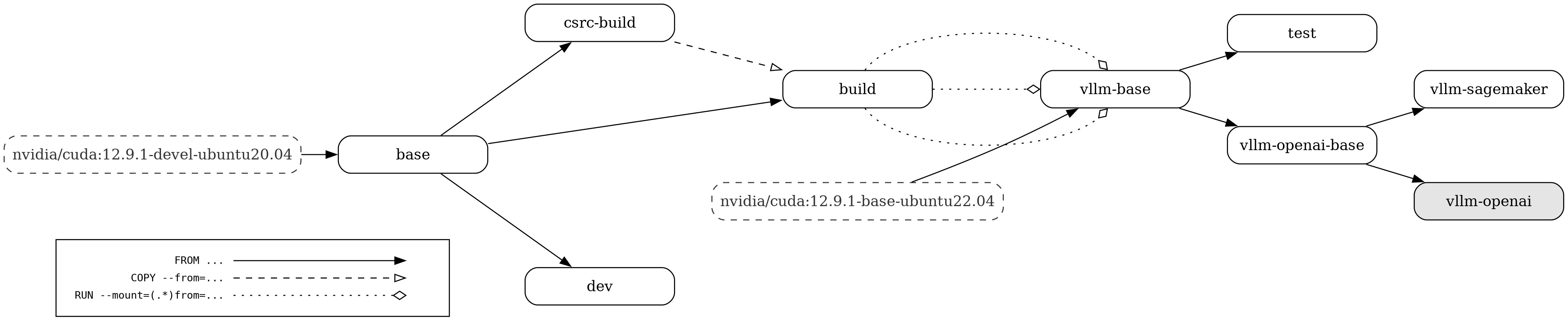
@@ -16,7 +16,7 @@ Async backends support the use of DBO (Dual Batch Overlap) and shared expert ove
Certain models require the topk weights to be applied to the input activations rather than the output activations when topk==1, e.g. Llama. For modular kernels, this feature is supported by the `FusedMoEPrepareAndFinalize` subclass. For non-modular kernels, it is up to the experts function to deal with this flag.
Unless otherwise specified, backends are controlled via `VLLM_ALL2ALL_BACKEND`. All backends except `flashinfer` only work with EP+DP or EP+TP. `Flashinfer` can work with EP or DP without EP.
Unless otherwise specified, backends are controlled via the `--all2all-backend` command-line argument (or the `all2all_backend` parameter in `ParallelConfig`). All backends except `flashinfer` only work with EP+DP or EP+TP. `Flashinfer` can work with EP or DP without EP.
- `init_device`: This function is called to set up the device for the worker.
- `initialize_cache`: This function is called to set cache config for the worker.
- `load_model`: This function is called to load the model weights to device.
- `get_kv_cache_spaces`: This function is called to generate the kv cache spaces for the model.
- `get_kv_cache_spec`: This function is called to generate the kv cache spec for the model.
- `determine_available_memory`: This function is called to profiles the peak memory usage of the model to determine how much memory can be used for KV cache without OOMs.
- `initialize_from_config`: This function is called to allocate device KV cache with the specified kv_cache_config
- `execute_model`: This function is called every step to inference the model.
The `uv` approach works for vLLM `v0.6.6` and later. A unique feature of `uv` is that packages in `--extra-index-url` have [higher priority than the default index](https://docs.astral.sh/uv/pip/compatibility/#packages-that-exist-on-multiple-indexes). If the latest public release is `v0.6.6.post1`, `uv`'s behavior allows installing a commit before `v0.6.6.post1` by specifying the `--extra-index-url`. In contrast, `pip` combines packages from `--extra-index-url` and the default index, choosing only the latest version, which makes it difficult to install a development version prior to the released version.
**Install the latest code**
...
...
@@ -37,7 +51,7 @@ LLM inference is a fast-evolving field, and the latest code may contain bug fixe
The main discussions happen in the `#sig-cpu` channel of [vLLM Slack](https://slack.vllm.ai/).
When open a Github issue about the CPU backend, please add `[CPU Backend]` in the title and it will be labeled with `cpu` for better awareness.
## Requirements
- Python: 3.10 -- 3.13
...
...
@@ -258,11 +264,6 @@ vLLM CPU supports data parallel (DP), tensor parallel (TP) and pipeline parallel
- GPTQ (x86 only)
- compressed-tensor INT8 W8A8 (x86, s390x)
### (x86 only) What is the purpose of `VLLM_CPU_SGL_KERNEL`?
- Both of them require `amx` CPU flag.
-`VLLM_CPU_SGL_KERNEL` can provide better performance for MoE models and small-batch scenarios.
### Why do I see `get_mempolicy: Operation not permitted` when running in Docker?
In some container environments (like Docker), NUMA-related syscalls used by vLLM (e.g., `get_mempolicy`, `migrate_pages`) are blocked/denied in the runtime's default seccomp/capabilities settings. This may lead to warnings like `get_mempolicy: Operation not permitted`. Functionality is not affected, but NUMA memory binding/migration optimizations may not take effect and performance can be suboptimal.
To install the wheel built from the latest main branch:
```bash
uv pip install vllm --extra-index-url https://wheels.vllm.ai/nightly/cpu --index-strategy first-index --torch-backend cpu
```
**Install specific revisions**
If you want to access the wheels for previous commits (e.g. to bisect the behavior change, performance regression), you can specify the commit hash in the URL:
```bash
export VLLM_COMMIT=730bd35378bf2a5b56b6d3a45be28b3092d26519 # use full commit hash from the main branch
uv pip install vllm --extra-index-url https://wheels.vllm.ai/${VLLM_COMMIT}/cpu --index-strategy first-index --torch-backend cpu
```
# --8<-- [end:pre-built-wheels]
# --8<-- [start:build-wheel-from-source]
...
...
@@ -26,10 +70,12 @@ Install recommended compiler. We recommend to use `gcc/g++ >= 12.3.0` as the def
-**NumPy ≥2.0 error**: Downgrade using `pip install "numpy<2.0"`.
-**CMake picks up CUDA**: Add `CMAKE_DISABLE_FIND_PACKAGE_CUDA=ON` to prevent CUDA detection during CPU builds, even if CUDA is installed.
...
...
@@ -95,7 +157,6 @@ uv pip install dist/*.whl
"torch==X.Y.Z+cpu" # <-------
]
```
- If you are building vLLM from source and not using the pre-built images, remember to set `LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libtcmalloc_minimal.so.4:$LD_PRELOAD"` on x86 machines before running vLLM.
On NVIDIA CUDA only, it's recommended to use [uv](https://docs.astral.sh/uv/), a very fast Python environment manager, to create and manage Python environments. Please follow the [documentation](https://docs.astral.sh/uv/#getting-started) to install `uv`. After installing `uv`, you can create a new Python environment using the following commands:
It's recommended to use [uv](https://docs.astral.sh/uv/), a very fast Python environment manager, to create and manage Python environments. Please follow the [documentation](https://docs.astral.sh/uv/#getting-started) to install `uv`. After installing `uv`, you can create a new Python environment using the following commands:
@@ -181,3 +181,4 @@ If you have PRs touching the area, please feel free to ping the area owner for r
- Ascend NPU: [@wangxiyuan](https://github.com/wangxiyuan) and [see more details](https://vllm-ascend.readthedocs.io/en/latest/community/contributors.html#maintainers)
- Intel Gaudi HPU [@xuechendi](https://github.com/xuechendi) and [@kzawora-intel](https://github.com/kzawora-intel)
- Semantic Router: [@xunzhuo](https://github.com/xunzhuo), [@rootfs](https://github.com/rootfs) and [see more details](https://vllm-semantic-router.com/community/team)

{kind=link}
{kind=link}