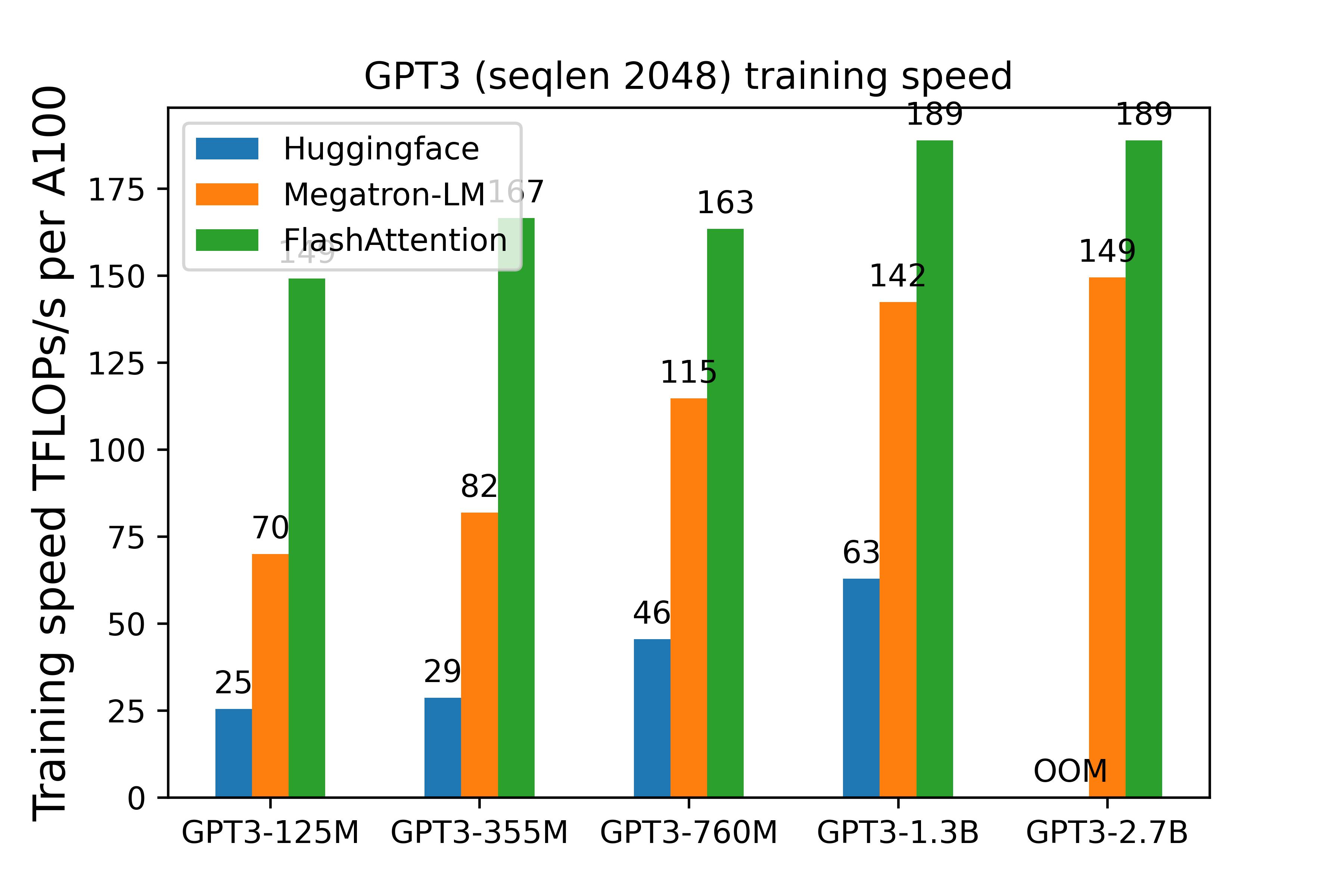
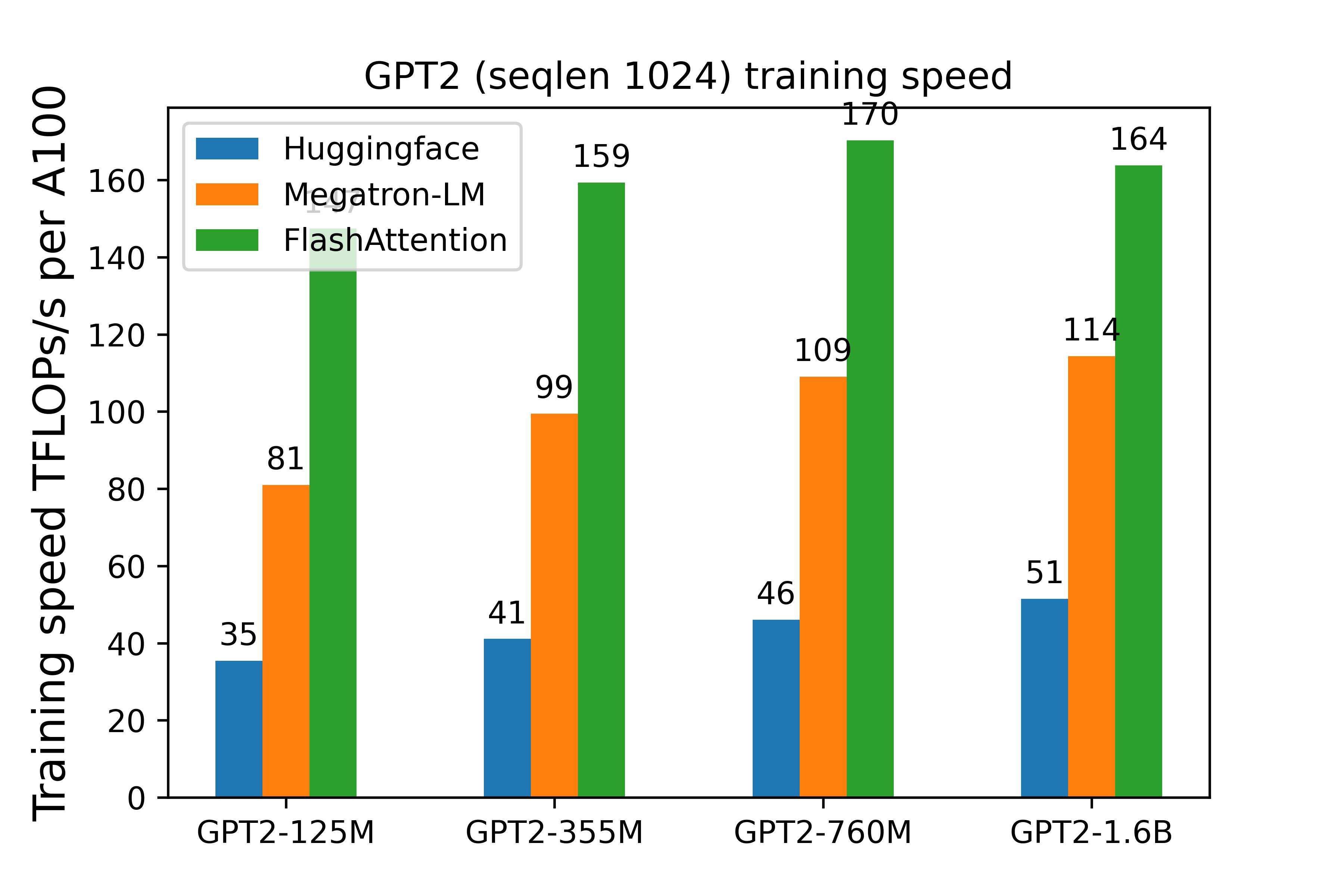
- FlashAttention: fast and memory-efficient exact attention. This makes
1. FlashAttention: fast and memory-efficient exact attention. This makes
attention much faster and saves a lot of activation memory. As a result we don't need
attention much faster and saves a lot of activation memory. As a result we don't need
to use any activation checkpointing.
to use any activation checkpointing.
```sh
```sh
pip install flash-attn
pip install flash-attn
```
```
- Fused matmul + bias (forward and backward), and fused matmul + bias + gelu
2. Fused matmul + bias (forward and backward), and fused matmul + bias + gelu
(forward and backward), adapted from Apex's
(forward and backward), adapted from Apex's
[FusedDense](https://github.com/NVIDIA/apex/tree/master/apex/fused_dense). We
[FusedDense](https://github.com/NVIDIA/apex/tree/master/apex/fused_dense). We
make it work for bfloat16. For best performance, you should use CUDA >= 11.8. CuBLAS versions before
make it work for bfloat16. For best performance, you should use CUDA >= 11.8. CuBLAS versions before
...
@@ -47,16 +71,16 @@ this doesn't have the best matmul + bias + gelu performance for bfloat16.
...
@@ -47,16 +71,16 @@ this doesn't have the best matmul + bias + gelu performance for bfloat16.
```sh
```sh
cd ../csrc/fused_dense_lib && pip install .
cd ../csrc/fused_dense_lib && pip install .
```
```
- Optimized cross-entropy loss, adapted from Apex's
3. Optimized cross-entropy loss, adapted from Apex's
[Xentropy](https://github.com/NVIDIA/apex/tree/master/apex/contrib/xentropy). We make it work for bfloat16 and support in-place backward to save memory.
[Xentropy](https://github.com/NVIDIA/apex/tree/master/apex/contrib/xentropy). We make it work for bfloat16 and support in-place backward to save memory.
```sh
```sh
cd ../csrc/xentropy && pip install .
cd ../csrc/xentropy && pip install .
```
```
- Fused rotary embedding:
4. Fused rotary embedding:
```sh
```sh
cd ../csrc/rotary && pip install .
cd ../csrc/rotary && pip install .
```
```
- Fused dropout + residual + LayerNorm, adapted from Apex's
5. Fused dropout + residual + LayerNorm, adapted from Apex's
[FastLayerNorm](https://github.com/NVIDIA/apex/tree/master/apex/contrib/layer_norm). We add dropout and residual, and make it work for both pre-norm and post-norm architecture.
[FastLayerNorm](https://github.com/NVIDIA/apex/tree/master/apex/contrib/layer_norm). We add dropout and residual, and make it work for both pre-norm and post-norm architecture.
This only supports a limited set of dimensions, see `csrc/layer_norm/ln_fwd_cuda_kernel.cu`.
This only supports a limited set of dimensions, see `csrc/layer_norm/ln_fwd_cuda_kernel.cu`.
```sh
```sh
...
@@ -65,8 +89,9 @@ cd ../csrc/layer_norm && pip install .
...
@@ -65,8 +89,9 @@ cd ../csrc/layer_norm && pip install .
## Training
## Training
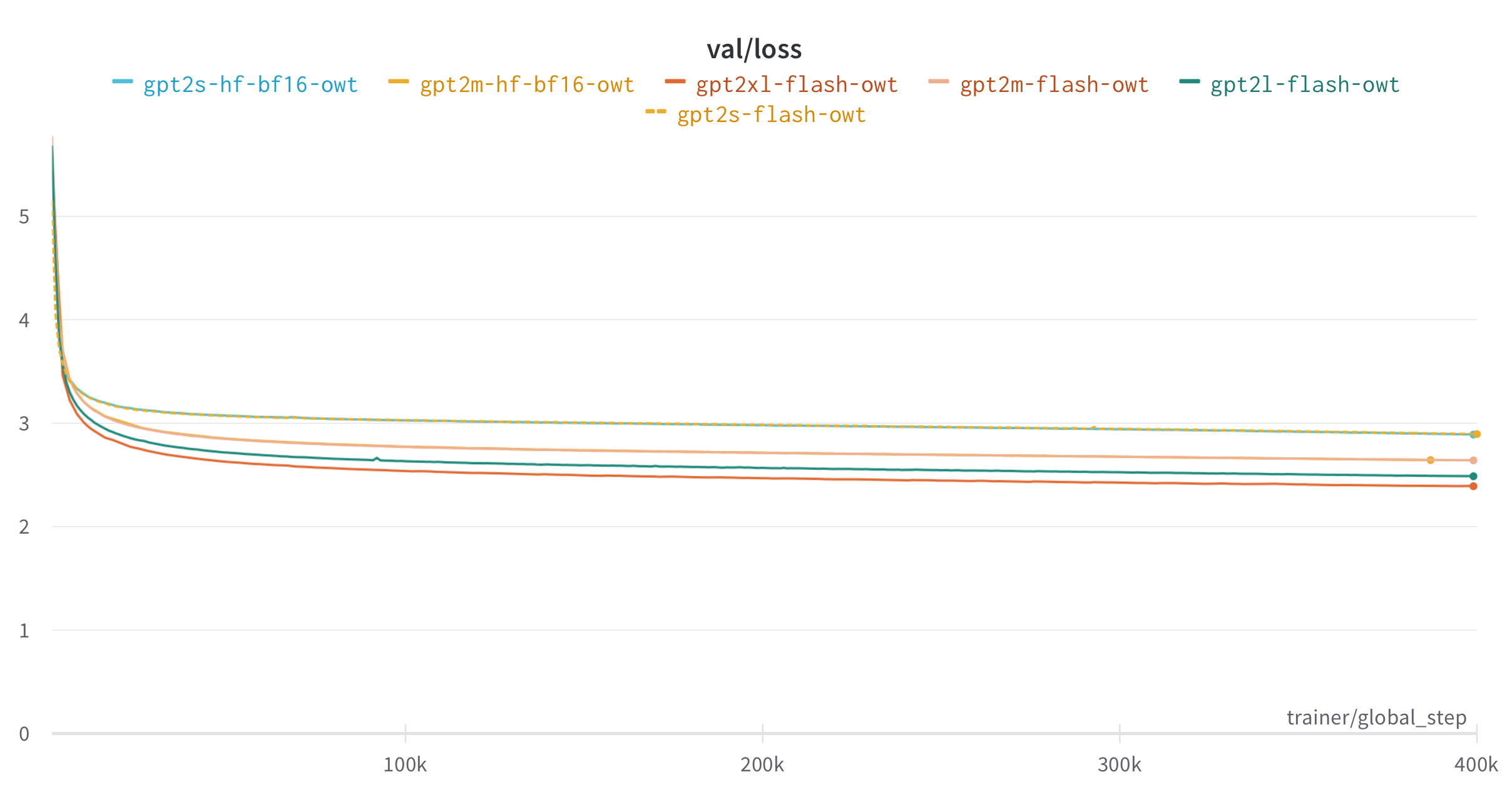
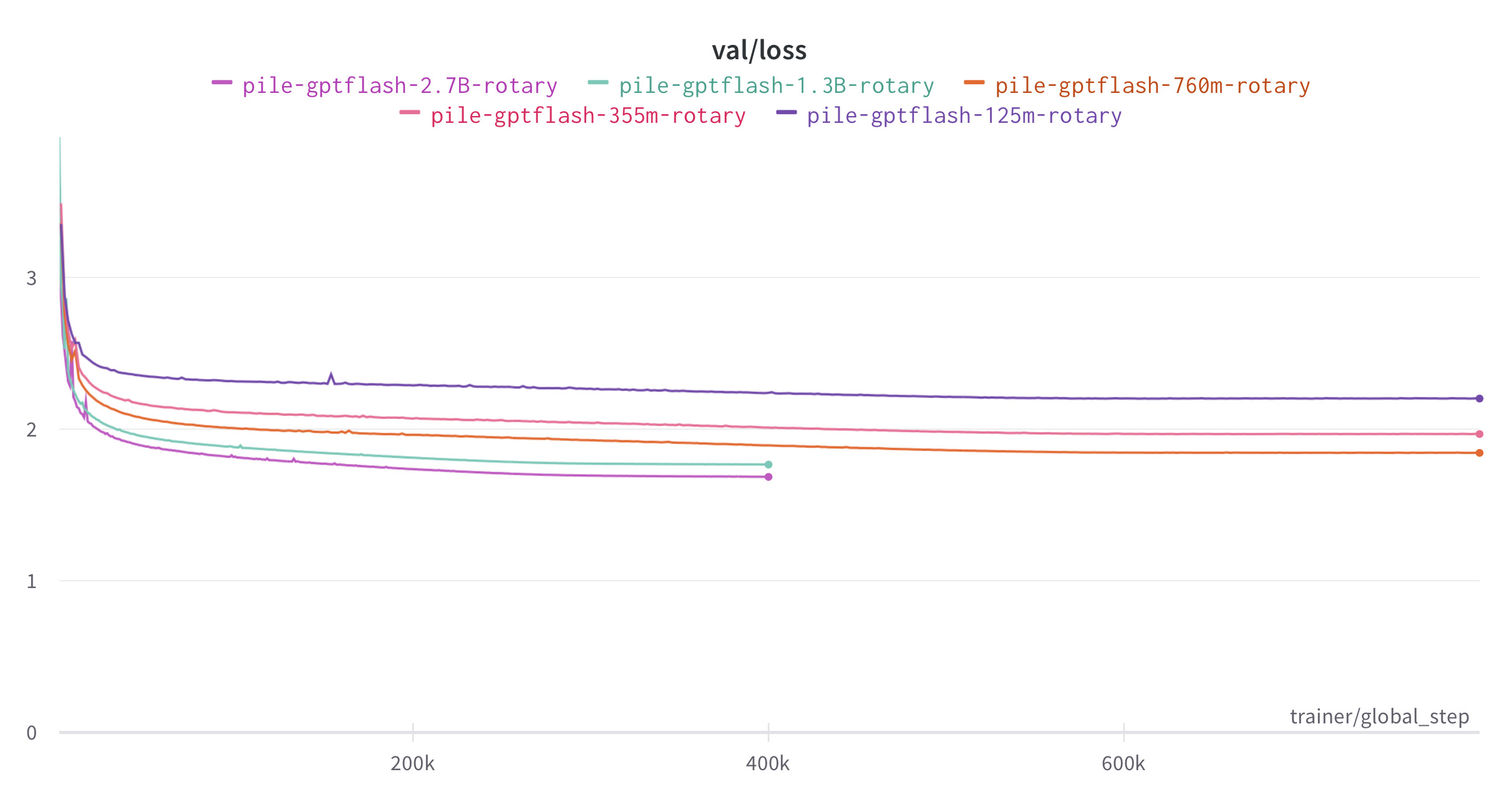
Feel free to use the model in your training setup. We also provide here training
We also provide here training scripts to train GPT2 on Openwebtext and GPT3 on
scripts to train GPT2 on Openwebtext and GPT3 on The Pile as examples.
The Pile as examples. Feel free to use the model in your own training setup as
well.
We use [Hydra](https://hydra.cc/) for configuration,
We use [Hydra](https://hydra.cc/) for configuration,
[Pytorch-Lightning](https://github.com/Lightning-AI/lightning) for training, and
[Pytorch-Lightning](https://github.com/Lightning-AI/lightning) for training, and
...
@@ -75,12 +100,20 @@ We use [Hydra](https://hydra.cc/) for configuration,
...
@@ -75,12 +100,20 @@ We use [Hydra](https://hydra.cc/) for configuration,
We use the template from `https://github.com/ashleve/lightning-hydra-template`.
We use the template from `https://github.com/ashleve/lightning-hydra-template`.
Please read the instructions there to understand the repo structure.
Please read the instructions there to understand the repo structure.

{kind=link}
{kind=link}
{kind=link}
{kind=link}