
v1.0
Showing
LICENSE
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
app.py
0 → 100644
This diff is collapsed.
app_chat.py
0 → 100644
This diff is collapsed.
app_chat.sh
0 → 100644
assets/brand.png
0 → 100644
{kind=link}

329 KB
assets/efficiency.png
0 → 100644
{kind=link}
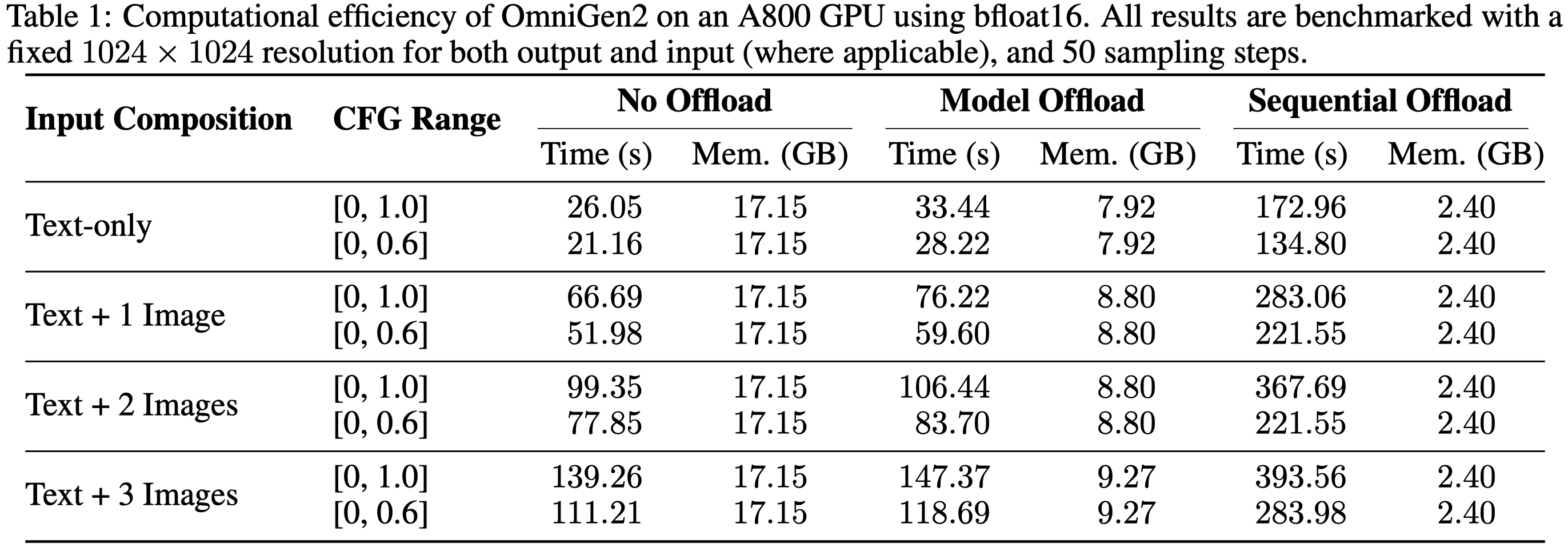
293 KB
assets/examples_edit.png
0 → 100644
{kind=link}
5.42 MB
assets/examples_subject.png
0 → 100644
{kind=link}

7.41 MB
{kind=link}

3.56 MB
{kind=link}
5.7 MB
assets/teaser.jpg
0 → 100644
{kind=link}

6.87 MB
assets/teaser.png
0 → 100644
{kind=link}

4.24 MB
convert_ckpt_to_hf_format.py
0 → 100644