
Update gradio and docs
Showing
app/README.md
100755 → 100644
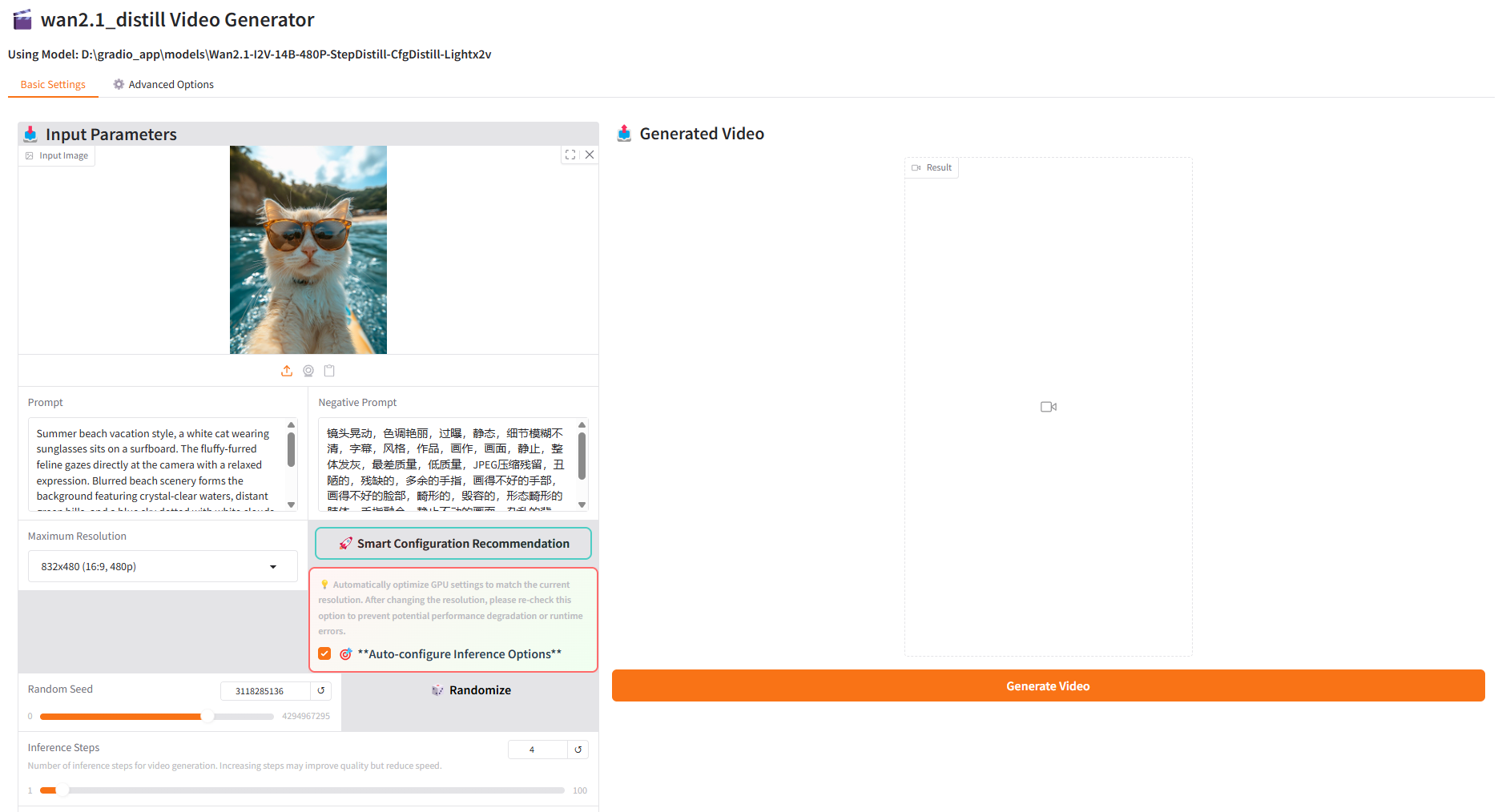
app/gradio_demo.py
100755 → 100644
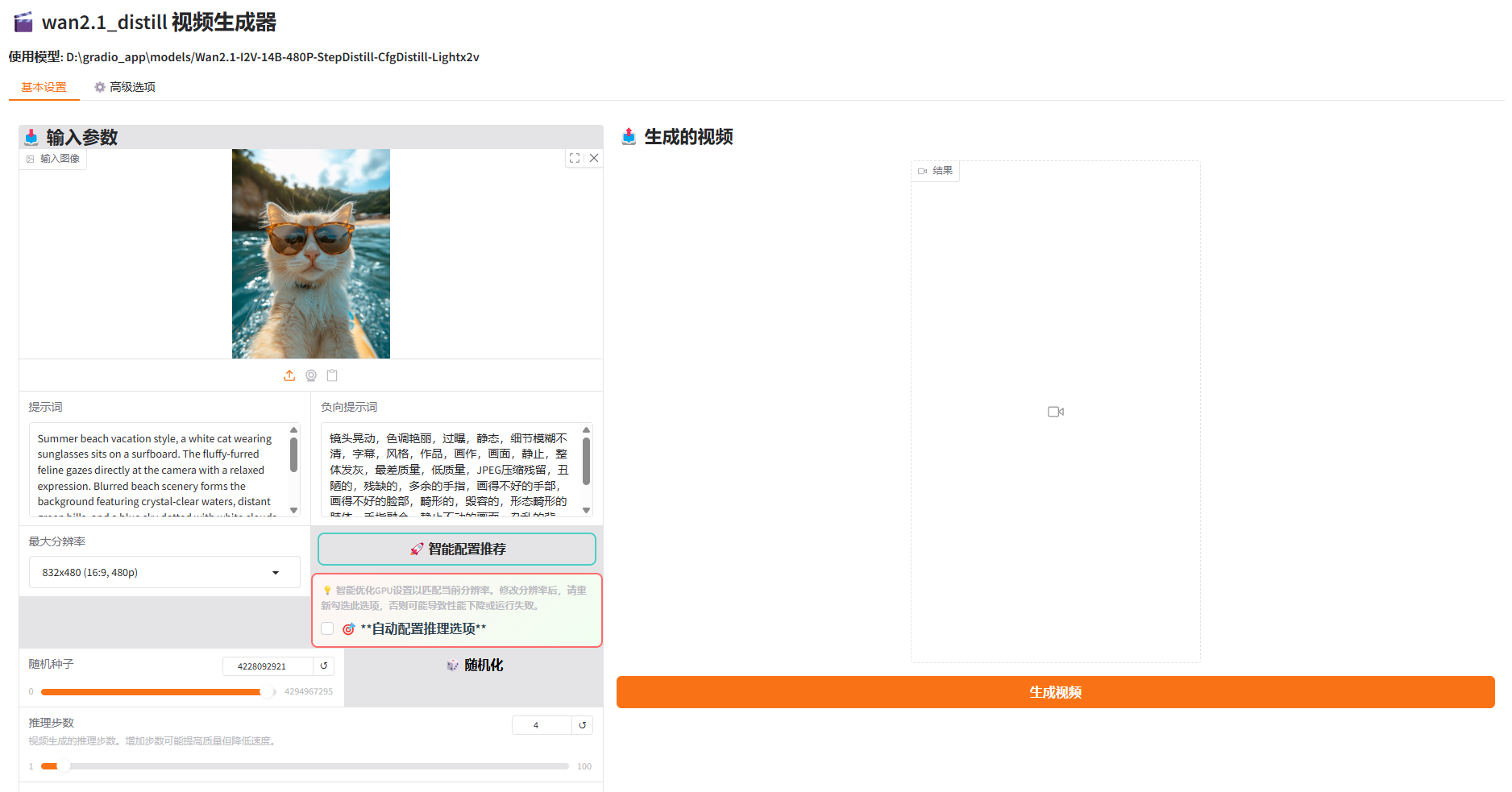
app/gradio_demo_zh.py
100755 → 100644
app/run_gradio.sh
100755 → 100644
{kind=link}
284 KB
{kind=link}
259 KB
docs/EN/source/deploy_guides/deploy_gradio.md
100755 → 100644
docs/ZH_CN/source/deploy_guides/deploy_gradio.md
100755 → 100644