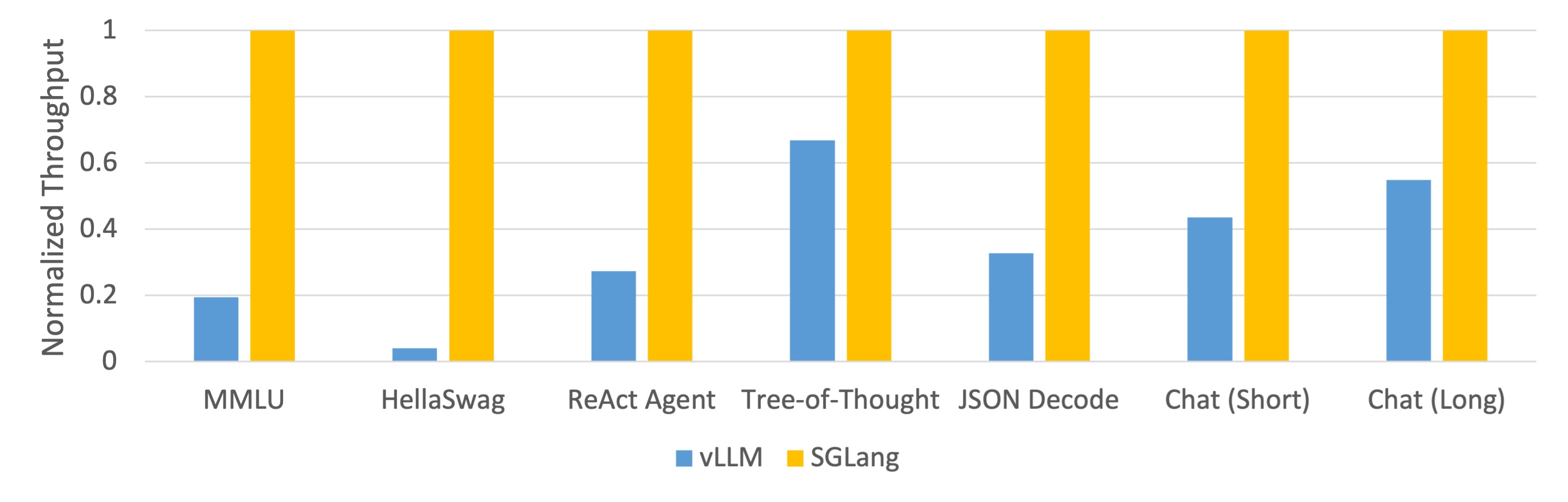
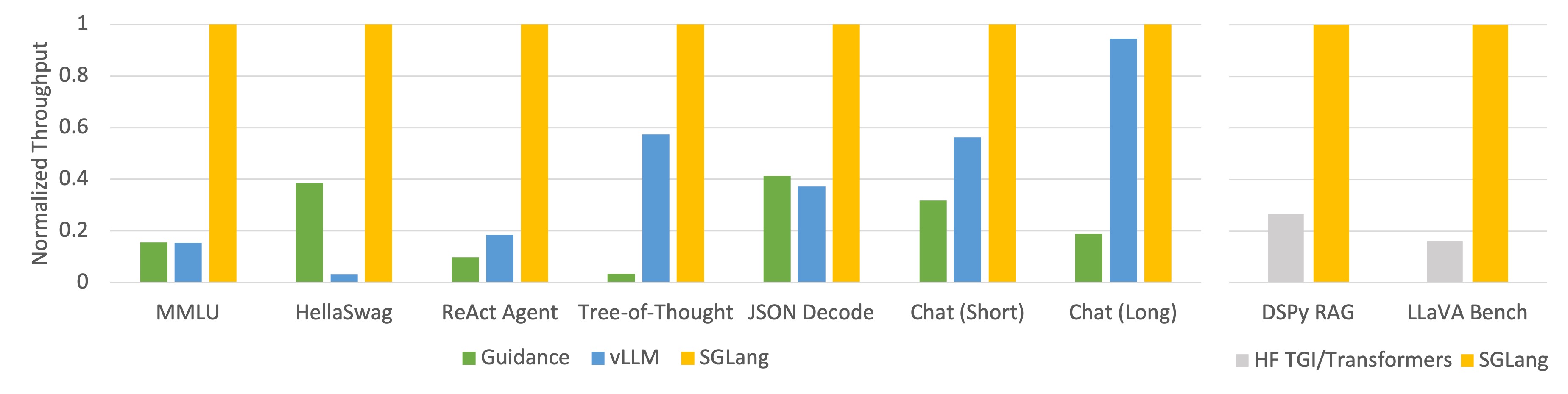
We tested our system on the following common LLM workloads and reported the achieved throughput:
-**[MMLU](https://arxiv.org/abs/2009.03300)**: A 5-shot, multi-choice, multi-task benchmark.
-**[HellaSwag](https://arxiv.org/abs/1905.07830)**: A 20-shot, multi-choice sentence completion benchmark.
-**[ReAct Agent](https://arxiv.org/abs/2210.03629)**: An agent task using prompt traces collected from the original ReAct paper.
-**[Tree-of-Thought](https://arxiv.org/pdf/2305.10601.pdf)**: A custom tree search-based prompt for solving GSM-8K problems.
-**JSON Decode**: Extracting information from a Wikipedia page and outputting it in JSON format.
-**Chat (short)**: A synthetic chat benchmark where each conversation includes 4 turns with short LLM outputs.
-**Chat (long)**: A synthetic chat benchmark where each conversation includes 4 turns with long LLM outputs.
-**[DSPy RAG](https://github.com/stanfordnlp/dspy)**: A retrieval-augmented generation pipeline in the DSPy tutorial.
-**[LLaVA Bench](https://github.com/haotian-liu/LLaVA)**: Running LLaVA v1.5, a vision language model on the LLaVA-in-the-wild benchmark.
We tested both Llama-7B on one NVIDIA A10G GPU (24GB) and Mixtral-8x7B on 8 NVIDIA A10G GPUs with tensor parallelism, using FP16 precision. We used vllm v0.2.5, guidance v0.1.8, Hugging Face TGI v1.3.0, and SGLang v0.1.5.
- Llama-7B on NVIDIA A10G, FP16, Tensor Parallelism=1

- Mixtral-8x7B on NVIDIA A10G, FP16, Tensor Parallelism=8

The benchmark code is available [here](https://github.com/sgl-project/sglang/tree/main/benchmark).

{kind=link}
{kind=link}