
v1.0
Showing
.gitmodules
0 → 100644
LICENSE.txt
0 → 100644
README.md
0 → 100644
README_origin.md
0 → 100644
This diff is collapsed.
app.py
0 → 100644
asset/InspireMusic-24kHz.png
0 → 100644
{kind=link}
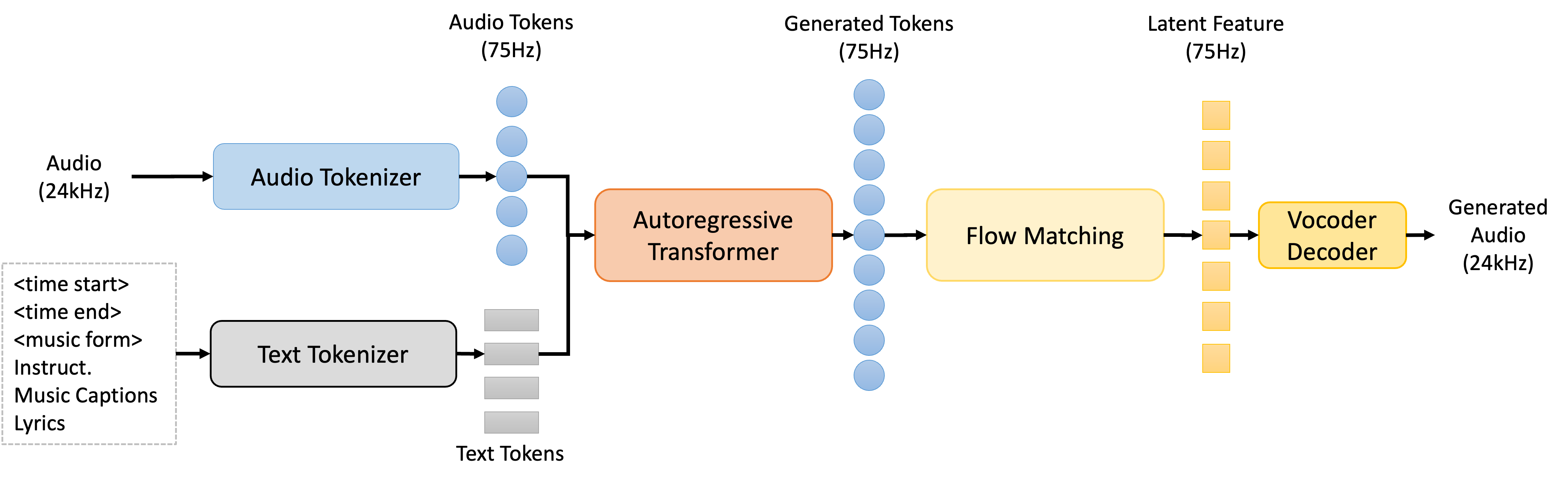
293 KB
asset/InspireMusic.png
0 → 100644
{kind=link}
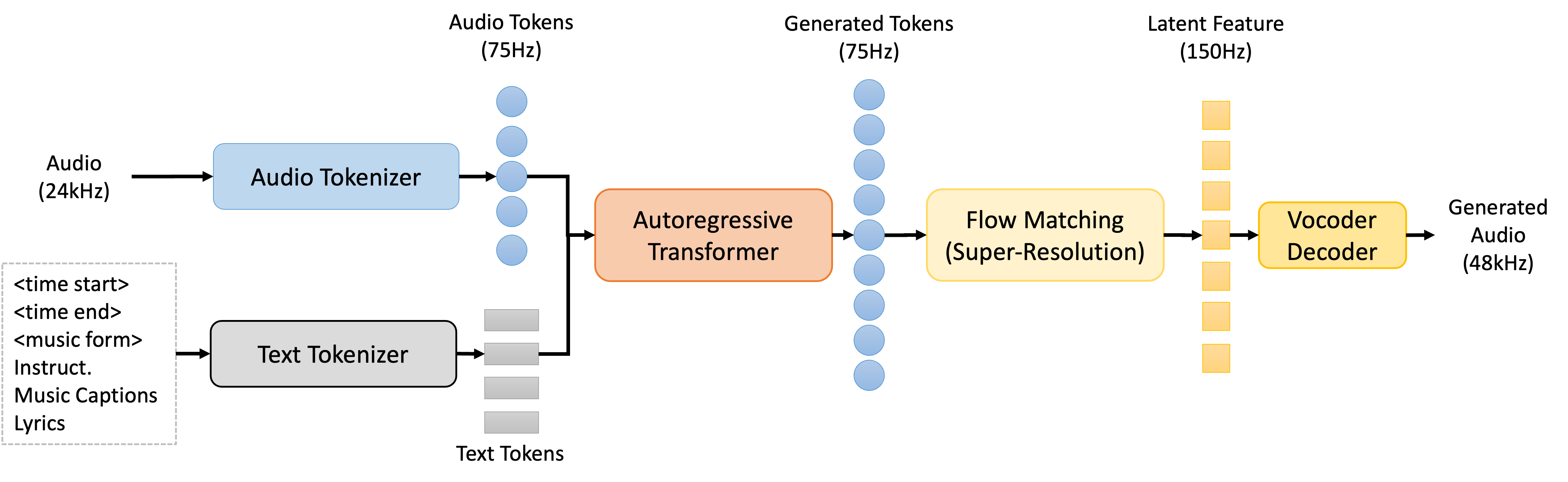
305 KB
asset/QR.jpg
0 → 100644
{kind=link}

225 KB
asset/dingding.png
0 → 100644
{kind=link}

94.1 KB
asset/dingtalk.png
0 → 100644
{kind=link}

95.8 KB
asset/logo.png
0 → 100644
{kind=link}
354 KB
doc/algorithm.png
0 → 100644
{kind=link}
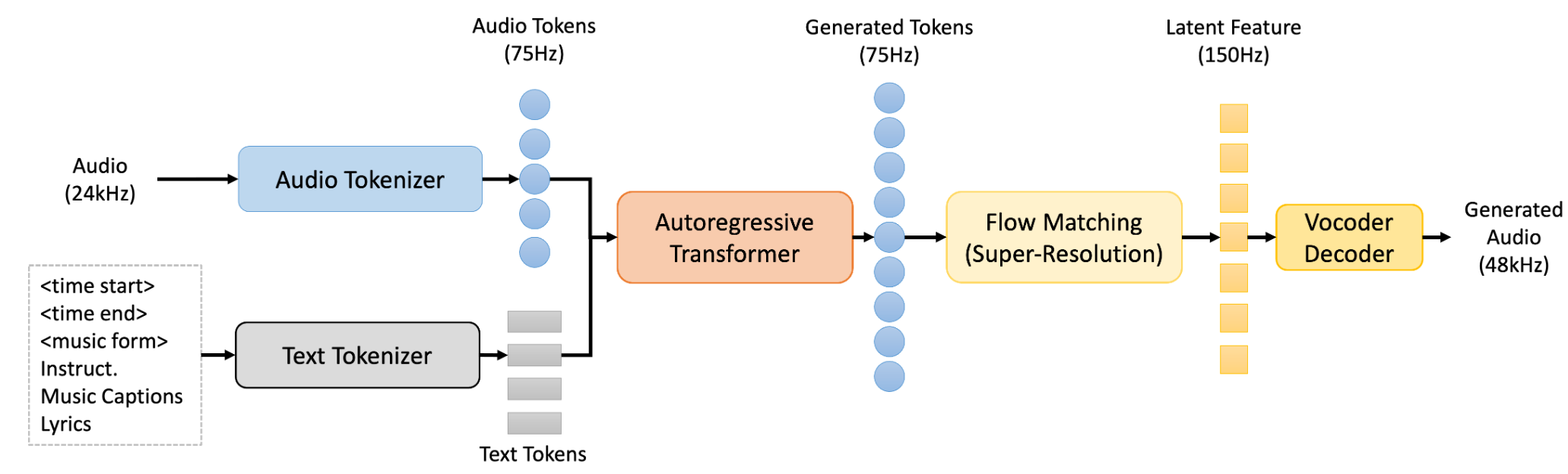
156 KB
doc/structure.png
0 → 100644
{kind=link}
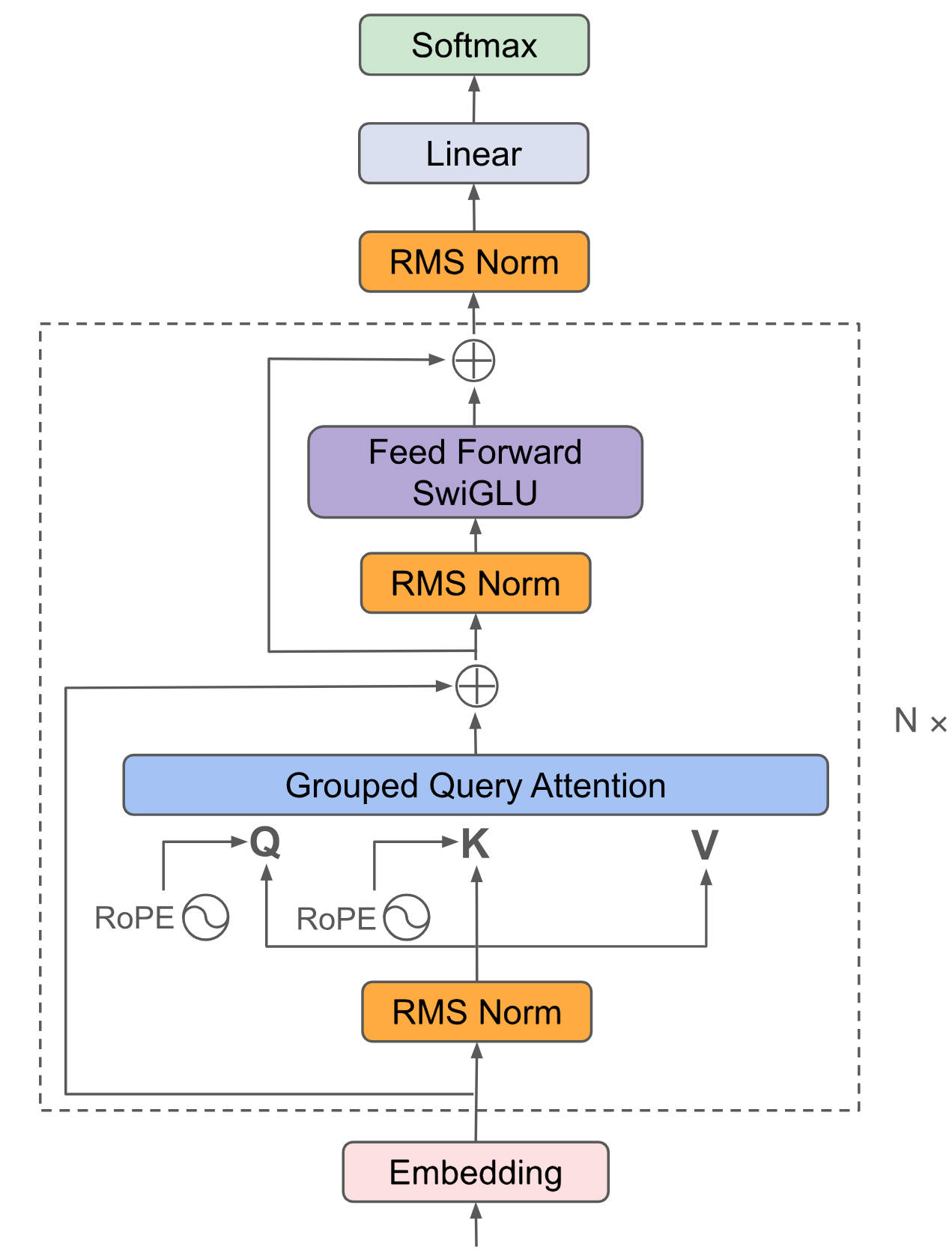
356 KB
docker/Dockerfile
0 → 100644
docker/requirements.txt
0 → 100644
docker_start.sh
0 → 100644