"# RAG Powered by SGLang & Chroma Evaluated using Parea\n",
"\n",
"In this notebook, we will build a simple RAG pipeline using SGLang to execute our LLM calls, Chroma as vector database for retrieval and [Parea](https://www.parea.ai) for tracing and evaluation. We will then evaluate the performance of our RAG pipeline. The dataset we will use was created by [Virat](https://twitter.com/virattt) and contains 100 questions, contexts and answers from the Airbnb 2023 10k filing.\n",
"\n",
"The RAG pipeline consists of two steps:\n",
"1. Retrieval: Given a question, we retrieve the relevant context from all provided contexts.\n",
"2. Generation: Given the question and the retrieved context, we generate an answer.\n",
"\n",
"ℹ️ This notebook requires an OpenAI API key.\n",
"\n",
"ℹ️ This notebook requires a Parea API key, which can be created [here](https://docs.parea.ai/api-reference/authentication#parea-api-key)."
],
"metadata": {
"collapsed": false
}
},
{
"cell_type": "markdown",
"source": [
"## Setting up the environment\n",
"\n",
"We will first install the necessary packages: `sglang`, `parea` and `chromadb`."
],
"metadata": {
"collapsed": false
}
},
{
"cell_type": "code",
"execution_count": null,
"outputs": [],
"source": [
"# note, if you use a Mac M1 chip, you might need to install grpcio 1.59.0 first such that installing chromadb works\n",
"# !pip install grpcio==1.59.0\n",
"\n",
"!pip install sglang[openai] parea chromadb"
],
"metadata": {
"collapsed": false
}
},
{
"cell_type": "markdown",
"source": [
"Create a Parea API key as outlined [here](https://docs.parea.ai/api-reference/authentication#parea-api-key) and save it in a `.env` file as `PAREA_API_KEY=your-api-key`."
],
"metadata": {
"collapsed": false
}
},
{
"cell_type": "markdown",
"source": [
"## Indexing the data\n",
"\n",
"Now it's time to download the data & index it! For that, we create a collection called `contexts` in Chroma and add the contexts as documents."
" documents=[qca[\"context\"] for qca in question_context_answers],\n",
" ids=[str(i) for i in range(len(question_context_answers))]\n",
" )"
],
"metadata": {
"collapsed": false
}
},
{
"cell_type": "markdown",
"source": [
"## Defining the RAG pipeline\n",
"\n",
"We will start with importing the necessary packages, setting up tracing of OpenAI calls via Parea and setting OpenAI as the default backend for SGLang."
"Now we can define our retrieval step shown below. Notice, the `trace` decorator which will automatically trace inputs, output, latency, etc. of that call."
],
"metadata": {
"collapsed": false
}
},
{
"cell_type": "code",
"execution_count": null,
"outputs": [],
"source": [
"@trace\n",
"def retrieval(question: str) -> list[str]:\n",
" return collection.query(\n",
" query_texts=[question],\n",
" n_results=1\n",
" )['documents'][0]"
],
"metadata": {
"collapsed": false
}
},
{
"cell_type": "markdown",
"source": [
"Next we will define the generation step which uses SGLang to execute the LLM call."
"Before we apply above's fix, let's dive into evaluating RAG pipelines.\n",
"\n",
"RAG pipelines consist of a retrieval step to fetch relevant information and a generation step to generate a response to a users question. A RAG pipeline can fail at either step. E.g. the retrieval step can fail to find relevant information which makes generating the correct impossible. Another failure mode is that the generation step doesn't leverage the retrieved information correctly. We will apply the following evaluation metrics to understand different failure modes:\n",
"\n",
"- `context_relevancy`: measures how relevant the context is given the question\n",
"- `percent_target_supported_by_context`: measures how much of the target answer is supported by the context; this will give an upper ceiling of how well the generation step can perform\n",
"- `answer_context_faithfulness`: measures how much the generated answer utilizes the context\n",
"- `answer_matches_target`: measures how well the generated answer matches the target answer judged by a LLM and gives a sense of accuracy of our entire pipeline\n",
"\n",
"To use these evaluation metrics, we can import them from `parea.evals.rag` and `parea.evals.general` and apply them to a function by specifying in the `trace` decorator which evaluation metrics to use. The `@trace` decorator will automatically log the results of the evaluation metrics to the Parea dashboard.\n",
"Finally, we tie them together & execute the original sample query."
],
"metadata": {
"collapsed": false
}
},
{
"cell_type": "code",
"execution_count": 4,
"outputs": [
{
"data": {
"text/plain": "'The World Health Organization formally declared an end to the COVID-19 global health emergency in May 2023.'"
},
"execution_count": 4,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"@trace\n",
"def rag_pipeline(question: str) -> str:\n",
" contexts = retrieval(question)\n",
" return generation(question, *contexts)\n",
"\n",
"\n",
"rag_pipeline(\"When did the World Health Organization formally declare an end to the COVID-19 global health emergency?\")"
],
"metadata": {
"collapsed": false
}
},
{
"cell_type": "markdown",
"source": [
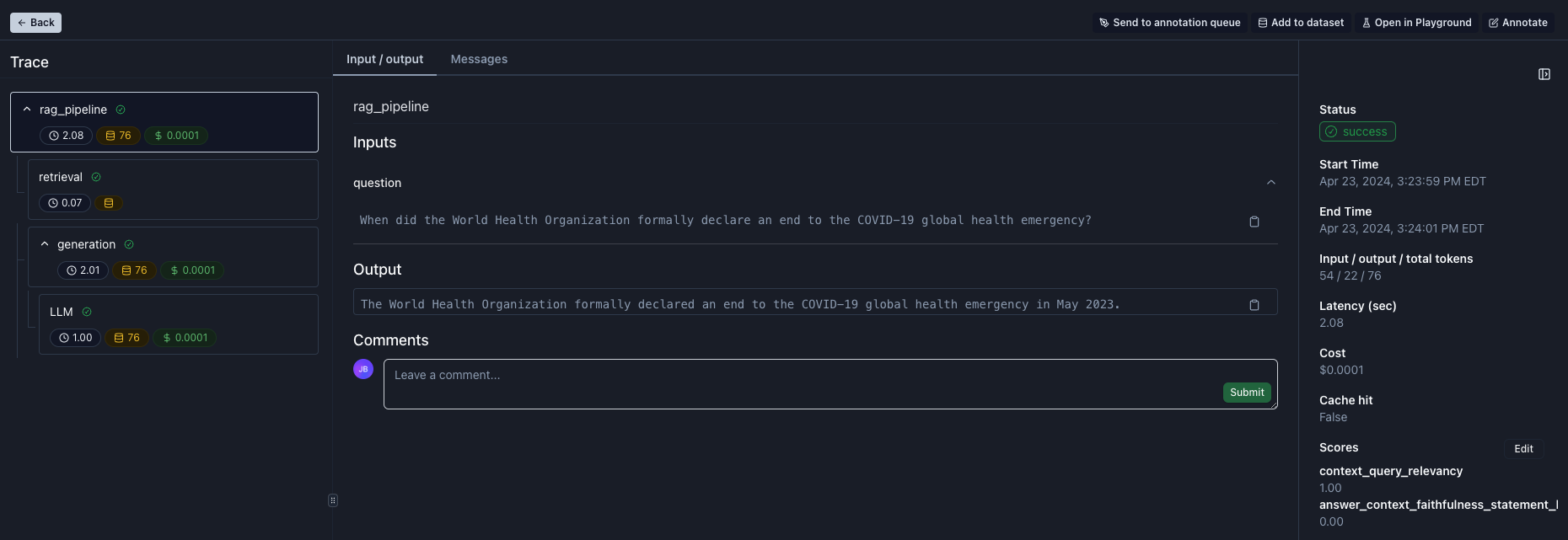
"Great, the answer is correct! Can you spot the line where we fixed the output truncation issue?\n",
"\n",
"The evaluation scores appear in the bottom right of the logs (screenshot below). Note, that there is no score for `answer_matches_target_llm_grader` and `percent_target_supported_by_context` as these evals are automatically skipped if the target answer is not provided.\n",
"Now we are (almost) ready to evaluate the performance of our RAG pipeline on the entire dataset. First, we will need to apply the `nest_asyncio` package to avoid issues with the Jupyter notebook event loop."
],
"metadata": {
"collapsed": false
}
},
{
"cell_type": "code",
"execution_count": 6,
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Requirement already satisfied: nest-asyncio in /Users/joschkabraun/miniconda3/envs/sglang/lib/python3.10/site-packages (1.6.0)\r\n"
]
}
],
"source": [
"!pip install nest-asyncio\n",
"import nest_asyncio\n",
"nest_asyncio.apply()"
],
"metadata": {
"collapsed": false
}
},
{
"cell_type": "markdown",
"source": [
"Running the actual experiment is straight-forward. For that we use `p.experiment` to initialize the experiment with a name, the data (list of key-value pairs fed into our entry function) and the entry function. We then call `run` on the experiment to execute it. Note, that `target` is a reserved key in the data dictionary and will be used as the target answer for evaluation."
],
"metadata": {
"collapsed": false
}
},
{
"cell_type": "code",
"execution_count": 7,
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Run name set to: sneak-weal, since a name was not provided.\n"
"When opening above experiment, we will see an overview of the experiment as shown below. The upper half shows a summary of the statistics on the left and charts to investigate the distribution and relationships of scores on the right. The lower half is a table with the individual traces which we can use to debug individual samples.\n",
"\n",
"When looking at the statistics, we can see that the accuracy of our RAG pipeline is 22% as measured by `answer_matches_target_llm_grader`. Though when checking the quality of our retrieval step (`context_query_relevancy`), we can see that our retrival step is fetching relevant information in only 27% of all samples. As shown in the GIF, we investigate the relationship between the two and see the two scores have 95% agreement. This confirms that the retrieval step is a major bottleneck for our RAG pipeline. So, now it's your turn to improve the retrieval step!\n",
"\n",
"Note, above link isn't publicly accessible but the experiment can be accessed through [here](https://app.parea.ai/public-experiments/parea/rag_sglang/30f0244a-d56c-44ff-bdfb-8f47626304b6).\n",

{kind=link}