This folder contains example for Layernorm2D forward using ck_tile tile-programming implementation.
This folder contains example for Layernorm2D forward using `ck_tile` tile-programming implementation.
# Implementation and feature support
## welford online algorithm
We use welfold algorithm to update `mean`/`variance` block by block. For `N <=4096` case we can compute `mean`/`var`/`normalization` within one loop, we call it `one-pass`. For large N case, it is hard to keep `mean`/`var` inside register/LDS and then computation `normalization`, so we need to load input twice, first time to compute `mean`/`var` block-by-block, then load input another time to compute the `normalization`. We call it `two-pass`.
## mean/variance save
In training case the mean/variance need to store out (TBD, not supported yet)
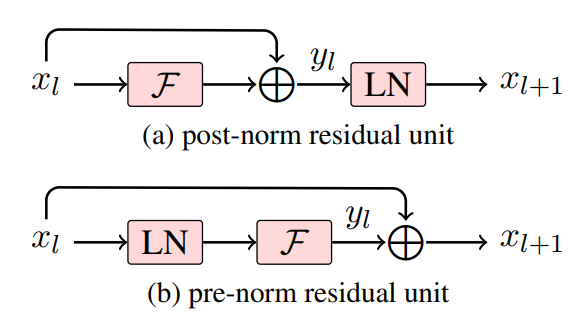
## prenorm/postnorm

since [prenorm/postnorm](https://arxiv.org/pdf/1906.01787) is quite common in LLM blocks, this example boosts this feature by kernel fusion. Note that `prenorm`/`postnorm` always need to do elementwise-add a `shortcut` before the actual layernorm computation, and optionally store out the result to global. You can use `-fadd=1` to test `pre-add+store`, or `-fadd=2` to test `pre-add` without store out (not codegen by default).
## smooth-quant/dynamic-quant
we support smooth/dynamic quantization for `int8` output, by setting `-fquant=1` and `-prec_o=int8`. In this case the output will doing a rowwise dynamic quantization like below. Note that smooth-quant require input a `(1*N)` size per-channel scale(in fp32 in our example, though this is customizable), then elememt-wise multiply the tensor for each row, then compute the rowwise dynamic quant. if set `-fquant=2` will have the input per-channel scale stage, only the dynamic quant. This case is supported in our kernel but by default not generated (TBD: add some filter in generate.py support on-demand codegen)

```
# assume output int8, hidden_states is [m, n] shape and in fp16/bf16
Note that `fquant=2`, `fadd=2`, `prec_sx/prec_sy` other than `fp32` are not by default generated. Though our kernel template suppor this. (TBD: add some flag in generate.py) to generate those instance on demand. Beside, `N>8192` case will by default using two-pass pipeline, and `-fquant=1/2` are not supported yet. If need suport `N>8192` and `fused+residual+store`, you can use this example together with `12_smoothquant`, to construct layernorm+residual, and smoothquant, 2 kernels for this purpose.
This folder contains example for permute kernel, which is similiar to [torch.permute](https://pytorch.org/docs/stable/generated/torch.permute.html)(combined with [torch.contiguous](https://pytorch.org/docs/stable/generated/torch.Tensor.contiguous.html)). Currently we implement a generic permute kernel that support up to rank 8 arbitrary permutation with a single kernel instance. Performance is not the first consideration, we prefer a simple and general kernel implementation using `ck_tile` in this example.
```
args:
-v weather do CPU validation or not (default:1)
-prec data type. fp16/bf16/fp32 (default:fp16)
-shape the shape of the input tensor (default:2,3,4)
-perm permute perm (default:2,1,0)
```
## build
```
# in the root of ck_tile
mkdir build && cd build
sh ../script/cmake-ck-dev.sh ../ <arch> # you can replace this <arch> to gfx90a, gfx942...
make tile_example_permute -j
```
This will result in an executable `build/bin/tile_example_permute`
# in the root of ck_tile, after you build this example
sh example/ck_tile/06_permute/script/smoke_test.sh
```
### alternative implementation
we have an alternative implementation under `alternative_impl/` folder, that can swizzle the tensor to be more friendly for data loading for matrix core layout. This can be enabled when dealing with a `rank-7` tensor, with a fixed pattern of either `0,1,4,2,5,3,6` or `0,1,2,4,5,3,6`. There are other shape limitation of this implementation, check the source code of `permute.cpp` for detail.

{kind=link}

{kind=link}