
create new model
Showing
docker/Dockerfile
0 → 100644
img/conformer_encoder.png
0 → 100644
{kind=link}
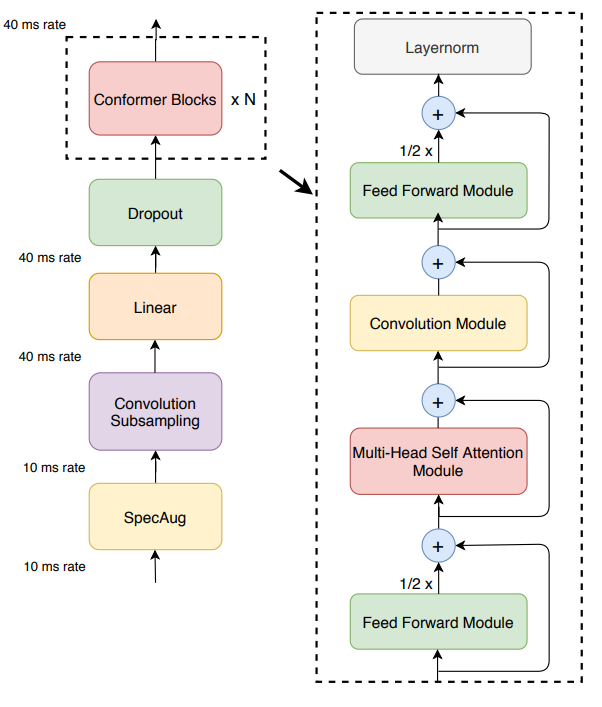
66 KB
img/model.png
0 → 100644
{kind=link}
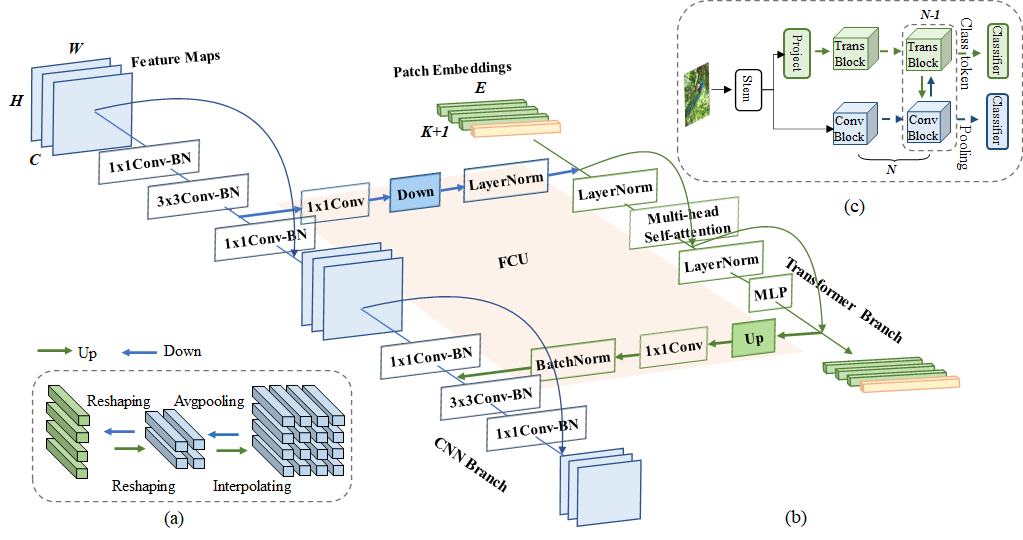
105 KB
File added
File added
File added
File added
File added
File added
File added
File added
File added
File added
File added