Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
gaoqiong
flash-attention
Commits
2d5b2483
Commit
2d5b2483
authored
Jun 14, 2022
by
Dan Fu
Browse files
Speedup graph for A100, d128
parent
5d07483b
Changes
2
Hide whitespace changes
Inline
Side-by-side
Showing
2 changed files
with
8 additions
and
0 deletions
+8
-0
README.md
README.md
+8
-0
assets/flashattn_speedup_a100_d128.jpg
assets/flashattn_speedup_a100_d128.jpg
+0
-0
No files found.
README.md
View file @
2d5b2483
...
@@ -71,6 +71,14 @@ Memory savings are proportional to sequence length -- since standard attention h
...
@@ -71,6 +71,14 @@ Memory savings are proportional to sequence length -- since standard attention h
We see 10X memory savings at sequence length 2K, and 20X at 4K.
We see 10X memory savings at sequence length 2K, and 20X at 4K.
As a result, FlashAttention can scale to much longer sequence lengths.
As a result, FlashAttention can scale to much longer sequence lengths.
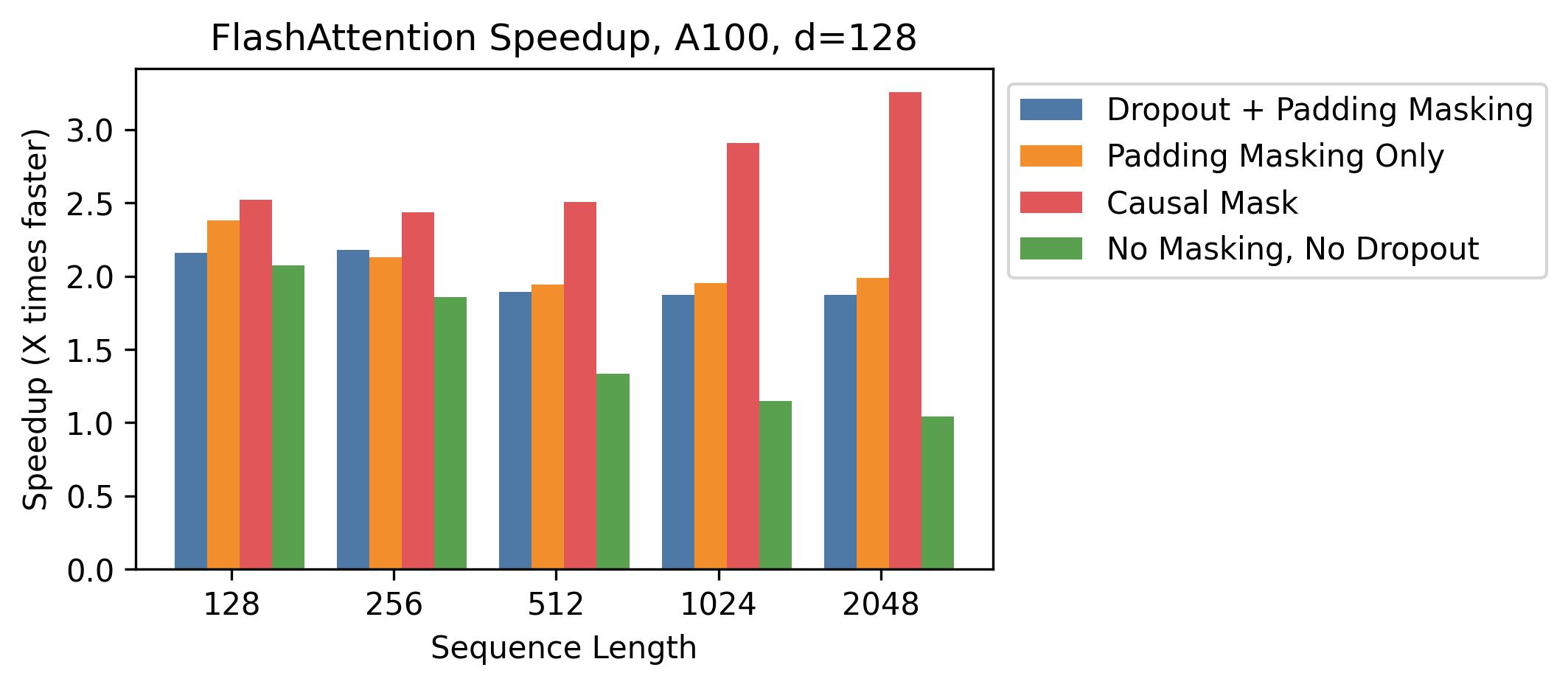
#### Head Dimension 128

We show speedup with head dimension 128.
Here we show batch size 16 with 12 heads.
Speedup is less than with the smaller head sizes, but speedup is still significant -- especially with a causal mask.
### RTX 3090
### RTX 3090
For the RTX 3090, we use batch size 12 with 12 attention heads.
For the RTX 3090, we use batch size 12 with 12 attention heads.
...
...
assets/flashattn_speedup_a100_d128.jpg
0 → 100644
View file @
2d5b2483
125 KB
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}