This Model is suitable for Training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).
This Model is suitable for Training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).
It can be used as a drop-in Replacement for **BERT** in most down-stream tasks (**ELECTRA** is even implemented as an extended **BERT** Class).
It can be used as a drop-in Replacement for **BERT** in most down-stream tasks (**ELECTRA** is even implemented as an extended **BERT** Class).
At the time of release (August 2020) this Model is the best performing publicly available German NLP Model on various German Evaluation Metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.
At the time of release (August 2020) this Model is the best performing publicly available German NLP Model on various German Evaluation Metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.
# Installation
This model has the special feature that it is **uncased** but does **not strip accents**.
This possibility was added by us with [PR #6280](https://github.com/huggingface/transformers/pull/6280).
To use it you have to use Transformers version 3.1.0 or newer.
## Installation
```bash
pip install transformers -U
---
```
This model is **uncased** but does not use **strip accents**.
The necessary parameter is `strip_accents=False`.
This needs to be set for the tokenizer otherwise the model will perform slightly worse.
It was added to Transformers with [PR #6280](https://github.com/huggingface/transformers/pull/6280).
Since Transformers has not been released since the PR #6280 was merged, you have to install directly from source:
- (1): Hyperparameters taken from the [FARM project](https://farm.deepset.ai/) "[germEval18Coarse_config.json](https://github.com/deepset-ai/FARM/blob/master/experiments/german-bert2.0-eval/germEval18Coarse_config.json)"
- (1): Hyperparameters taken from the [FARM project](https://farm.deepset.ai/) "[germEval18Coarse_config.json](https://github.com/deepset-ai/FARM/blob/master/experiments/german-bert2.0-eval/germEval18Coarse_config.json)"


## Checkpoint evaluation
# Checkpoint evaluation
Since it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus. Below is a boxplot chart showing the different checkpoints.
Since it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus. Below is a boxplot chart showing the different checkpoints.
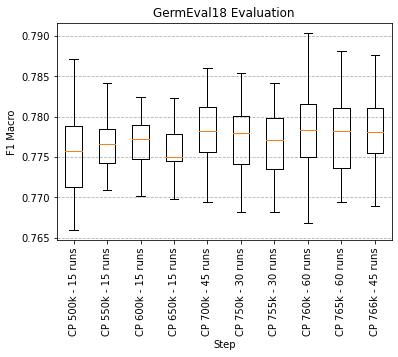

## Pre-training details
# Pre-training details
### Data
## Data
- Cleaned Common Crawl Corpus 2019-09 German: [CC_net](https://github.com/facebookresearch/cc_net)(Only head coprus and filtered for language_score > 0.98) - 62 GB
- Cleaned Common Crawl Corpus 2019-09 German: [CC_net](https://github.com/facebookresearch/cc_net)(Only head coprus and filtered for language_score > 0.98) - 62 GB
- German Wikipedia Article Pages Dump (20200701) - 5.5 GB
- German Wikipedia Article Pages Dump (20200701) - 5.5 GB
- German Wikipedia Talk Pages Dump (20200620) - 1.1 GB
- German Wikipedia Talk Pages Dump (20200620) - 1.1 GB
...
@@ -84,7 +77,7 @@ The sentences were split with [SojaMo](https://github.com/tsproisl/SoMaJo). We t
...
@@ -84,7 +77,7 @@ The sentences were split with [SojaMo](https://github.com/tsproisl/SoMaJo). We t
More Details can be found here [Preperaing Datasets for German Electra Github](https://github.com/German-NLP-Group/german-transformer-training)
More Details can be found here [Preperaing Datasets for German Electra Github](https://github.com/German-NLP-Group/german-transformer-training)
### Electra Branch no_strip_accents
## Electra Branch no_strip_accents
Because we do not want to stip accents in our training data we made a change to Electra and used this repo [Electra no_strip_accents](https://github.com/PhilipMay/electra/tree/no_strip_accents)(branch`no_strip_accents`). Then created the tf dataset with:
Because we do not want to stip accents in our training data we made a change to Electra and used this repo [Electra no_strip_accents](https://github.com/PhilipMay/electra/tree/no_strip_accents)(branch`no_strip_accents`). Then created the tf dataset with:
