
First Commit.
parents
Showing
.gitignore
0 → 100644
{kind=link}
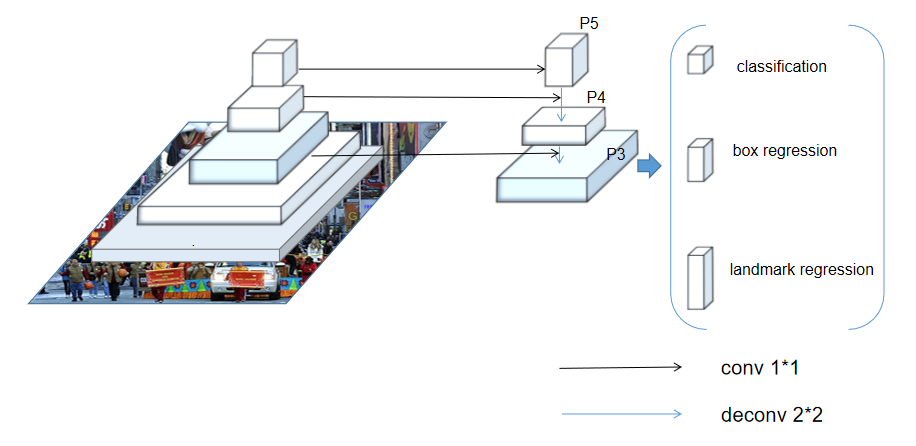
104 KB
README.md
0 → 100644
TensorRT/_init_paths.py
0 → 100644
TensorRT/convert2onnx.py
0 → 100644
TensorRT/demo_tensorrt.py
0 → 100644
TensorRT/tensorrt_model.py
0 → 100644
datasets.png
0 → 100644
{kind=link}
28.6 KB
docker/Dockerfile
0 → 100644
draw_img.jpg
0 → 100644
{kind=link}

361 KB
evaluate/README.md
0 → 100644
evaluate/box_overlaps.c
0 → 100644
This diff is collapsed.
evaluate/box_overlaps.pyx
0 → 100644
evaluate/evaluation.py
0 → 100644
File added
File added
File added
File added
evaluate/setup.py
0 → 100644