
update code
Showing
.gitignore
0 → 100644
LICENSE.md
0 → 100644
README.md
0 → 100644
README_old.md
0 → 100644
asserts/Algorithm.jpg
0 → 100644
{kind=link}
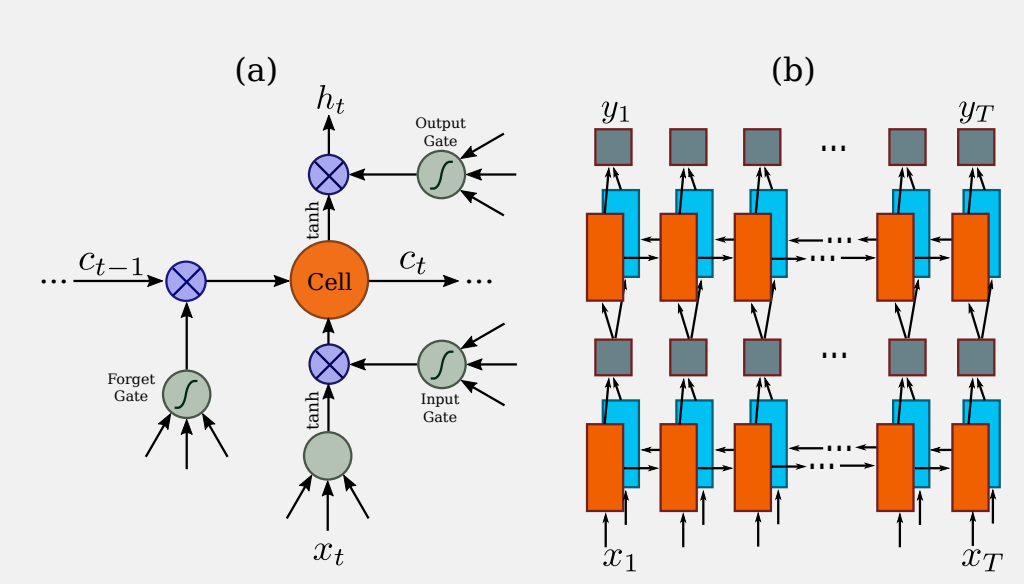
68.5 KB
asserts/model_structure.jpg
0 → 100644
{kind=link}
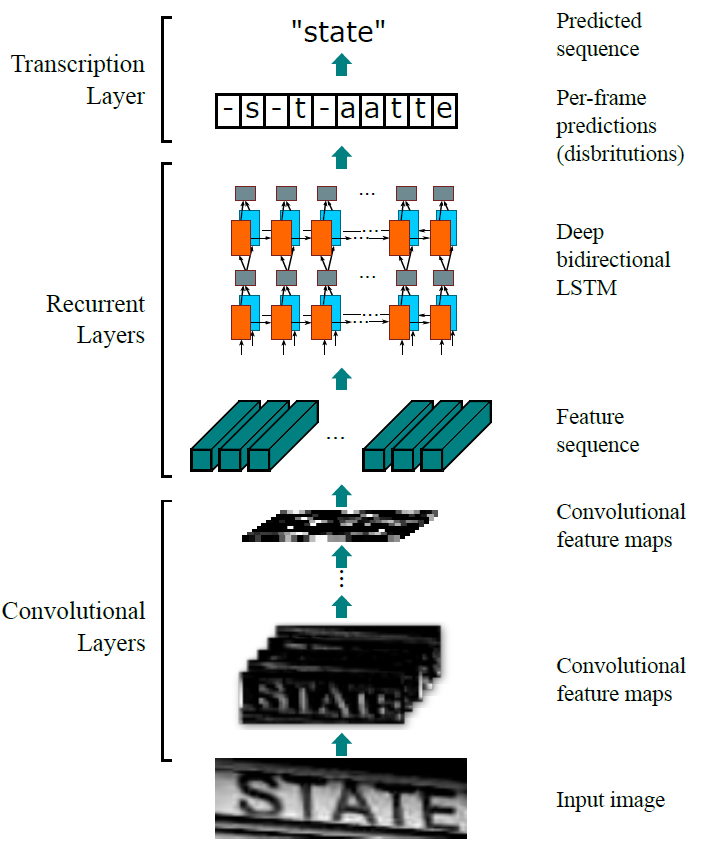
82.1 KB
asserts/result.jpg
0 → 100644
{kind=link}

2.78 KB
data/demo.png
0 → 100644
{kind=link}

18.7 KB
dataset.py
0 → 100644
demo.py
0 → 100644
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
model.properties
0 → 100644
models/__init__.py
0 → 100644
models/crnn.py
0 → 100644
requirements.txt
0 → 100644
| lmdb==1.0.0 |
test/test_utils.py
0 → 100644
tool/convert_t7.lua
0 → 100644
tool/convert_t7.py
0 → 100644
train.py
0 → 100644