Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
ModelZoo
Baichuan-13B_fastllm
Commits
67472ca4
Commit
67472ca4
authored
Nov 01, 2023
by
zhouxiang
Browse files
修改readme
parent
c36a00b4
Changes
4
Hide whitespace changes
Inline
Side-by-side
Showing
4 changed files
with
6 additions
and
2 deletions
+6
-2
README.md
README.md
+6
-2
doc/baichuan-13b.gif
doc/baichuan-13b.gif
+0
-0
doc/transformer.jpg
doc/transformer.jpg
+0
-0
doc/transformer.png
doc/transformer.png
+0
-0
No files found.
README.md
View file @
67472ca4
...
@@ -12,6 +12,8 @@ Baichuan-13B是由百川智能继Baichuan-7B之后开发的包含130亿参数模
...
@@ -12,6 +12,8 @@ Baichuan-13B是由百川智能继Baichuan-7B之后开发的包含130亿参数模
Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿Tokens 的高质量语料训练。
Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿Tokens 的高质量语料训练。

模型具体参数:
模型具体参数:
| 模型名称 | 隐含层维度 | 层数 | 头数 | 词表大小 | 位置编码 | 最大序列长度 |
| 模型名称 | 隐含层维度 | 层数 | 头数 | 词表大小 | 位置编码 | 最大序列长度 |
...
@@ -20,7 +22,9 @@ Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6
...
@@ -20,7 +22,9 @@ Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6
| Baichuan2-13B | 5,120 | 40 | 40 | 125696 | ALiBi | 4096 |
| Baichuan2-13B | 5,120 | 40 | 40 | 125696 | ALiBi | 4096 |
## 算法原理
## 算法原理
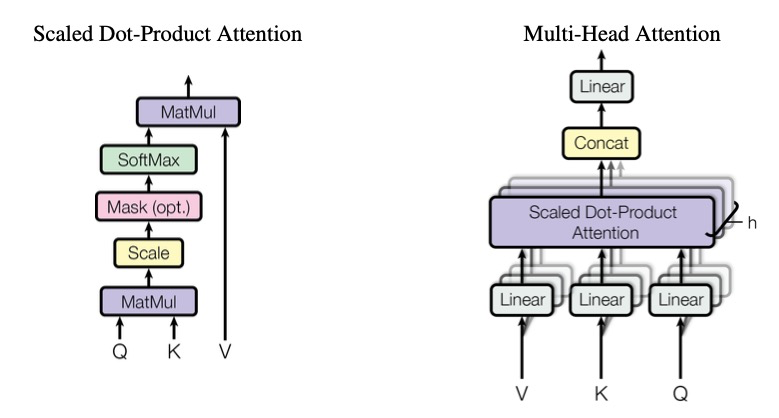
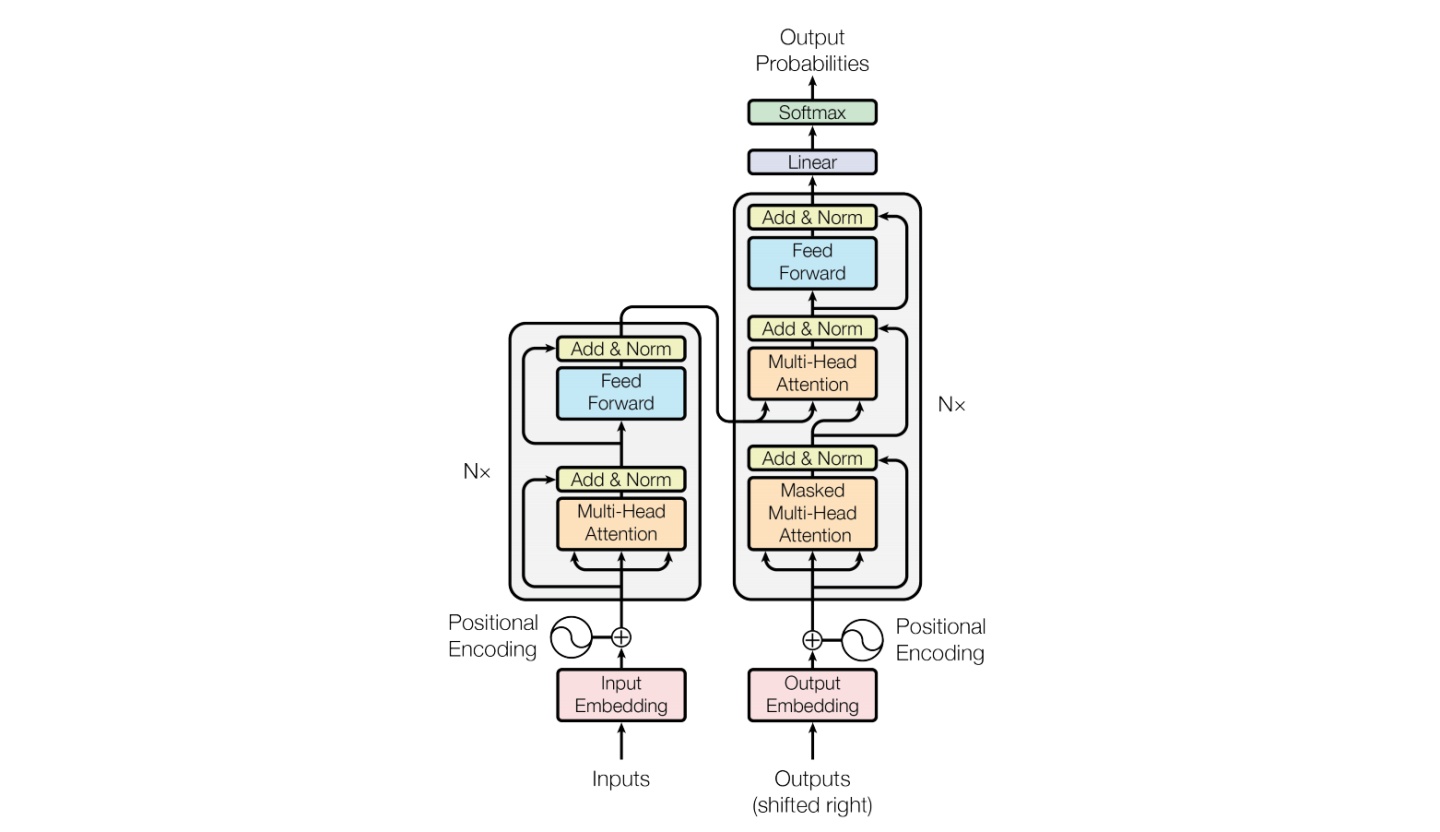
Baichuan整体模型基于标准的Transformer结构,采用了和LLaMA一样的模型设计。其中,Baichuan-7B在结构上采用Rotary Embedding位置编码方案、SwiGLU激活函数、基于RMSNorm的Pre-Normalization。Baichuan-13B使用了ALiBi线性偏置技术,相对于Rotary Embedding计算量更小,对推理性能有显著提升
Baichuan整体模型基于标准的Transformer结构,采用了和LLaMA一样的模型设计。其中,Baichuan-7B在结构上采用Rotary Embedding位置编码方案、SwiGLU激活函数、基于RMSNorm的Pre-Normalization。Baichuan-13B使用了ALiBi线性偏置技术,相对于Rotary Embedding计算量更小,对推理性能有显著提升.

## 环境配置
## 环境配置
...
@@ -113,7 +117,7 @@ chmod +x benchmark
...
@@ -113,7 +117,7 @@ chmod +x benchmark
## result
## result


### 精度
### 精度
...
...
baichuan-13b.gif
→
doc/
baichuan-13b.gif
View file @
67472ca4
File moved
doc/transformer.jpg
0 → 100644
View file @
67472ca4
87.9 KB
doc/transformer.png
0 → 100644
View file @
67472ca4
112 KB
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}
{kind=link}