"csrc/git@developer.sourcefind.cn:jerrrrry/infinilm.git" did not exist on "e76bb324ac048e7c91f165610cbec151791dbb62"

bagel
Showing
.gitignore
0 → 100644
Dockerfile
0 → 100644
EVAL.md
0 → 100644
LICENSE
0 → 100644
README.md
0 → 100644
README_official.md
0 → 100644
TRAIN.md
0 → 100644
app.py
0 → 100644
This diff is collapsed.
assets/arch.png
0 → 100644
{kind=link}
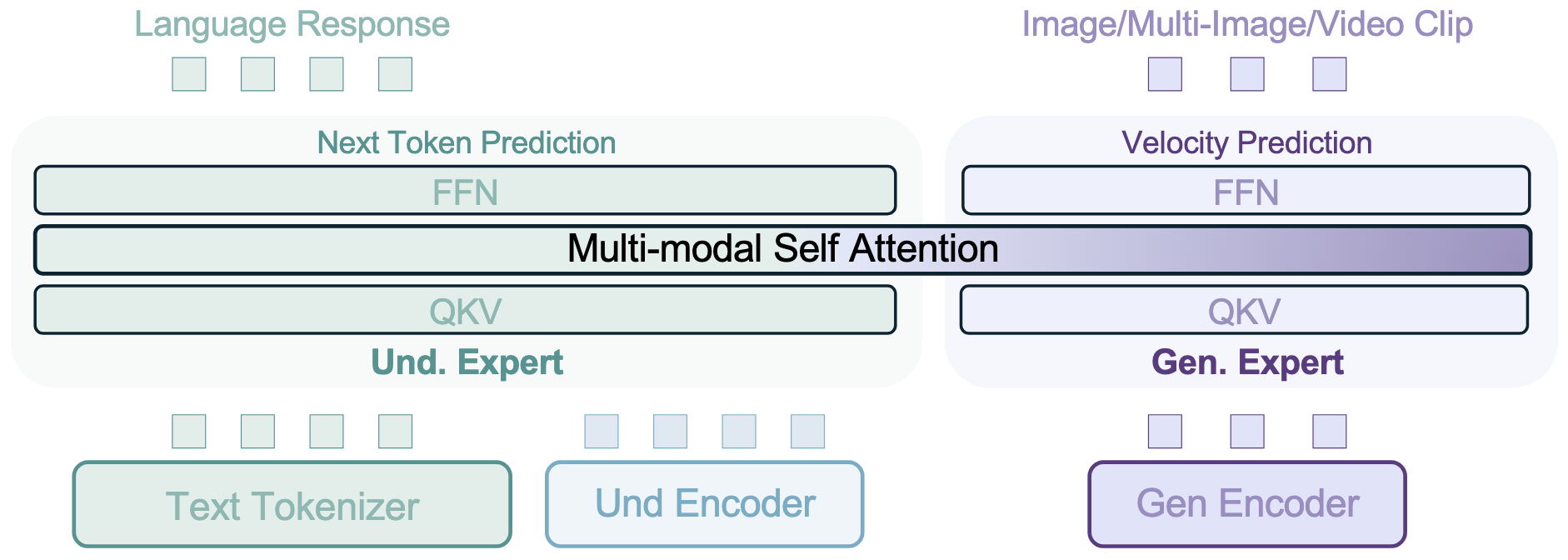
164 KB
assets/emerging_curves.png
0 → 100644
{kind=link}
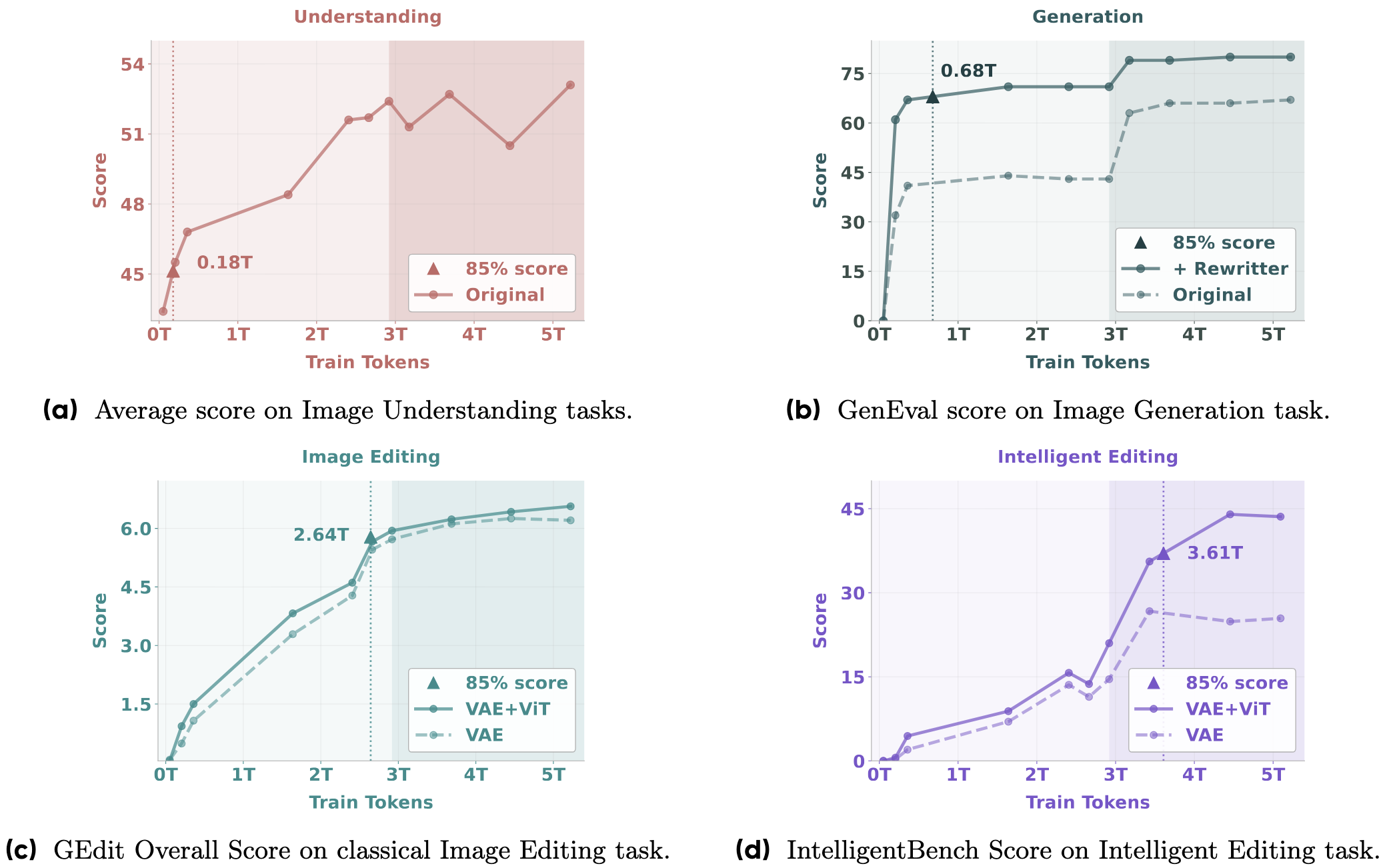
364 KB
assets/teaser.webp
0 → 100644
{kind=link}

1.05 MB
data/__init__.py
0 → 100644
data/configs/example.yaml
0 → 100644
data/data_utils.py
0 → 100644
data/dataset_base.py
0 → 100644
This diff is collapsed.
data/dataset_info.py
0 → 100644