
Initial commit
Showing
CODE_OF_CONDUCT.md
0 → 100644
FAQ.md
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
asset/dingding.png
0 → 100644
{kind=link}

94.1 KB
asset/model.jpg
0 → 100644
{kind=link}
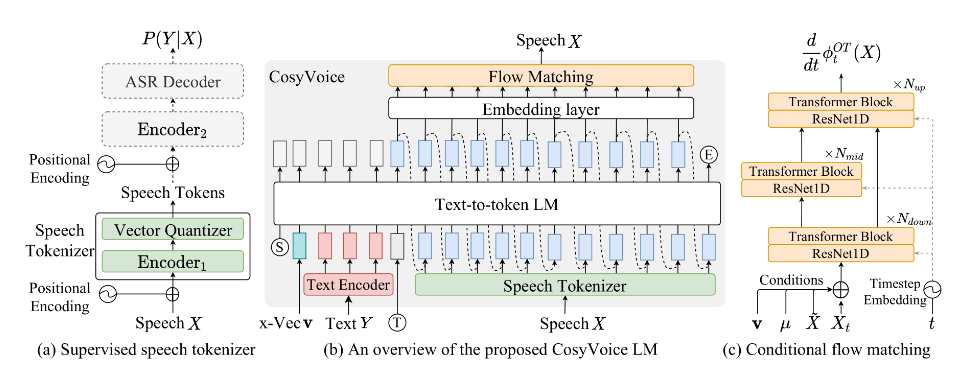
85.9 KB
asset/result.jpg
0 → 100644
{kind=link}
102 KB
asset/theory.jpg
0 → 100644
{kind=link}
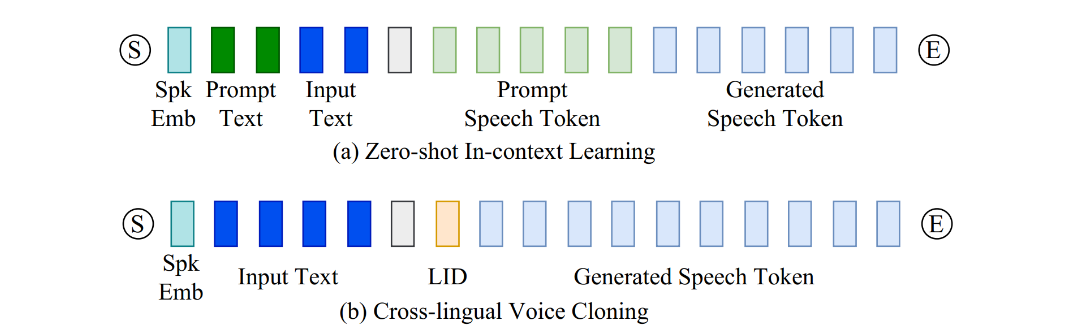
60.2 KB
cli_demo.py
0 → 100644
cosyvoice/__init__.py
0 → 100644
cosyvoice/bin/inference.py
0 → 100644
cosyvoice/bin/train.py
0 → 100644
cosyvoice/cli/__init__.py
0 → 100644
cosyvoice/cli/cosyvoice.py
0 → 100644
cosyvoice/cli/frontend.py
0 → 100644
cosyvoice/cli/model.py
0 → 100644
cosyvoice/dataset/dataset.py
0 → 100644
cosyvoice/flow/decoder.py
0 → 100644