
re-organize the code
Showing
Dockerfile
0 → 100644
ptuning/evaluate_ptuning.sh
0 → 100644
{kind=link}

298 KB
{kind=link}

314 KB
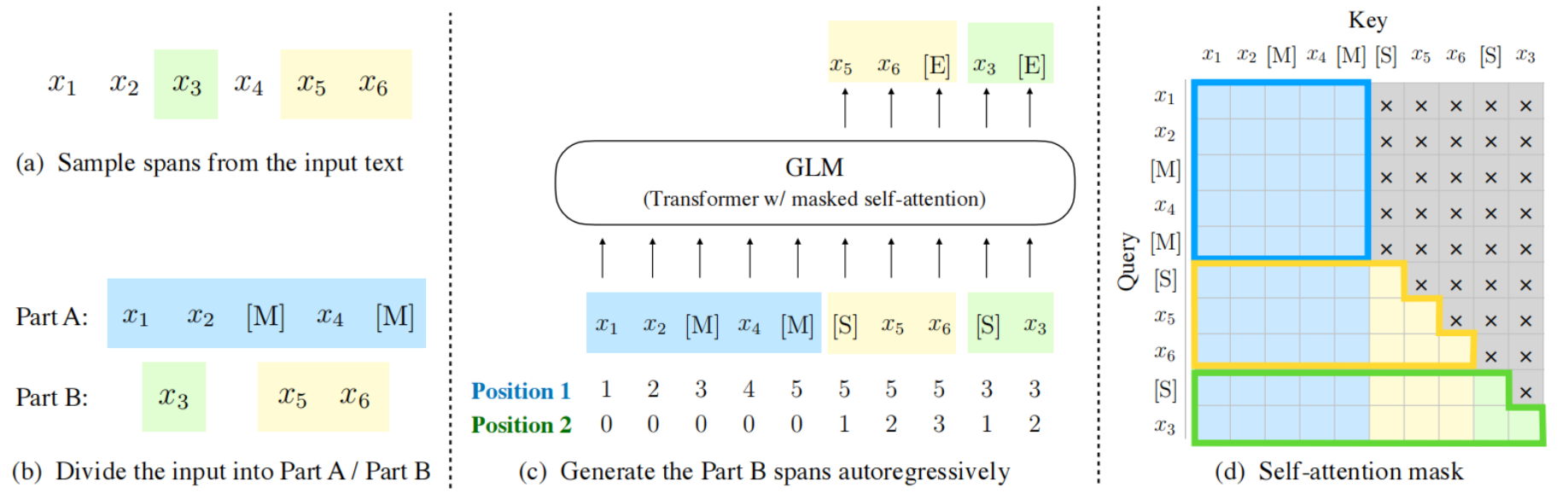
ptuning/media/GLM.png
0 → 100644
{kind=link}
261 KB
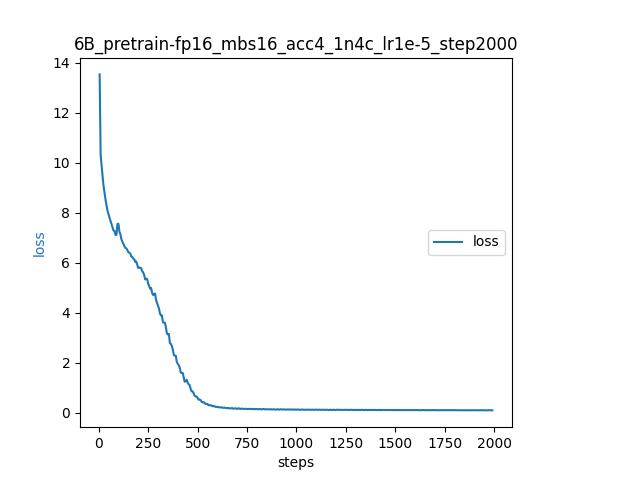
ptuning/media/pretrain.jpeg
0 → 100644
{kind=link}
20.2 KB
ptuning/ptuning_train.sh
0 → 100644
ptuning/slurm_scripts/run.sh
0 → 100644
| protobuf | protobuf | ||
| transformers==4.27.1 | transformers==4.28.0 | ||
| gradio | accelerate | ||
| mdtex2html | |||
| sentencepiece | sentencepiece | ||
| accelerate | mdtex2html | ||
| \ No newline at end of file | gradio | ||
| rouge_chinese | |||
| nltk | |||
| jieba | |||
| datasets | |||
| protobuf | |||
| \ No newline at end of file |