Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
Chinese-LLaMA-Alpaca-2
Commits
2f320edb
Commit
2f320edb
authored
Jun 26, 2025
by
yangzhong
Browse files
Update README.md
parents
Changes
1
Hide whitespace changes
Inline
Side-by-side
Showing
1 changed file
with
198 additions
and
0 deletions
+198
-0
README.md
README.md
+198
-0
No files found.
README.md
0 → 100644
View file @
2f320edb
# Chinese-LLaMA-Alpaca-2
## 论文
## Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca
https://arxiv.org/pdf/2304.08177v1
## 模型结构
Chinese-LLaMA-Alpaca-2模型是由哈尔滨工业大学讯飞联合实验室研发的一款针对中文语言处理的大型预训练模型。该模型采用了Transformer架构,拥有数十亿级别的参数,通过对大量中文语料库进行训练,获得了强大的语言理解和生成能力。Chinese-LLaMA-Alpaca-2模型可以应用于文本分类、文本生成、机器翻译、问答系统等多个领域,为中文NLP任务提供了高效、准确的解决方案。其结构如下图:
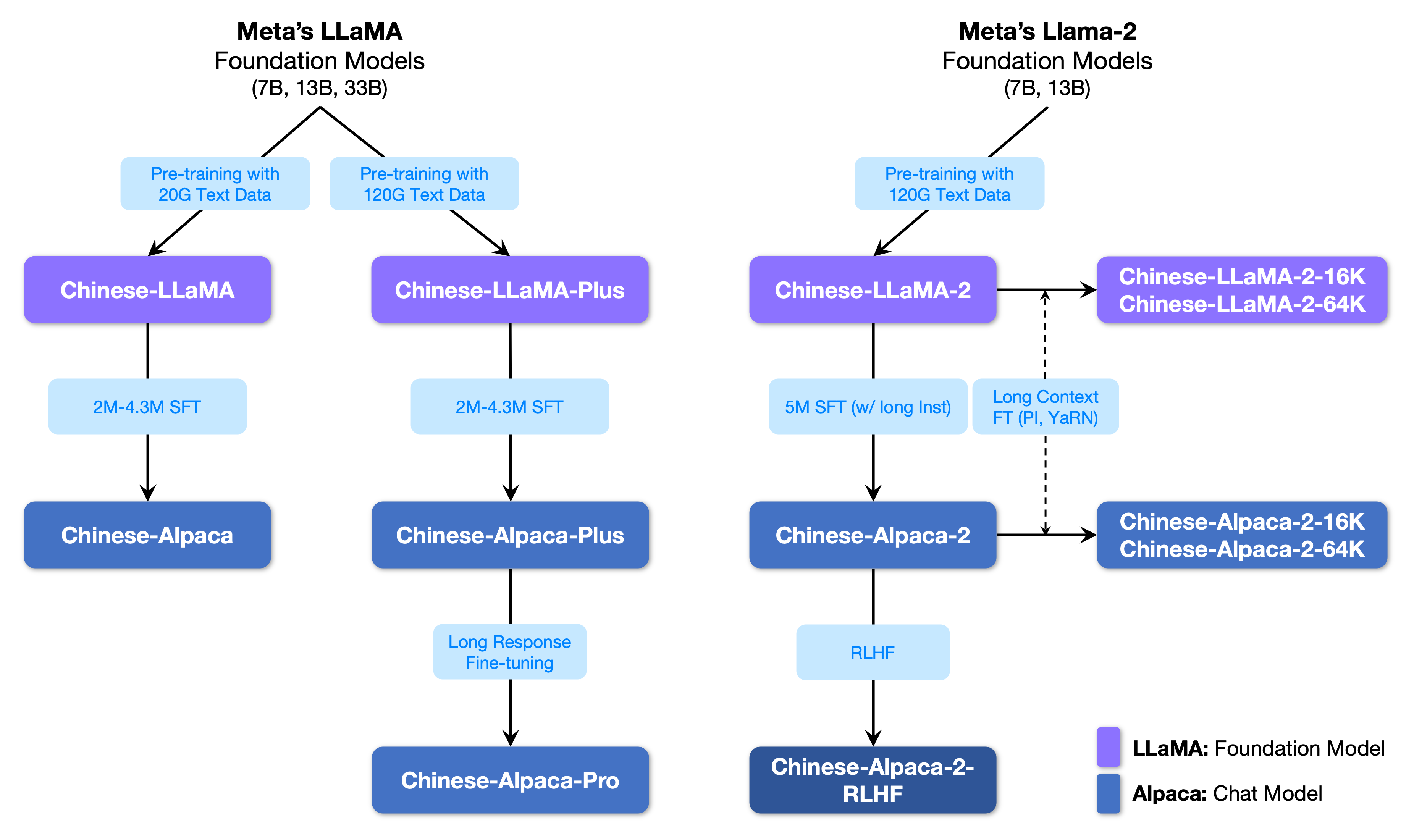
## 算法原理
Chinese-LLaMA-Alpaca-2在多个方面都有显著特色和创新:
-
优化的中文词表: 项目团队重新设计了55,296大小的新词表,进一步提升了中文字词的覆盖程度,同时统一了LLaMA和Alpaca的词表,避免了混用词表带来的问题。这一改进有望提升模型对中文文本的编解码效率。
-
采用FlashAttention-2技术: 所有模型均使用了FlashAttention-2进行训练,这是一种高效注意力机制的实现,相比一代技术具有更快的速度和更优化的显存占用。这一技术对于长上下文尤其重要,可以有效避免显存的爆炸式增长。
-
超长上下文扩展: 项目采用了基于位置插值(PI)和YaRN的超长上下文扩展技术。其中16K长上下文版模型支持16K上下文,并可通过NTK方法最高扩展至24K-32K;64K长上下文版模型则支持高达64K的上下文长度。项目还设计了方便的自适应经验公式,降低了使用难度。
-
简化的双语系统提示语: Alpaca-2系列模型简化了系统提示语,同时遵循Llama-2-Chat指令模板,以便更好地适配相关生态。
-
人类偏好对齐: 项目推出了Alpaca-2-RLHF系列模型,通过基于人类反馈的强化学习(RLHF)实验,显著提升了模型传递正确价值观的能力。
## 环境配置
### Docker(方法一)
```
在光源可拉取docker镜像:
docker pull image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.3-py3.10-rc1
创建并启动容器:
docker run -it --network=host --name=dtk24043_torch21_py310_ubuntu -v /opt/hyhal:/opt/hyhal:ro -v /usr/local/hyhal:/usr/local/hyhal:ro --privileged -v /public/opendas/DL_DATA:/dataset:ro --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.1.0-ubuntu20.04-dtk24.04.3-py3.10-rc1
docker exec -it dtk24043_torch21_py310_ubuntu /bin/bash
安装依赖包:
cd chinese-llama-alpaca-2/
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
### Dockerfile(方法二)
```
docker build --no-cache -t chinese-llama-alpaca-2:latest .
docker run -dit --network=host --name=chinese-llama-alpaca-2 --privileged --device=/dev/kfd --device=/dev/dri --ipc=host --shm-size=16G --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined -u root --ulimit stack=-1:-1 --ulimit memlock=-1:-1 -v /opt/hyhal/:/opt/hyhal/:ro -v /usr/local/hyhal:/usr/local/hyhal:ro chinese-llama-alpaca-2:latest
docker exec -it chinese-llama-alpaca-2 /bin/bash
安装依赖包:
cd chinese-llama-alpaca-2/
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
# 测试torch是否可用cuda
import torch
print(torch.cuda.is_available())
```
### Anaconda(方法三)
```
1.创建conda虚拟环境:
conda create -n chinese-llama-alpaca-2 python=3.10
2.关于本项目DCU显卡所需的工具包、深度学习库等均可从光合开发者社区下载安装:https://developer.hpccube.com/tool/
DTK驱动:dtk24.04.3
python:python3.10
torch:2.1.0
Tips:以上DTK、python、torch等DCU相关工具包,版本需要严格一一对应,torch2.1或2.3或2.4都可以
3.其它非特殊库参照requirements.txt安装
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
```
## 数据集
指令精调阶段使用了以下数据,其中7B模型约2M数据、13B模型约3M数据。基本构成如下:
| 数据 | 量级 | 来源 | 说明 |
| ---------------- | ---- | ------------------------------------------------------------ | ----------------------------------------------------- |
| 中英翻译数据 | 500K |
[
外部链接
](
https://github.com/brightmart/nlp_chinese_corpus#5翻译语料translation2019zh
)
| 在原数据集的基础上进行了采样+规则筛选 |
| pCLUE数据 | 300K |
[
外部链接
](
https://github.com/CLUEbenchmark/pCLUE
)
| 在原数据集的基础上进行了采样+规则筛选 |
| Alpaca数据(英) | 50K |
[
外部链接
](
https://github.com/tatsu-lab/stanford_alpaca
)
| 斯坦福原版Alpaca训练数据 |
| Alpaca数据(中) | 50K |
**[本地链接](https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/data)**
| 本项目使用ChatGPT接口将英文版翻译为中文(筛掉一部分) |
下载好的数据集放到
`./dataset`
目录下
数据集快速下载中心:
[
SCNet AIDatasets
](
http://113.200.138.88:18080/aidatasets
)
训练数据目录结构如下:
```
dataset
|
alpaca_data_zh_51k.json pt_sample_data.txt
```
## 训练
修改配置文件,进入项目的
`scripts/training`
目录,
`run_pt.sh`
的内容如下:
```
lr=2e-4
lora_rank=64
lora_alpha=128
lora_trainable="q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj"
modules_to_save="embed_tokens,lm_head"
lora_dropout=0.05
pretrained_model="/Chinese-LLaMA-Alpaca-2/pre_model" # 预训练模型路径
chinese_tokenizer_path="/Chinese-LLaMA-Alpaca-2/scripts/tokenizer/tokenizer.model"
dataset_dir="/Chinese-LLaMA-Alpaca-2/dataset" # 数据集路径
data_cache="/Chinese-LLaMA-Alpaca-2/tmp"
per_device_train_batch_size=1
gradient_accumulation_steps=8
block_size=512
output_dir="/Chinese-LLaMA-Alpaca-2/output" # 保存训练模型
deepspeed_config_file="./ds_zero2_no_offload.json"
########启动命令########
torchrun --nnodes 1 --nproc_per_node 8 --master_port=25001 run_clm_pt_with_peft.py \
--deepspeed ${deepspeed_config_file} \
--model_name_or_path ${pretrained_model} \
--tokenizer_name_or_path ${chinese_tokenizer_path} \
--dataset_dir ${dataset_dir} \
--data_cache_dir ${data_cache} \
--validation_split_percentage 0.001 \
--per_device_train_batch_size ${per_device_train_batch_size} \
--do_train \
--seed $RANDOM \
--fp16 \
--num_train_epochs 1 \
--lr_scheduler_type cosine \
--learning_rate ${lr} \
--warmup_ratio 0.05 \
--weight_decay 0.01 \
--logging_strategy steps \
--logging_steps 10 \
--save_strategy steps \
--save_total_limit 3 \
--save_steps 200 \
--gradient_accumulation_steps ${gradient_accumulation_steps} \
--preprocessing_num_workers 8 \
--block_size ${block_size} \
--output_dir ${output_dir} \
--overwrite_output_dir \
--ddp_timeout 30000 \
--logging_first_step True \
--lora_rank ${lora_rank} \
--lora_alpha ${lora_alpha} \
--trainable ${lora_trainable} \
--lora_dropout ${lora_dropout} \
--modules_to_save ${modules_to_save} \
--torch_dtype float16 \
--load_in_kbits 16 \
--save_safetensors False \
--gradient_checkpointing \
--ddp_find_unused_parameters False
```
部分参数的解释如下:
-
`--dataset_dir`
: 预训练数据的目录,可包含多个以
`txt`
结尾的纯文本文件
-
`--data_cache_dir`
: 指定一个存放数据缓存文件的目录
-
`--use_flash_attention_2`
: 启用FlashAttention-2加速训练
-
`--load_in_kbits`
: 可选择参数为16/8/4,即使用fp16或8bit/4bit量化进行模型训练,默认fp16训练。
这里列出的其他训练相关超参数,尤其是学习率以及和total batch size大小相关参数仅供参考。请在实际使用时根据数据情况以及硬件条件进行配置。
### 单机多卡
>假设你的设备有N (N>1) 张显卡:
-
单机N卡启动训练(DDP),运行
`bash run_pt.sh`
进行指令精调,默认使用8卡,可以在脚本中--nproc_per_node参数指定卡数。
```
bash run_pt.sh
```
## result
### 应用场景
### 算法类别
对话问答
### 热点应用行业
医疗,教育,科研,金融
## 源码仓库及问题反馈
-
https://developer.sourcefind.cn/codes/modelzoo/chinese-llama-alpaca-2
## 参考资料
-
https://github.com/ymcui/Chinese-LLaMA-Alpaca-2
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment
