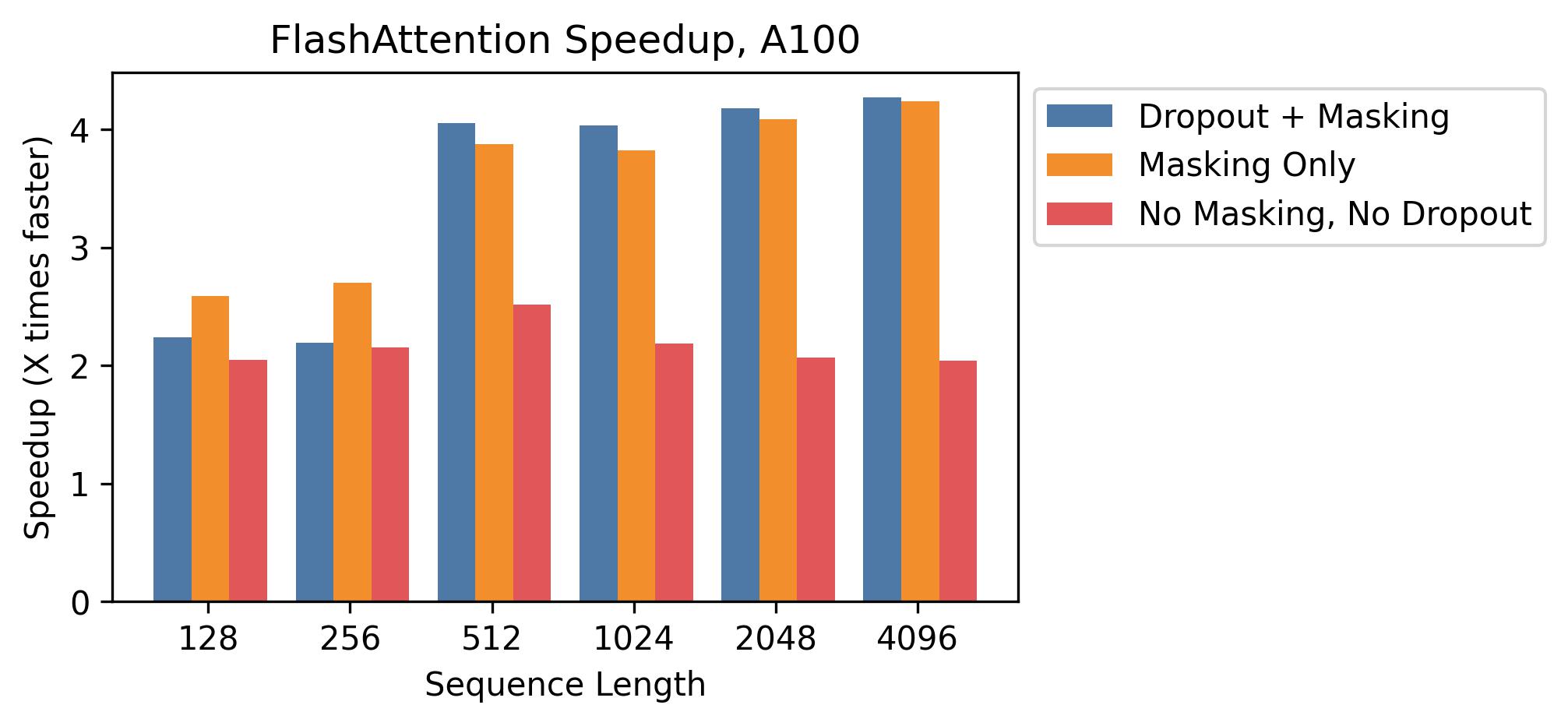
We present expected speedup (combined forward + backward pass) and memory savings from using FlashAttention against PyTorch standard attention, depending on sequence length, on different GPUs (speedup depends on memory bandwidth - we see more speedup on slower GPU memory).
We currently have benchmarks for these GPUs:
*[A100](#a100)
*[RTX 3090](#rtx-3090)
*[T4](T4)
### A100
We display FlashAttention speedup using these parameters (similar to BERT-base):
...
...
@@ -75,6 +80,21 @@ Memory savings are the same as on an A100, so we'll only show speedup here.
We see slightly higher speedups (between 2.5-4.5x) on the GTX 3090, since memory bandwidth on the GDDR6X is lower than A100 HBM (~900 GB/s vs. ~1.5 TB/s).
### T4
We again use batch size 12 with 12 attention heads.
T4 SRAM is smaller than the newer GPUs (64 KB), so we see less speedup (we need to make the block sizes smaller, so we end up doing more R/W).
This matches the IO complexity analysis from section 3.2 of [our paper](https://arxiv.org/abs/2205.14135).
T4 GPUs are commonly used for inference, so we also measure speedup on the forward pass only (note that these are not directly comparable to the graphs above):

{kind=link}
{kind=link}

{kind=link}
{kind=link}


{kind=link}

{kind=link}
