@@ -126,7 +126,7 @@ This package comprises the following classes that can be imported in Python and
...
@@ -126,7 +126,7 @@ This package comprises the following classes that can be imported in Python and
-`BertAdam` - Bert version of Adam algorithm with weight decay fix, warmup and linear decay of the learning rate.
-`BertAdam` - Bert version of Adam algorithm with weight decay fix, warmup and linear decay of the learning rate.
- Optimizer for **OpenAI GPT** (in the [`optimization_openai.py`](./pytorch_pretrained_bert/optimization_openai.py) file):
- Optimizer for **OpenAI GPT** (in the [`optimization_openai.py`](./pytorch_pretrained_bert/optimization_openai.py) file):
-`OpenAIGPTAdam` - OpenAI GPT version of Adam algorithm with weight decay fix, warmup and linear decay of the learning rate.
-`OpenAIAdam` - OpenAI GPT version of Adam algorithm with weight decay fix, warmup and linear decay of the learning rate.
- Configuration classes for BERT, OpenAI GPT and Transformer-XL (in the respective [`modeling.py`](./pytorch_pretrained_bert/modeling.py), [`modeling_openai.py`](./pytorch_pretrained_bert/modeling_openai.py), [`modeling_transfo_xl.py`](./pytorch_pretrained_bert/modeling_transfo_xl.py) files):
- Configuration classes for BERT, OpenAI GPT and Transformer-XL (in the respective [`modeling.py`](./pytorch_pretrained_bert/modeling.py), [`modeling_openai.py`](./pytorch_pretrained_bert/modeling_openai.py), [`modeling_transfo_xl.py`](./pytorch_pretrained_bert/modeling_transfo_xl.py) files):
-`BertConfig` - Configuration class to store the configuration of a `BertModel` with utilities to read and write from JSON configuration files.
-`BertConfig` - Configuration class to store the configuration of a `BertModel` with utilities to read and write from JSON configuration files.
...
@@ -984,19 +984,48 @@ The optimizer accepts the following arguments:
...
@@ -984,19 +984,48 @@ The optimizer accepts the following arguments:
-`warmup` : portion of `t_total` for the warmup, `-1` means no warmup. Default : `-1`
-`warmup` : portion of `t_total` for the warmup, `-1` means no warmup. Default : `-1`
-`t_total` : total number of training steps for the learning
-`t_total` : total number of training steps for the learning
rate schedule, `-1` means constant learning rate. Default : `-1`
rate schedule, `-1` means constant learning rate. Default : `-1`
-`schedule` : schedule to use for the warmup (see above). Default : `'warmup_linear'`
-`schedule` : schedule to use for the warmup (see above).
Can be `'warmup_linear'`, `'warmup_constant'`, `'warmup_cosine'`, `'none'`, `None` or a `_LRSchedule` object (see below).
If `None` or `'none'`, learning rate is always kept constant.
Default : `'warmup_linear'`
-`b1` : Adams b1. Default : `0.9`
-`b1` : Adams b1. Default : `0.9`
-`b2` : Adams b2. Default : `0.999`
-`b2` : Adams b2. Default : `0.999`
-`e` : Adams epsilon. Default : `1e-6`
-`e` : Adams epsilon. Default : `1e-6`
-`weight_decay:` Weight decay. Default : `0.01`
-`weight_decay:` Weight decay. Default : `0.01`
-`max_grad_norm` : Maximum norm for the gradients (`-1` means no clipping). Default : `1.0`
-`max_grad_norm` : Maximum norm for the gradients (`-1` means no clipping). Default : `1.0`
#### `OpenAIGPTAdam`
#### `OpenAIAdam`
`OpenAIGPTAdam` is similar to `BertAdam`.
`OpenAIAdam` is similar to `BertAdam`.
The differences with `BertAdam` is that `OpenAIGPTAdam` compensate for bias as in the regular Adam optimizer.
The differences with `BertAdam` is that `OpenAIAdam` compensate for bias as in the regular Adam optimizer.
`OpenAIGPTAdam` accepts the same arguments as `BertAdam`.
`OpenAIAdam` accepts the same arguments as `BertAdam`.
#### Learning Rate Schedules
The `.optimization` module also provides additional schedules in the form of schedule objects that inherit from `_LRSchedule`.
All `_LRSchedule` subclasses accept `warmup` and `t_total` arguments at construction.
When an `_LRSchedule` object is passed into `BertAdam` or `OpenAIAdam`,
the `warmup` and `t_total` arguments on the optimizer are ignored and the ones in the `_LRSchedule` object are used.
An overview of the implemented schedules:
-`ConstantLR`: always returns learning rate 1.
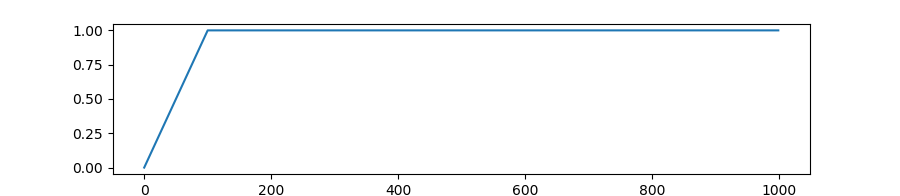
-`WarmupConstantSchedule`: Linearly increases learning rate from 0 to 1 over `warmup` fraction of training steps.
Keeps learning rate equal to 1. after warmup.

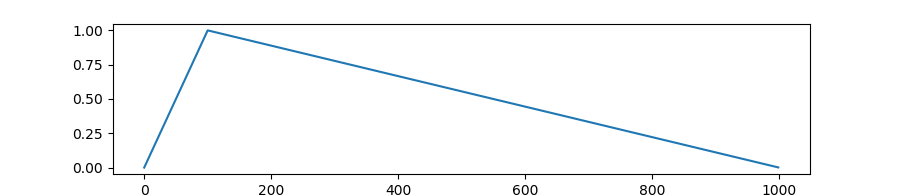
-`WarmupLinearSchedule`: Linearly increases learning rate from 0 to 1 over `warmup` fraction of training steps.
Linearly decreases learning rate from 1. to 0. over remaining `1 - warmup` steps.

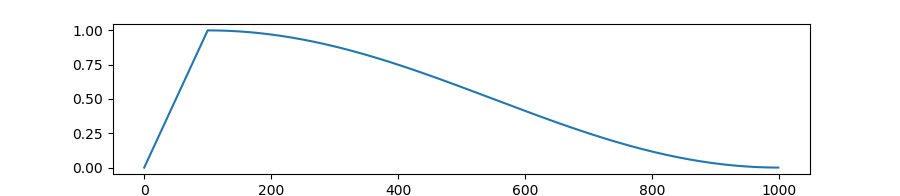
-`WarmupCosineSchedule`: Linearly increases learning rate from 0 to 1 over `warmup` fraction of training steps.
Decreases learning rate from 1. to 0. over remaining `1 - warmup` steps following a cosine curve.
If `cycles` (default=0.5) is different from default, learning rate follows cosine function after warmup.

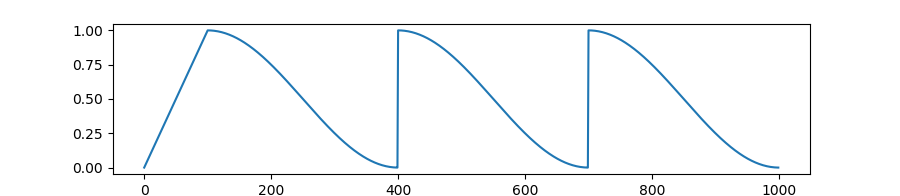
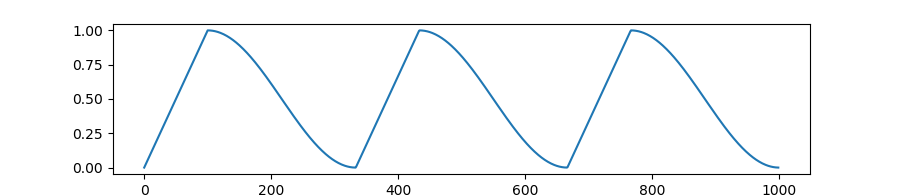
-`WarmupCosineWithHardRestartsSchedule`: Linearly increases learning rate from 0 to 1 over `warmup` fraction of training steps.
If `cycles` (default=1.) is different from default, learning rate follows `cycles` times a cosine decaying learning rate (with hard restarts).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}