
init & optimize
Showing
README.md
0 → 100755
README_origin.md
0 → 100755
doc/input.jpg
0 → 100644
{kind=link}
324 KB
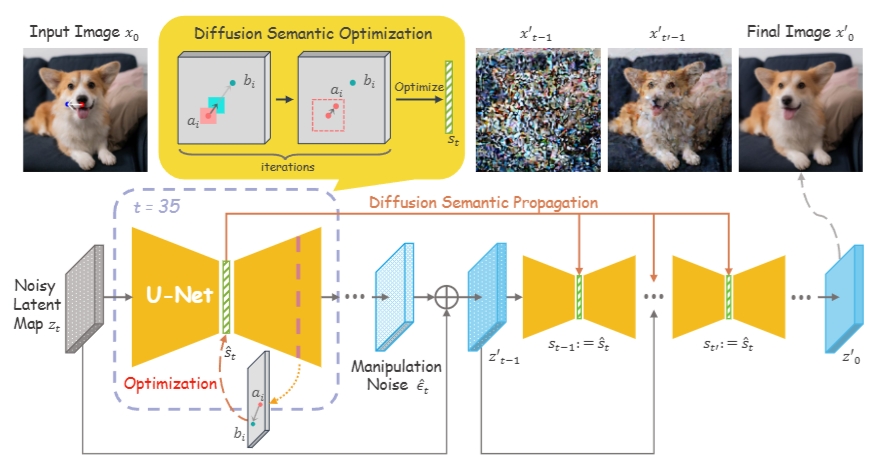
doc/overview.png
0 → 100644
{kind=link}
175 KB
doc/result.png
0 → 100644
{kind=link}

268 KB
doc/webui.jpg
0 → 100644
{kind=link}

202 KB
docker/Dockerfile
0 → 100644
drag_pipeline.py
0 → 100755
This diff is collapsed.
drag_ui.py
0 → 100755
environment.yaml
0 → 100755
icon.png
0 → 100644
{kind=link}
68.4 KB
image/GIF/boy-noise.gif
0 → 100755
{kind=link}

3.17 MB
{kind=link}

9.29 MB