
Initial commit
Showing
Contributors.md
0 → 100644
This diff is collapsed.
README_donut.md
0 → 100644
dataset/.gitkeep
deleted
100755 → 0
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
donut_cord_infernce.py
0 → 100644
misc/算法原理.png
0 → 100644
{kind=link}
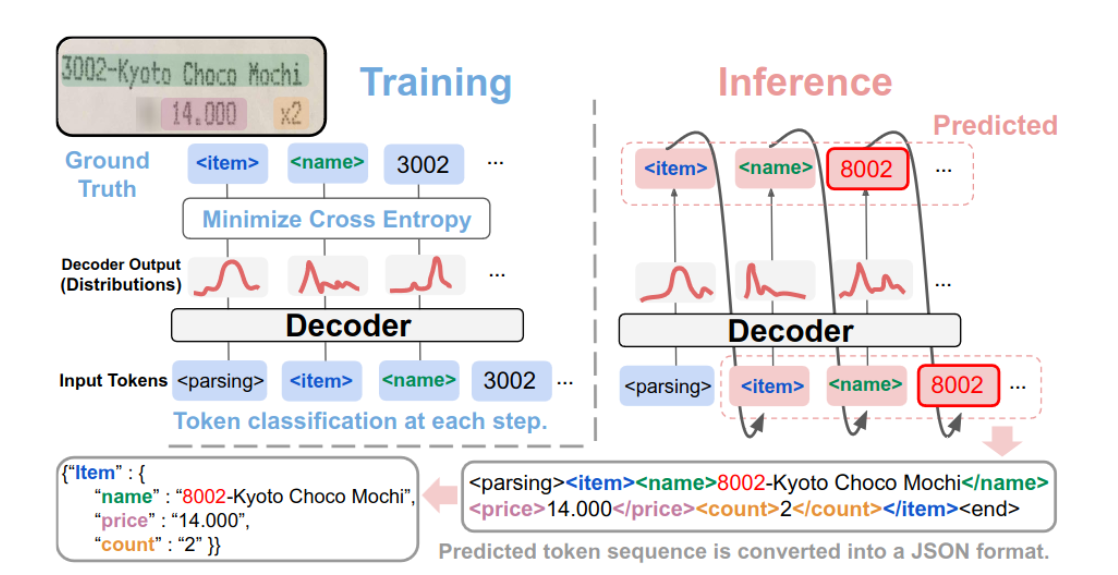
262 KB
model.properties
0 → 100644
multi_dcu_train.sh
0 → 100644
requirements.txt
0 → 100644
| pytorch-lightning==1.6.4 | |||
| transformers==4.25.1 | |||
| timm==0.5.4 | |||
| gradio==3.50.0 | |||
| donut-python | |||
| \ No newline at end of file |
single_dcu_train.sh
0 → 100644
synthdog/README.md
deleted
100755 → 0