
update codes
Showing
.gitignore
0 → 100644
LICENSE
0 → 100644
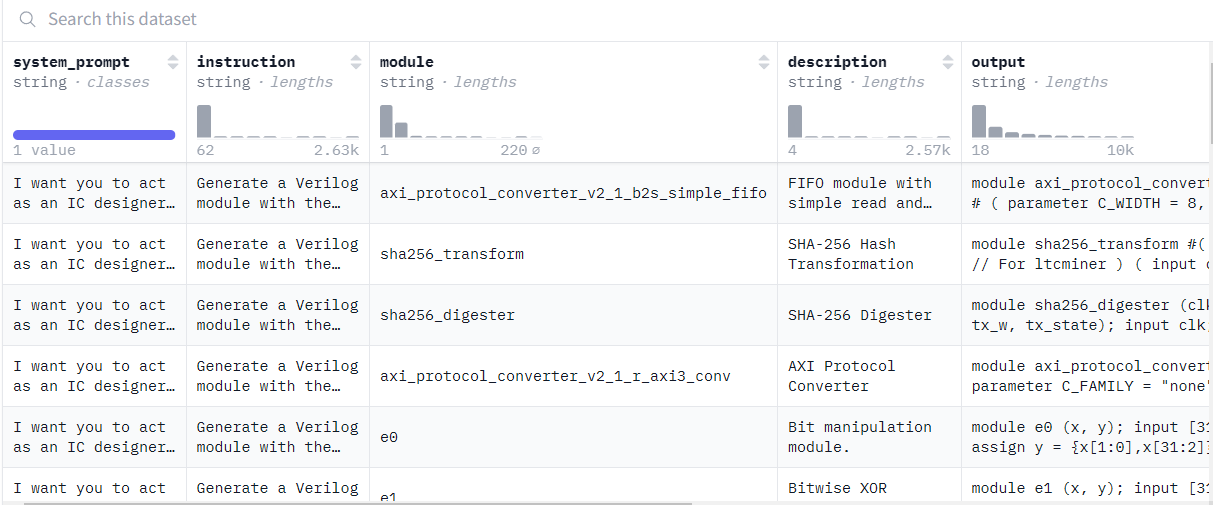
asserts/dataset.png
0 → 100644
{kind=link}
45.5 KB
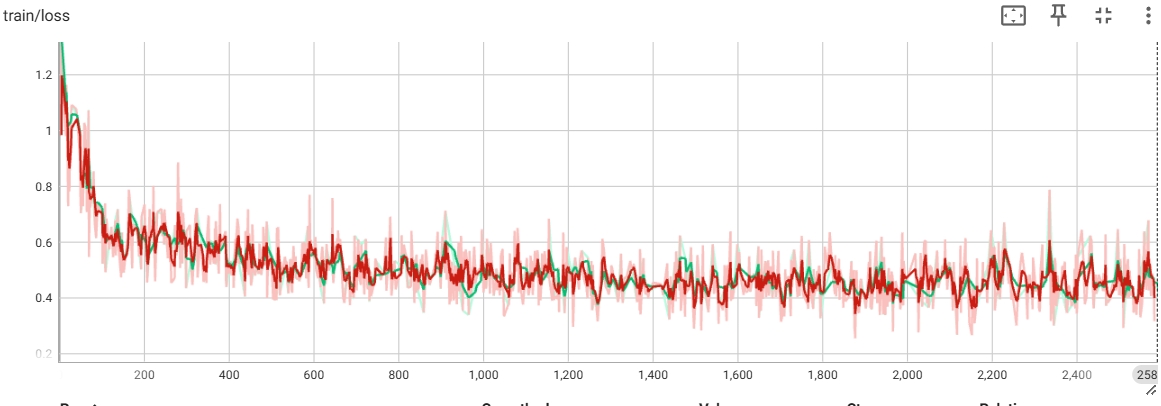
asserts/loss.jpg
0 → 100644
{kind=link}
131 KB
{kind=link}
79.6 KB
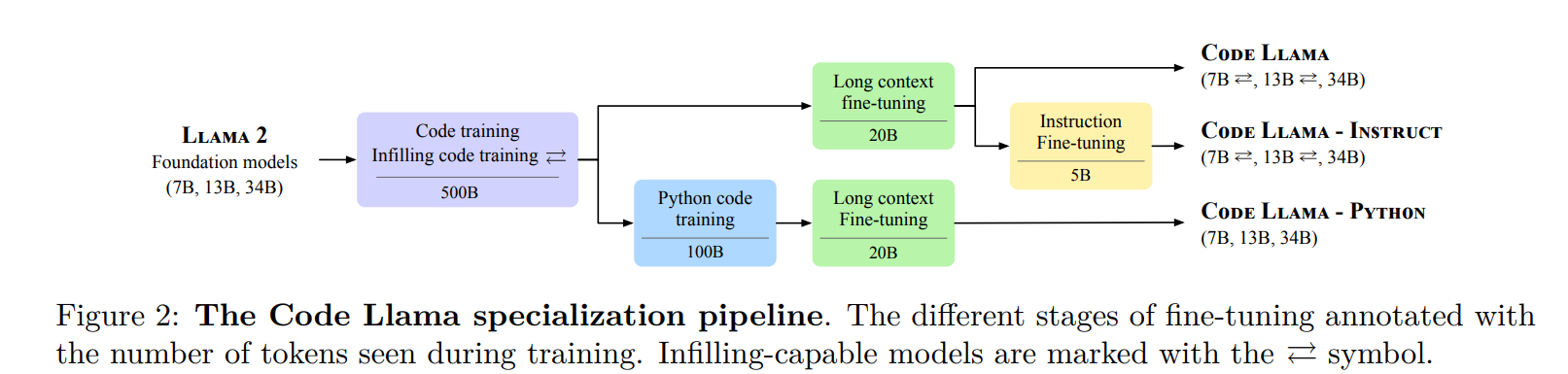
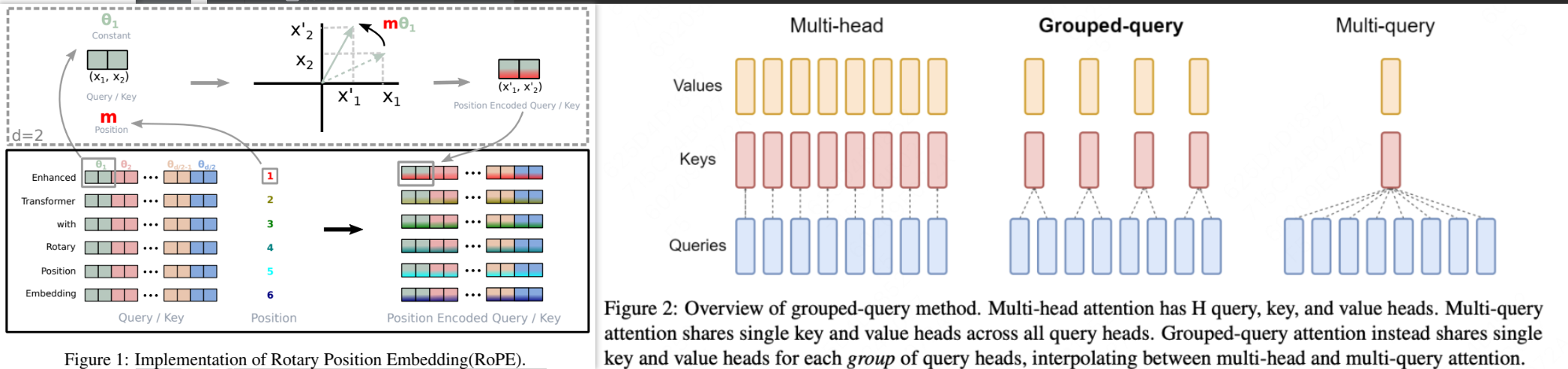
asserts/model_blocks.png
0 → 100644
{kind=link}
270 KB
asserts/result.png
0 → 100644
{kind=link}
38 KB
docker/Dockerfile
0 → 100644
finetune.py
0 → 100644
icon.png
0 → 100644
{kind=link}
62.1 KB
inference.py
0 → 100644
lora_config.json
0 → 100644
model.properties
0 → 100644
requirements.txt
0 → 100644
| #torch>=2.0 | ||
| #tokenizers>=0.14.0 | ||
| #transformers==4.35.0 | ||
| #accelerate | ||
| #deepspeed==0.12.2 | ||
| sympy==1.12 | ||
| pebble | ||
| timeout-decorator | ||
| accelerate | ||
| attrdict | ||
| tqdm | ||
| datasets | ||
| tensorboardX | ||
| peft |
train.sh
0 → 100644