Implementing the fused-moe block operator using ck-tile. This is a scatter/gather-group-gemm based solution, similiar to that of [vllm moe](https://github.com/vllm-project/vllm/blob/main/benchmarks/kernels/benchmark_moe.py), but we introduce more kernel fusion to boost performance

The benifit of this fused-moe:
* 1.5~2x perf boost compared with current vllm solution
* zero workspace to reduce memory footprint
* much less kernel instance, easy to maintain
# Implementation and feature support
## moe-sorting
this is a common pre-process step before the actual moe-gemm. The purpose is to transform the moe loop over from token-by-token to expert-by-expert, make sure very workgroup is working for a single expert (B matrix). Besides, we extend this op to do the zeroing of the output buffer(to be used for reduce buffer with atomic)
## moe-gemm
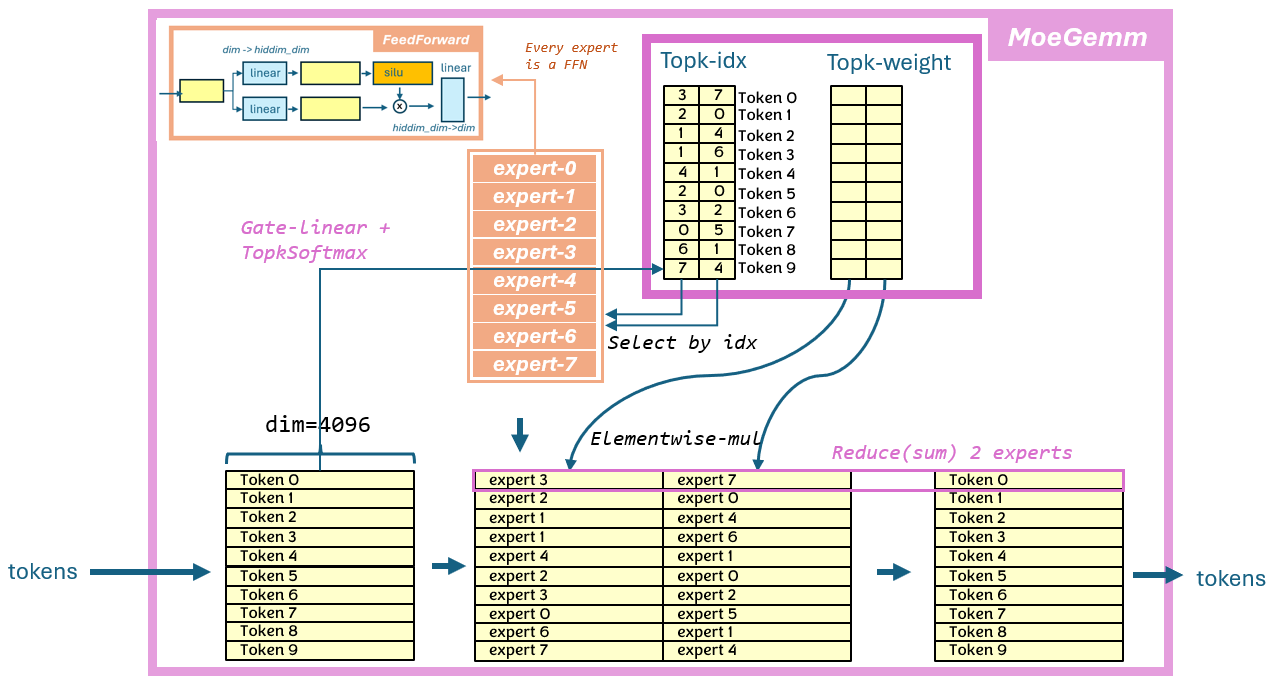
`moe-gemm` is a group-gemm based back-to-back gemm, where the row-id of input token comes from another buffer. Naive understanding of fused-moe is from token-by-token view as below picture:

After `moe-sorting`, we can view this algorithm as expert-by-expert, as below:

## optimization
summary of the key design of this fused-moe operator:
* fuse 2 group-gemm + activation + `topk-weight` multiply into single kernel, using atomic for 2nd gemm accumualation
* fuse buffer-zeroing in `moe-sorgin`, user no longer need call extra torch.zero() for the out buffer
* fused scatter-gather for row index(same as vllm)
* pre-shuffle B matric(weight) to maximize memory throughput. input(activation) keep original layout `[batch, hidden]`.
* extrem optimized pipeline using block-inline-asm(we call it `micro-kernel` or `uk`), while not breaking the *composable* design of ck
##
```
// [indexing implementation-1]
// using M_a as constexpr block_size to partition all tokens into different slices
// each slice map to one expert, and one expert can have multiple slices

{kind=link}

{kind=link}
{kind=link}

{kind=link}
