"""dropout_p should be set to 0.0 during evaluation
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in KV must be divisible by the number of heads in Q.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k: (batch_size, seqlen, nheads_k, headdim)
v: (batch_size, seqlen, nheads_k, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
Return:
out: (batch_size, seqlen, nheads, headdim).
```
```
Or, if you need more fine-grained control, you can import one of the lower-level
To see how these functions are used in a multi-head attention layer (which
functions (this is more similar to the `torch.nn.functional` style):
includes QKV projection, output projection), see the MHA [implementation](https://github.com/Dao-AILab/flash-attention/blob/main/flash_attn/modules/mha.py).
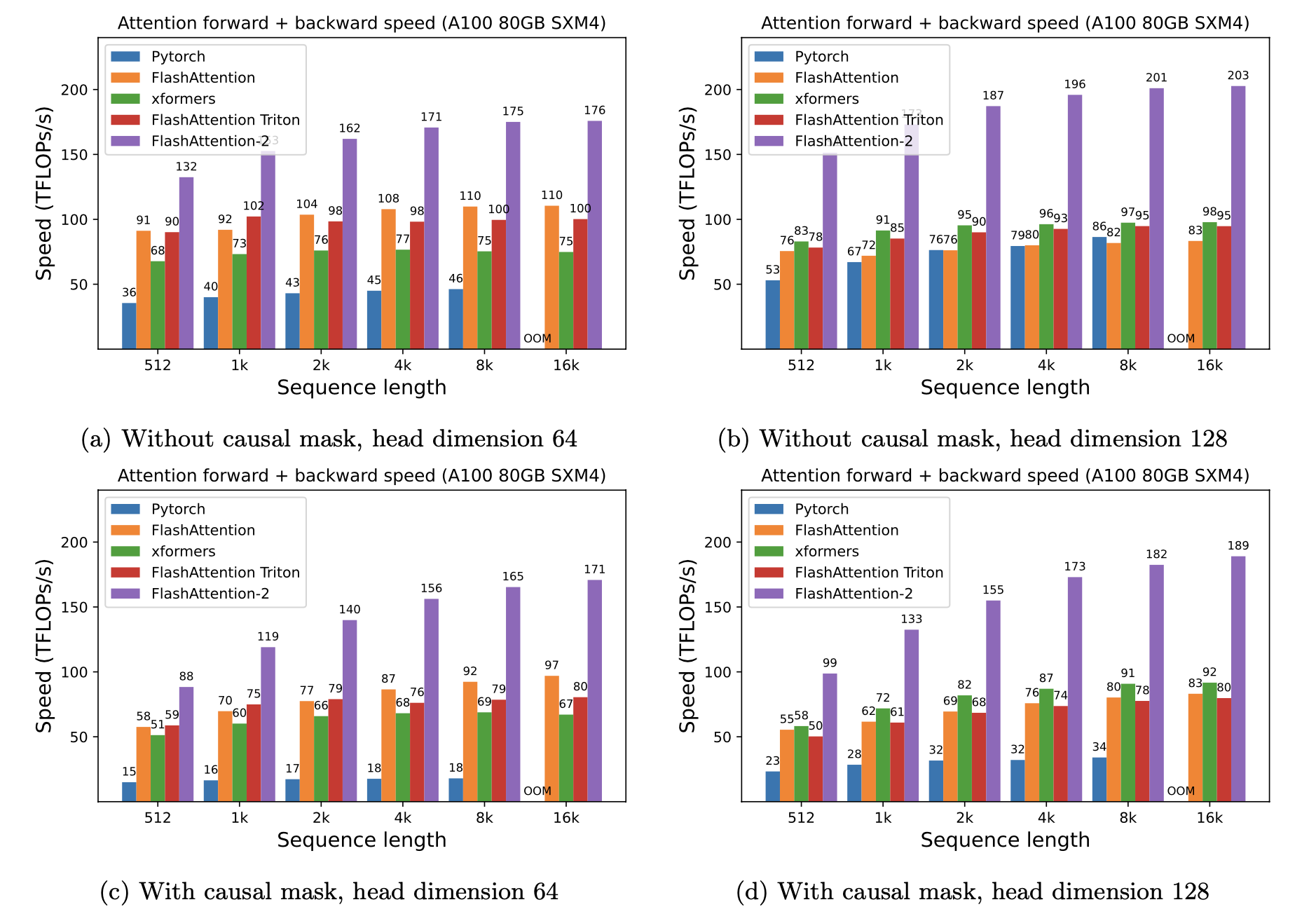
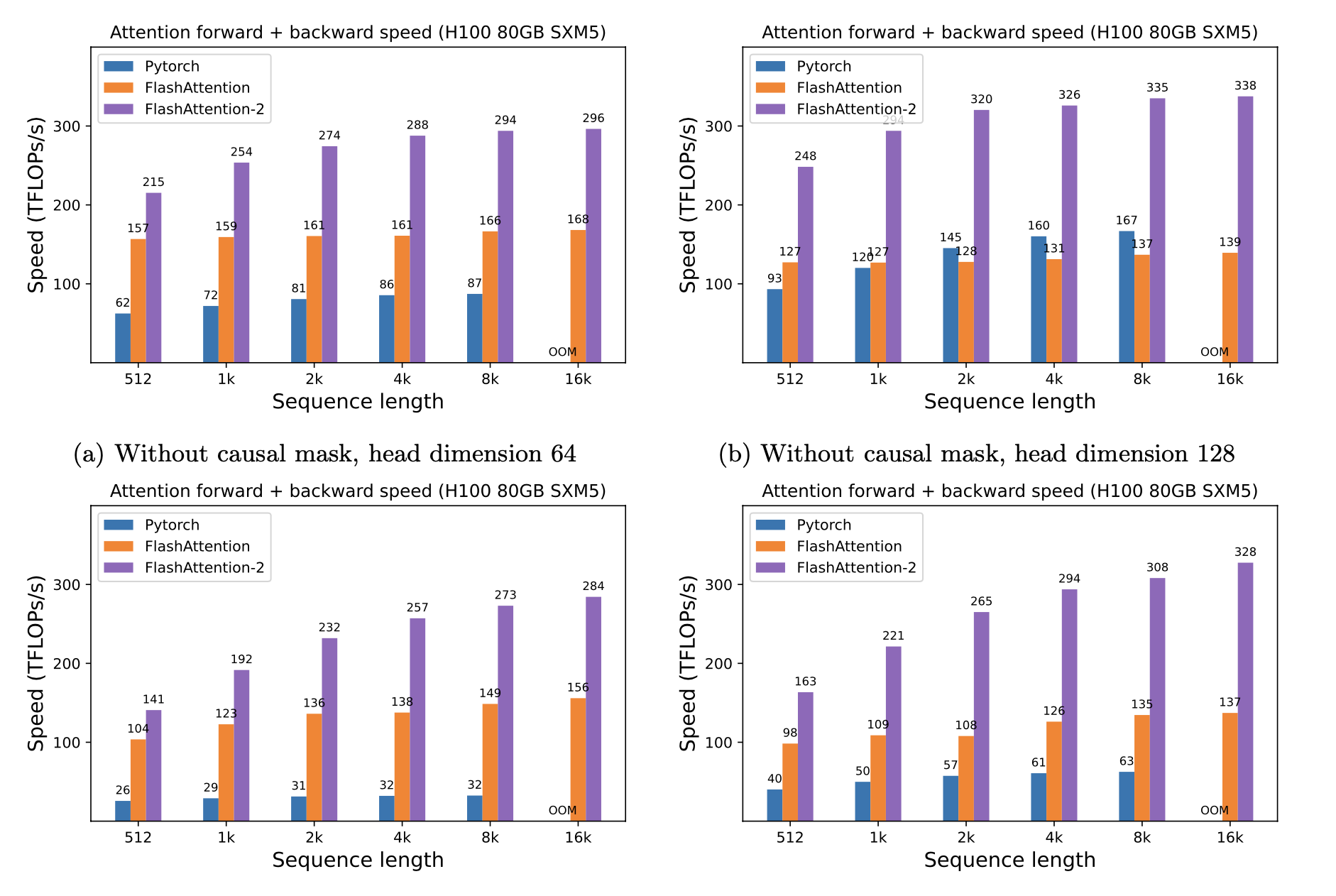
We present expected speedup (combined forward + backward pass) and memory savings from using FlashAttention against PyTorch standard attention, depending on sequence length, on different GPUs (speedup depends on memory bandwidth - we see more speedup on slower GPU memory).
We present expected speedup (combined forward + backward pass) and memory savings from using FlashAttention against PyTorch standard attention, depending on sequence length, on different GPUs (speedup depends on memory bandwidth - we see more speedup on slower GPU memory).
We currently have benchmarks for these GPUs:
We currently have benchmarks for these GPUs:
*[A100](#a100)
*[A100](#a100)
*[RTX 3090](#rtx-3090)
*[H100](#h100)
*[T4](#t4)
<!-- * [RTX 3090](#rtx-3090) -->
<!-- * [T4](#t4) -->
### A100
### A100
We display FlashAttention speedup using these parameters (similar to BERT-base):
We display FlashAttention speedup using these parameters:
* Batch size 8
* Head dimension 64 or 128, hidden dimension 2048 (i.e. either 32 or 16 heads).
* Head dimension 64
* Sequence length 512, 1k, 2k, 4k, 8k, 16k.
* 12 attention heads
* Batch size set to 16k / seqlen.
Our graphs show sequence lengths between 128 and 4096 (when standard attention runs out of memory on an A100), but FlashAttention can scale up to sequence length 64K.

We generally see 2-4X speedup at sequence lengths between 128 and 4K, and we see more speedup when using dropout and masking, since we fuse the kernels.
At sequence lengths that are popular with language models like 512 and 1K, we see speedups up to 4X when using dropout and masking.
#### Memory
#### Memory
...
@@ -182,38 +157,37 @@ Memory savings are proportional to sequence length -- since standard attention h
...
@@ -182,38 +157,37 @@ Memory savings are proportional to sequence length -- since standard attention h
We see 10X memory savings at sequence length 2K, and 20X at 4K.
We see 10X memory savings at sequence length 2K, and 20X at 4K.
As a result, FlashAttention can scale to much longer sequence lengths.
As a result, FlashAttention can scale to much longer sequence lengths.
#### Head Dimension 128
### H100

We show speedup with head dimension 128.
Here we show batch size 16 with 12 heads.
Speedup is less than with the smaller head sizes, since we have to make the block size smaller in the tiling.
But speedup is still significant, especially with a causal mask.
### RTX 3090
For the RTX 3090, we use batch size 12 with 12 attention heads.

Memory savings are the same as on an A100, so we'll only show speedup here.
We see slightly higher speedups (between 2.5-4.5x) on the GTX 3090, since memory bandwidth on the GDDR6X is lower than A100 HBM (~900 GB/s vs. ~1.5 TB/s).
T4 GPUs are commonly used for inference, so we also measure speedup on the forward pass only (note that these are not directly comparable to the graphs above):
As Triton is a higher-level language than CUDA, it might be easier to understand
and experiment with. The notations in the Triton implementation are also closer

{kind=link}
{kind=link}
{kind=link}