
v1.0
Showing
allamo/torch_utils.py
0 → 100644
allamo/train_utils.py
0 → 100644
allamo/trainer/__init__.py
0 → 100644
allamo/trainer/base.py
0 → 100644
allamo/training_context.py
0 → 100644
assets/allamo_gradio.jpg
0 → 100644
{kind=link}
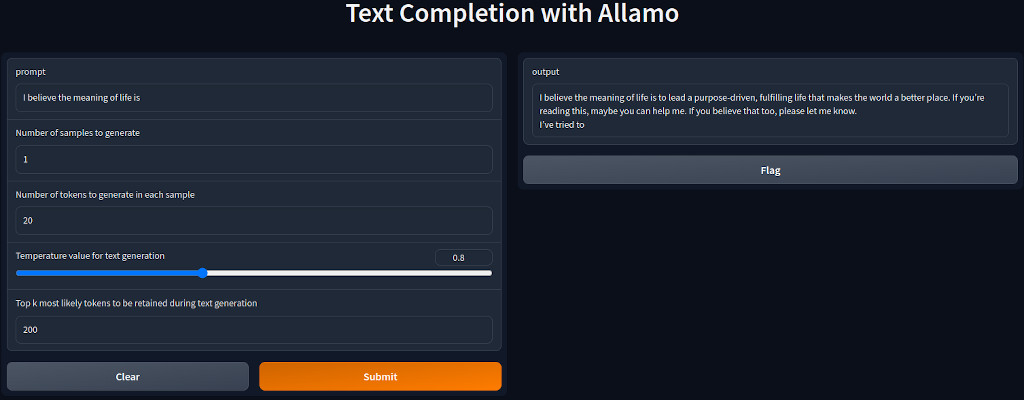
61.2 KB
assets/allamo_logo.jpg
0 → 100644
{kind=link}
23.8 KB
This diff is collapsed.
File added
File added
doc/algorithm.png
0 → 100644
{kind=link}
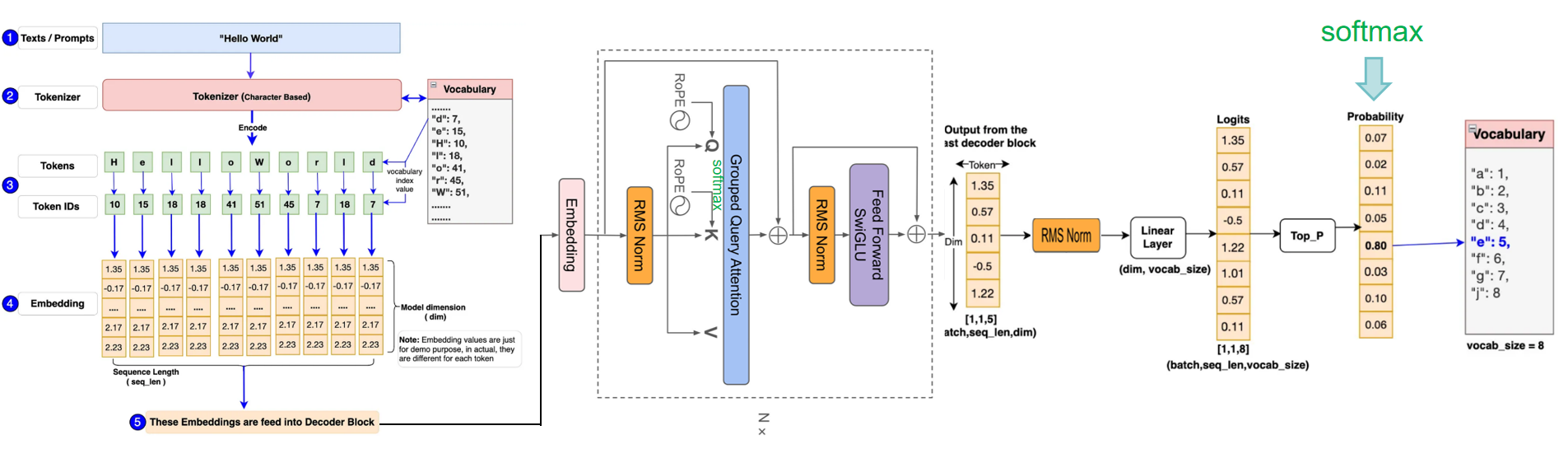
345 KB
doc/llama3.png
0 → 100644
{kind=link}
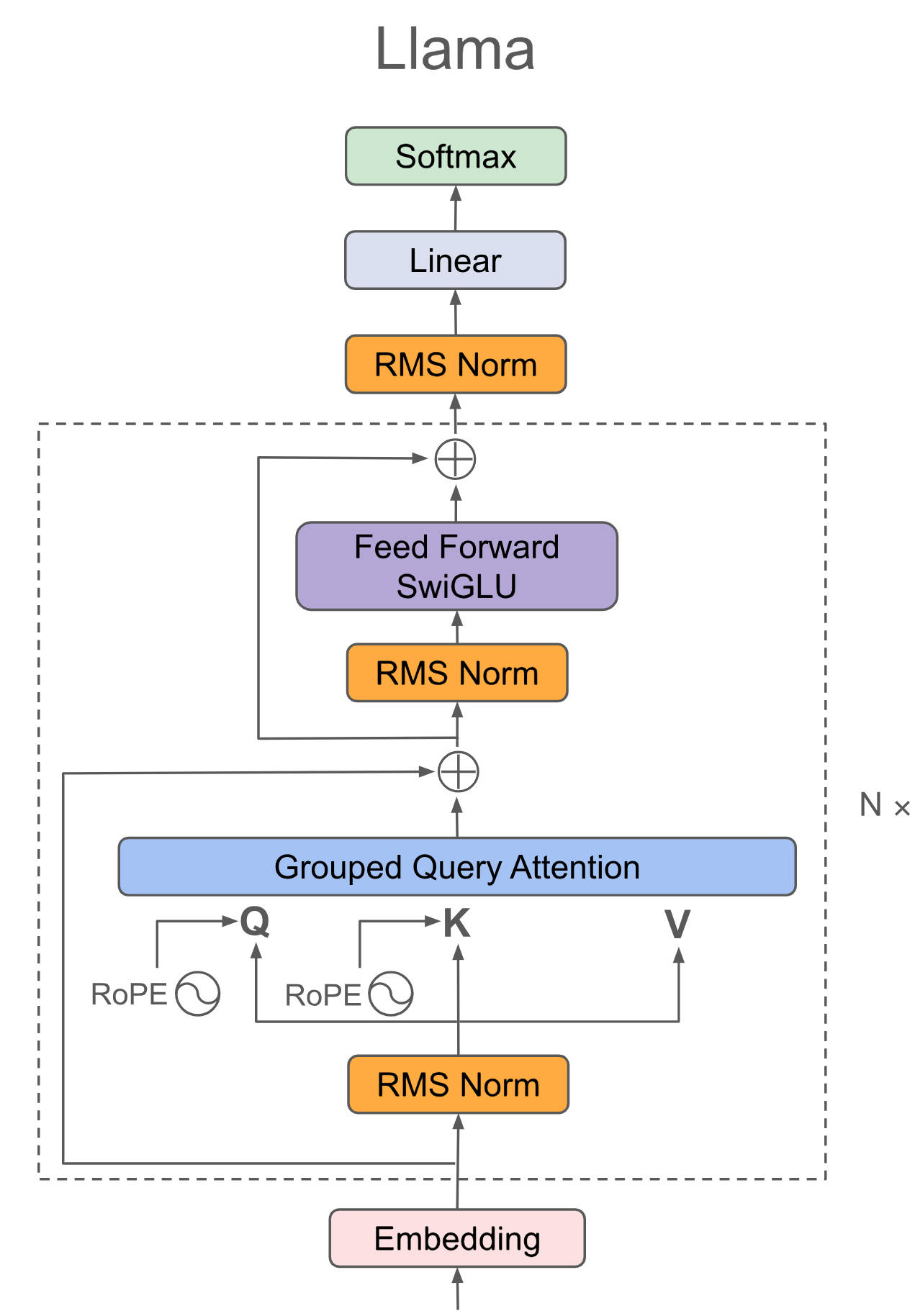
334 KB
doc/llama3_detail.png
0 → 100644
{kind=link}
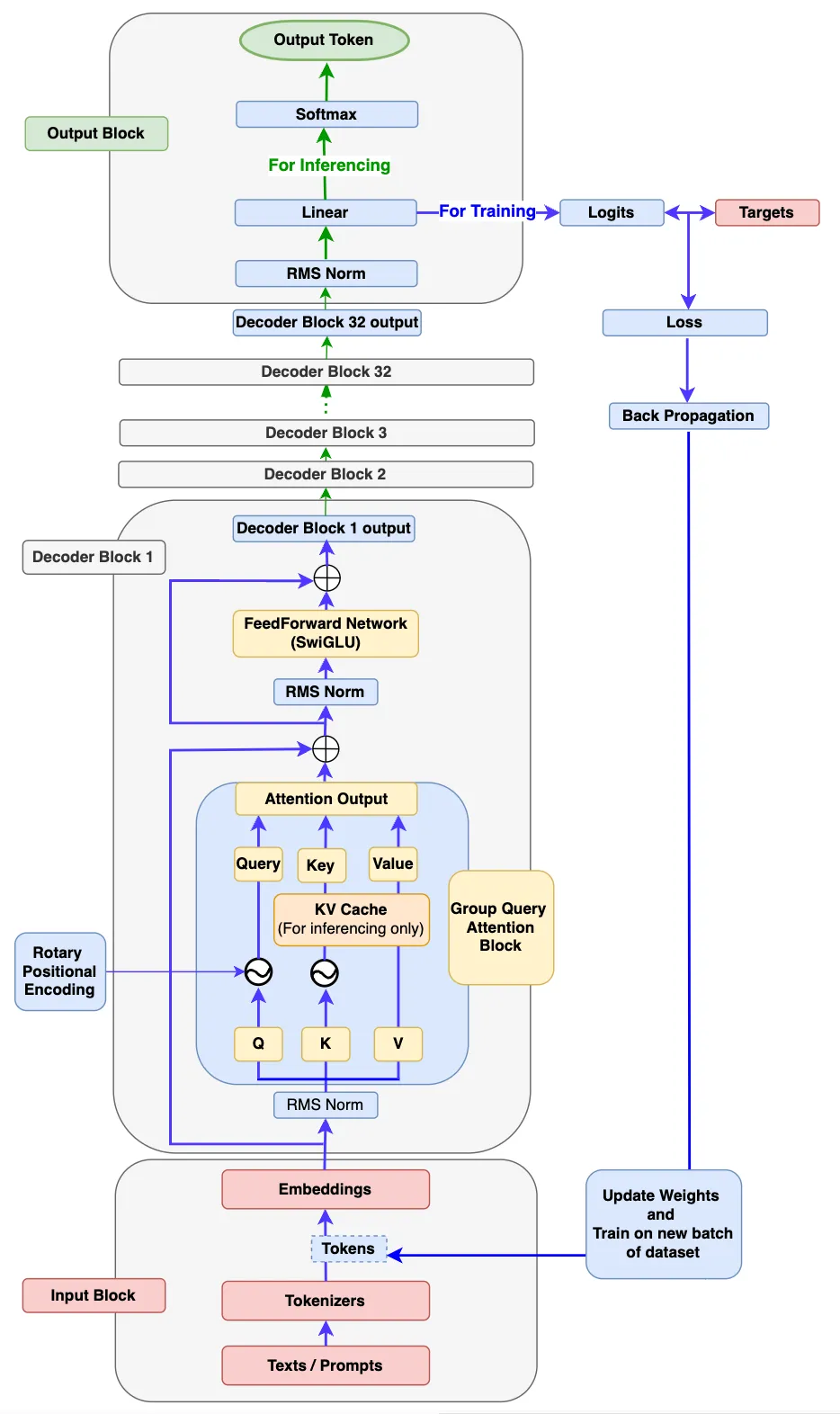
449 KB