Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
chenzk
AlphaFold2_jax
Commits
527317eb
Commit
527317eb
authored
Sep 04, 2023
by
zhuwenwen
Browse files
update readme std
parent
5aa6ee00
Changes
4
Hide whitespace changes
Inline
Side-by-side
Showing
4 changed files
with
29 additions
and
5 deletions
+29
-5
README.md
README.md
+14
-5
docs/alphafold2.png
docs/alphafold2.png
+0
-0
docs/result_pdb.png
docs/result_pdb.png
+0
-0
pkl2plddt.py
pkl2plddt.py
+15
-0
No files found.
README.md
View file @
527317eb
...
@@ -11,6 +11,8 @@
...
@@ -11,6 +11,8 @@
## 模型结构
## 模型结构
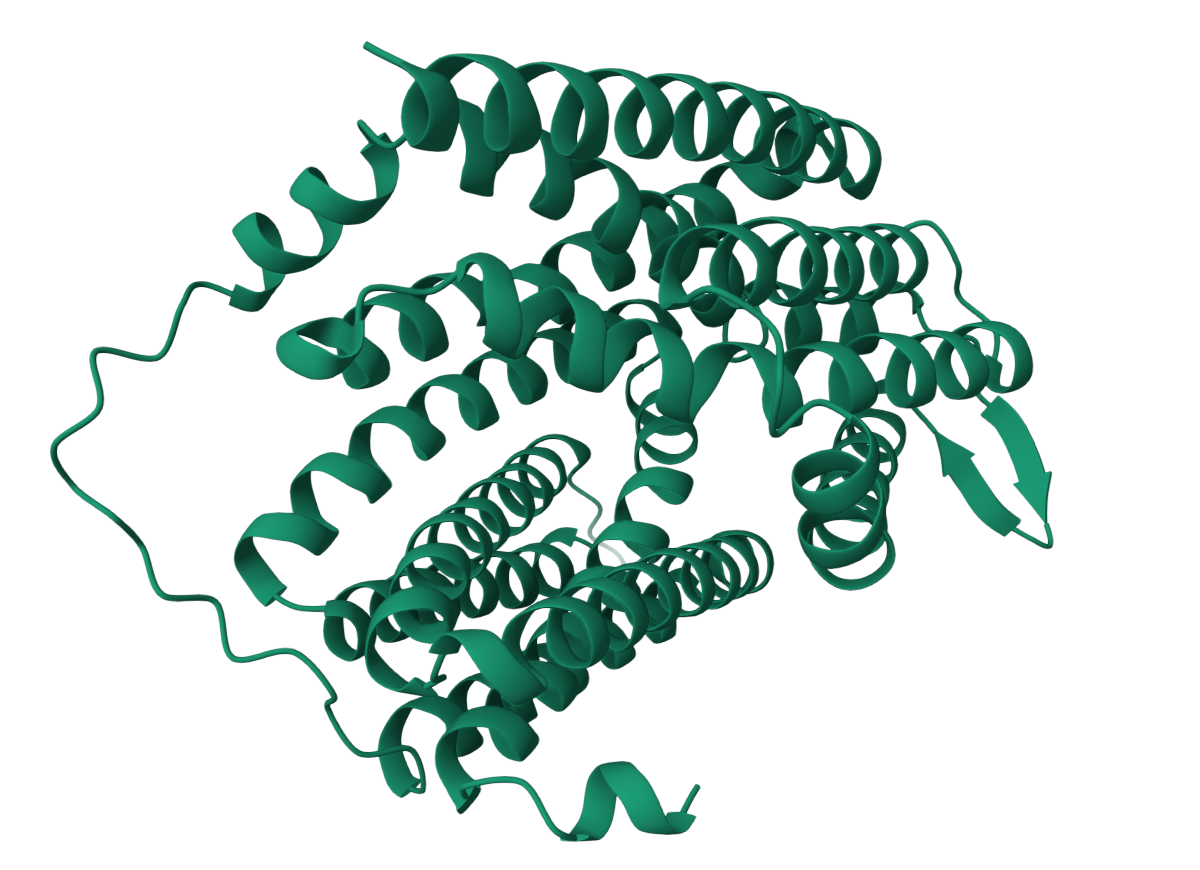
模型核心是一个基于Transformer架构的神经网络,包括两个主要组件:Sequence to Sequence Model和Structure Model,这两个组件通过迭代训练进行优化,以提高其预测准确性。
模型核心是一个基于Transformer架构的神经网络,包括两个主要组件:Sequence to Sequence Model和Structure Model,这两个组件通过迭代训练进行优化,以提高其预测准确性。

## 算法原理
## 算法原理
AlphaFold2通过从蛋白质序列和结构数据中提取信息,使用神经网络模型来预测蛋白质三维结构。
AlphaFold2通过从蛋白质序列和结构数据中提取信息,使用神经网络模型来预测蛋白质三维结构。
...
@@ -35,7 +37,7 @@ docker run -it --name alphafold --shm-size=32G --device=/dev/kfd --device=/dev/
...
@@ -35,7 +37,7 @@ docker run -it --name alphafold --shm-size=32G --device=/dev/kfd --device=/dev/
测试目录:
测试目录:
`/opt/docker/test/alphafold`
`/opt/docker/test
s
/alphafold`
## 数据集
## 数据集
推荐使用AlphaFold2中的开源数据集,包括BFD、MGnify、PDB70、Uniclust、Uniref90等,数据集大小约3TB。
推荐使用AlphaFold2中的开源数据集,包括BFD、MGnify、PDB70、Uniclust、Uniref90等,数据集大小约3TB。
...
@@ -67,8 +69,7 @@ docker run -it --name alphafold --shm-size=32G --device=/dev/kfd --device=/dev/
...
@@ -67,8 +69,7 @@ docker run -it --name alphafold --shm-size=32G --device=/dev/kfd --device=/dev/
或者使用
`./run_monomer.sh`
或者使用
`./run_monomer.sh`
#### 单体推理参数说明
#### 单体推理参数说明
monomer.fasta为推理的单体序列;--output_dir为输出目录;--model_preset选择模型配置;--run_relax=true为进行relax操作;--use_gpu_relax=true为使用gpu进行relax操作(速度更快,但可能不太稳定),--use_gpu_relax=false为使用CPU进行relax操作(速度慢,但稳定);
monomer.fasta为推理的单体序列;
`--output_dir`
为输出目录;
`--model_preset`
选择模型配置;
`--run_relax=true`
为进行relax操作;
`--use_gpu_relax=true`
为使用gpu进行relax操作(速度更快,但可能不太稳定),
`--use_gpu_relax=false`
为使用CPU进行relax操作(速度慢,但稳定);若添加--use_precomputed_msas=true则可以加载已经搜索对齐的序列,否则默认进行搜索对齐;
若添加--use_precomputed_msas=true则可以加载已经搜索对齐的序列,否则默认进行搜索对齐;
### 多体
### 多体
...
@@ -106,10 +107,20 @@ multimer.fasta为推理的多体序列,data为数据集下载路径,其他
...
@@ -106,10 +107,20 @@ multimer.fasta为推理的多体序列,data为数据集下载路径,其他
...
...
```
```

## 精度
## 精度
测试数据:
[
casp14
](
https://www.predictioncenter.org/casp14/targetlist.cgi
)
、
[
uniprot
](
https://www.uniprot.org/
)
,
测试数据:
[
casp14
](
https://www.predictioncenter.org/casp14/targetlist.cgi
)
、
[
uniprot
](
https://www.uniprot.org/
)
,
使用的加速卡:1张 DCU 1代-16G
使用的加速卡:1张 DCU 1代-16G
1、计算lddt的值
python3 run_alphafold.py
其中,data_path为推理生成的pkl文件路径。
2、其它精度值计算:
[
https://zhanggroup.org/TM-score/
](
https://zhanggroup.org/TM-score/
)
准确性数据:
准确性数据:
| 数据类型 | 序列类型 | 序列标签 | 序列长度 | GDT-TS | GDT-HA | LDDT | TM score | MaxSub | RMSD |
| 数据类型 | 序列类型 | 序列标签 | 序列长度 | GDT-TS | GDT-HA | LDDT | TM score | MaxSub | RMSD |
| :------: | :------: | :------: | :------: |:------: |:------: | :------: | :------: | :------: |:------: |
| :------: | :------: | :------: | :------: |:------: |:------: | :------: | :------: | :------: |:------: |
...
@@ -125,8 +136,6 @@ NLP
...
@@ -125,8 +136,6 @@ NLP
### 热点应用行业
### 热点应用行业
医疗,科研,教育
医疗,科研,教育
## 源码仓库及问题反馈
## 源码仓库及问题反馈
*
[
https://developer.hpccube.com/codes/modelzoo/AlphaFold2
](
https://developer.hpccube.com/codes/modelzoo/AlphaFold2
)
*
[
https://developer.hpccube.com/codes/modelzoo/AlphaFold2
](
https://developer.hpccube.com/codes/modelzoo/AlphaFold2
)
...
...
docs/alphafold2.png
0 → 100644
View file @
527317eb
95.4 KB
docs/result_pdb.png
0 → 100644
View file @
527317eb
480 KB
pkl2plddt.py
0 → 100644
View file @
527317eb
import
pickle
import
numpy
as
np
import
sys
np
.
set_printoptions
(
threshold
=
1000000000000000000
)
data_path
=
r
'output/monomer/result_model_1.pkl'
with
open
(
data_path
,
'rb'
)
as
f
:
datas
=
pickle
.
load
(
f
)
log
=
open
(
'output/T1024.txt'
,
mode
=
"a+"
,
encoding
=
"utf-8"
)
# np.set_printoptions(threshold=5000)
print
(
np
.
mean
(
datas
[
'plddt'
]),
file
=
log
)
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}
{kind=link}