
First commit
Showing
Contributors.md
0 → 100644
LICENSE
0 → 100644
README_origin.md
0 → 100644
{kind=link}

19.9 KB
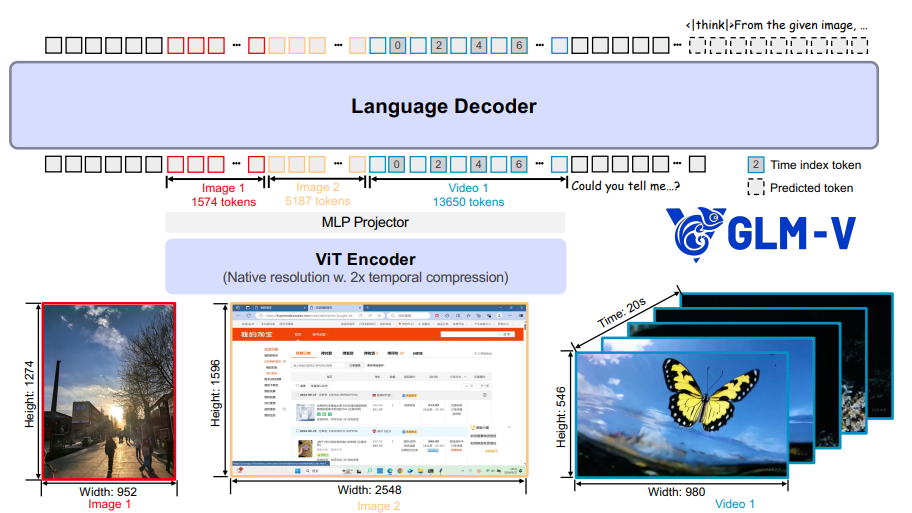
doc/methods.png
0 → 100644
{kind=link}

163 KB
doc/model.png
0 → 100644
{kind=link}
267 KB
doc/results-dcu.png
0 → 100644
{kind=link}
76.7 KB
docker/Dockerfile
0 → 100644
icon.png
0 → 100644
{kind=link}
53.8 KB
inference/trans_infer_cli.py
0 → 100644
model.properties
0 → 100644