"vscode:/vscode.git/clone" did not exist on "76cdc527dfc879a3fe1f7c1c5dc41380a612e8e7"

Merge branch 'develop' into 'master'
Develop See merge request !1
Showing
3rdParty/InstallRBuild.sh
0 → 100644
File added
File added
File added
File added
File added
File added
CMakeLists.txt
0 → 100644
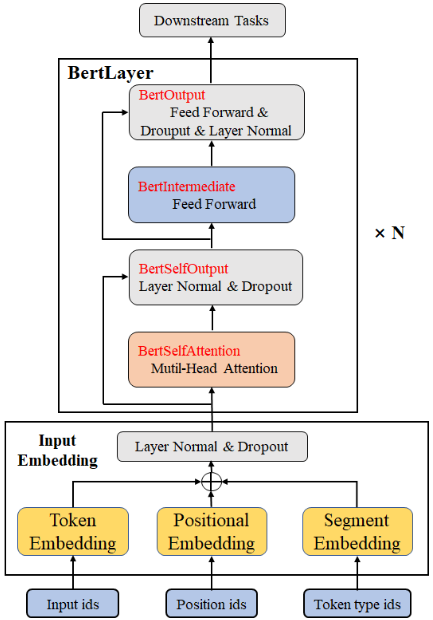
Doc/Images/Bert_01.png
0 → 100644
{kind=link}
62.8 KB
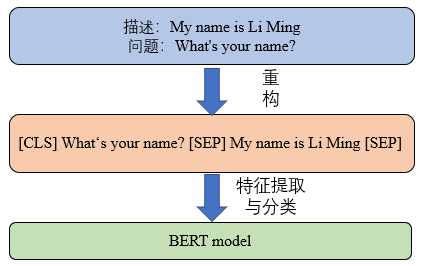
Doc/Images/Bert_02.png
0 → 100644
{kind=link}
10.2 KB
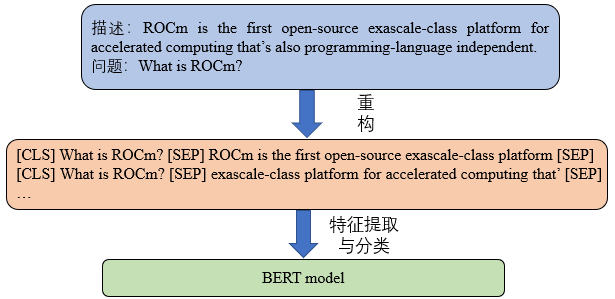
Doc/Images/Bert_03.png
0 → 100644
{kind=link}
19 KB
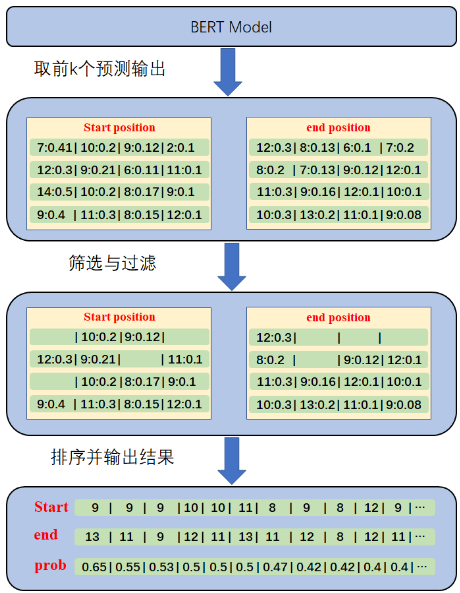
Doc/Images/Bert_04.png
0 → 100644
{kind=link}
74.7 KB
Doc/Images/Bert_05.png
0 → 100644
{kind=link}

15.2 KB
Doc/Images/Bert_06.png
0 → 100644
{kind=link}

26.7 KB
Doc/Tutorial_Cpp/Bert.md
0 → 100644
Doc/Tutorial_Python/Bert.md
0 → 100644