
init model
Showing
docker/Dockerfile
0 → 100644
icon.png
0 → 100644
{kind=link}
64.4 KB
images/algorithm.png
0 → 100644
{kind=link}
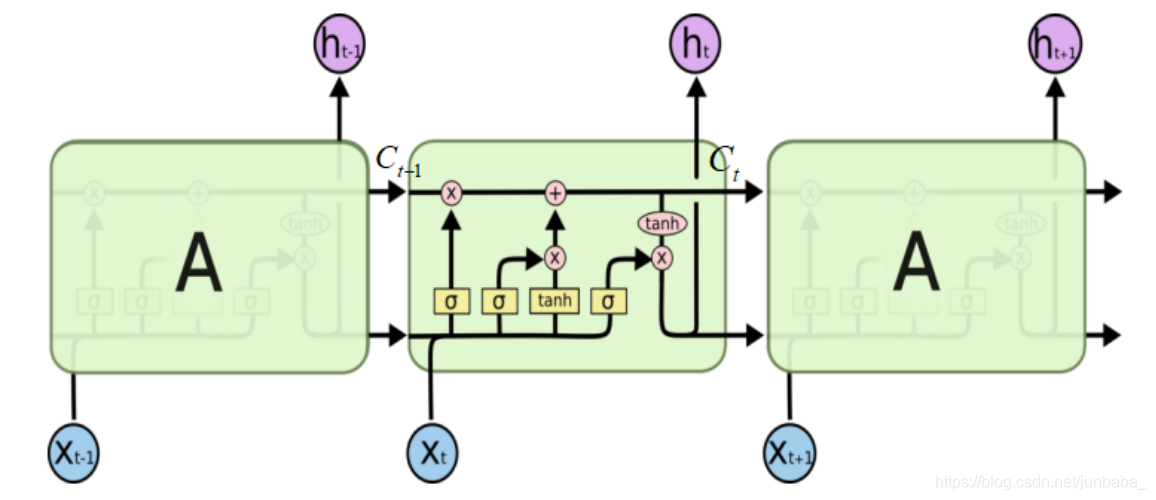
133 KB
images/architecture.png
0 → 100644
{kind=link}
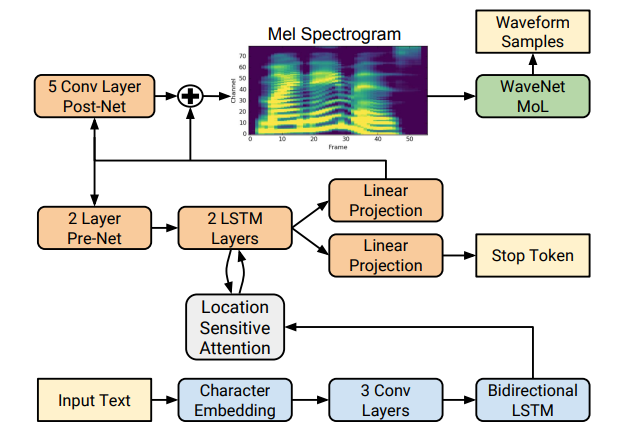
106 KB
inference.py
0 → 100644
model.properties
0 → 100644
requirements.txt
0 → 100644
| soundfile==0.12.1 | |||
| librosa==0.10.2.post1 | |||
| speechbrain==1.0.0 | |||
| hyperpyyaml>=0.0.1 | |||
| joblib>=0.14.1 | |||
| pre-commit>=2.3.0 | |||
| pygtrie>=2.1,<3.0 | |||
| tgt==1.5 | |||
| unidecode==1.3.8 | |||
| \ No newline at end of file |
res/example.wav
0 → 100644
File added
This diff is collapsed.
File added
This diff is collapsed.