
Docs: update config instructions for vLLM compatibility
Showing
images/after_fix.png
0 → 100644
{kind=link}
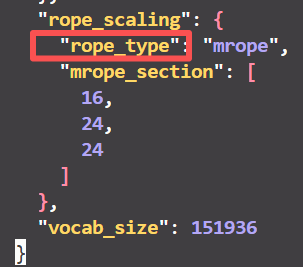
11.4 KB
images/before_fix.png
0 → 100644
{kind=link}
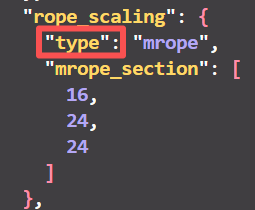
7.85 KB
images/result1.png
0 → 100644
{kind=link}
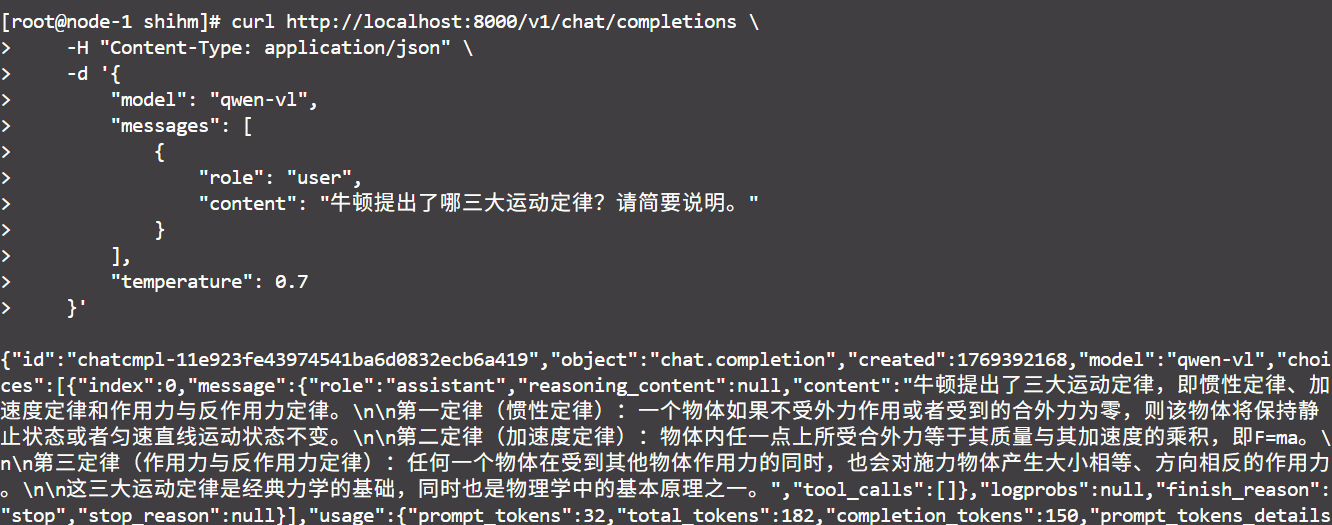
122 KB
11.4 KB
7.85 KB
122 KB