面表现更强,并能更高效地融入智能体框架
。
-
**写作能力:**
在文风、可读性与角色扮演场景中更符合人类偏好。
-
**写作能力:**
在文风、可读性与角色扮演场景中更符合人类偏好。
-
**多语言翻译:**
进一步增强跨语种任务的处理效果。
<div
align=
center
>
<div
align=
center
>
<img
src=
"./doc/model.png"
/>
<img
src=
"./doc/model.png"
/>
</div>
</div>
## 算法原理
## 算法原理
采用了多阶段的训练方案,并将序列长度从 4K 增加到了 128K。在预训练期间,模型首先在 15T token 的通用预训练语料库上训练,然后在 7T token 的代码和推理语料库上训练。预训练后,引入了 Mid-Training 阶段来进一步提升模型在专有领域上的性能。
<div
align=
center
>
<div
align=
center
>
<img
src=
"./doc/method.png"
/>
<img
src=
"./doc/method.png"
/>
</div>
</div>
...
@@ -135,7 +136,7 @@ ray start --address='x.x.x.x:6379' --num-gpus=8 --num-cpus=32
...
@@ -135,7 +136,7 @@ ray start --address='x.x.x.x:6379' --num-gpus=8 --num-cpus=32
> intel cpu 需要加参数:`--enforce-eager`
> intel cpu 需要加参数:`--enforce-eager`
```
bash
```
bash
vllm zai-org/GLM-4.6
\
vllm
serve
zai-org/GLM-4.6
\
--enforce-eager
\
--enforce-eager
\
--trust-remote-code
\
--trust-remote-code
\
--distributed-executor-backend
ray
\
--distributed-executor-backend
ray
\
...
...
doc/model.png
0 → 100644
View file @
03312b4a
260 KB
model.properties
View file @
03312b4a
...
@@ -9,4 +9,4 @@ appScenario=推理,对话问答,制造,金融,教育,广媒
...
@@ -9,4 +9,4 @@ appScenario=推理,对话问答,制造,金融,教育,广媒
# 框架类型
# 框架类型
frameType
=
vllm
frameType
=
vllm
# 加速卡类型
# 加速卡类型
accelerateType
=
K100AI
accelerateType
=
K100AI,BW1000
\ No newline at end of file
\ No newline at end of file
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}