
merge v0.4.0
Showing
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.
{kind=link}

27 KB
{kind=link}
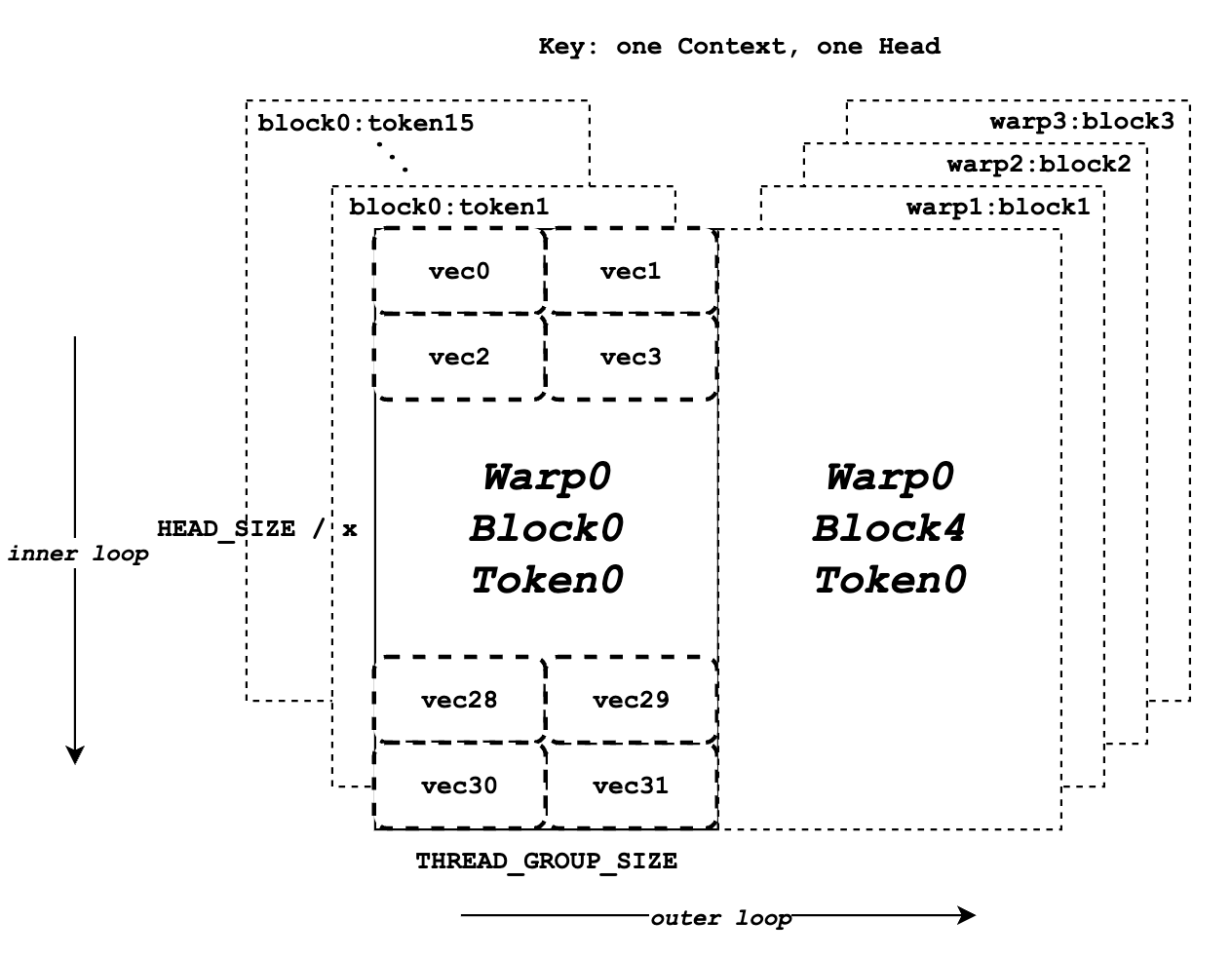
109 KB
{kind=link}

17.1 KB
{kind=link}

41.1 KB
{kind=link}

31.9 KB
{kind=link}
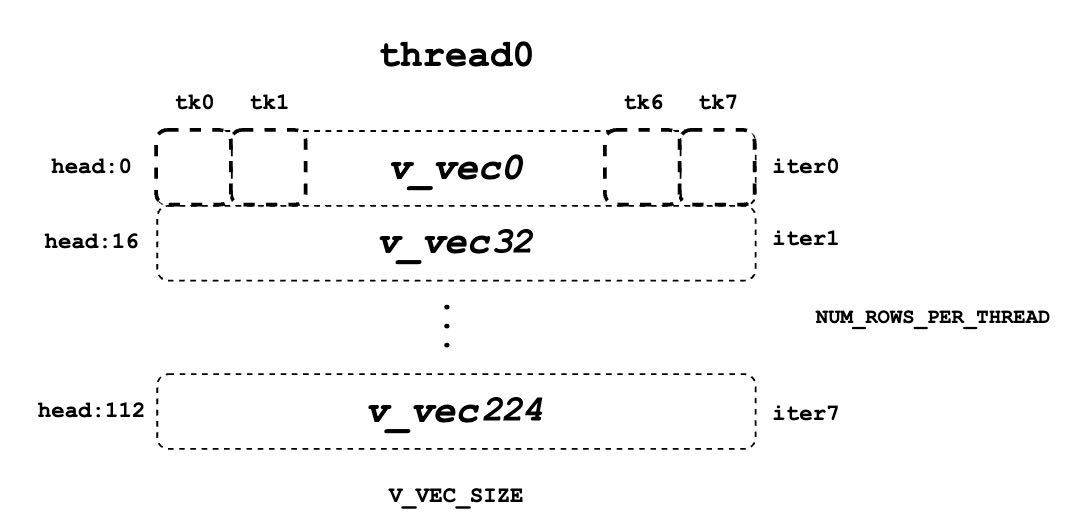
41.5 KB
{kind=link}
This diff is collapsed.
This diff is collapsed.
This diff is collapsed.