Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in
Toggle navigation
Menu
Open sidebar
OpenDAS
vllm_cscc
Commits
1f83e7d8
Unverified
Commit
1f83e7d8
authored
Aug 15, 2025
by
Grace Ho
Committed by
GitHub
Aug 16, 2025
Browse files
[misc] nsys profile output kernel classifier and visualizer (#22971)
Signed-off-by:
Grace Ho
<
grho@nvidia.com
>
parent
e4e37ded
Changes
5
Hide whitespace changes
Inline
Side-by-side
Showing
5 changed files
with
601 additions
and
0 deletions
+601
-0
tools/profiler/nsys_profile_tools/README.md
tools/profiler/nsys_profile_tools/README.md
+175
-0
tools/profiler/nsys_profile_tools/gputrc2graph.py
tools/profiler/nsys_profile_tools/gputrc2graph.py
+426
-0
tools/profiler/nsys_profile_tools/images/csv1.png
tools/profiler/nsys_profile_tools/images/csv1.png
+0
-0
tools/profiler/nsys_profile_tools/images/html.png
tools/profiler/nsys_profile_tools/images/html.png
+0
-0
tools/profiler/nsys_profile_tools/images/html_tbl.png
tools/profiler/nsys_profile_tools/images/html_tbl.png
+0
-0
No files found.
tools/profiler/nsys_profile_tools/README.md
0 → 100644
View file @
1f83e7d8
# gputrc2graph.py
This script processes NVIDIA Nsight Systems (
`nsys`
) GPU trace files
(
`.nsys-rep`
) with -t cuda tracing enabled, and generates kernel-level
summaries and visualizations of GPU and non-GPU time. It is useful for
profiling and analyzing nsys profile output.
## Usage
### Command-line Arguments
-
`--in_file`
**(required)**
List of input files and their metadata. Each entry should be in the format:
`<nsys-rep>,<engine>,<model>,<elapsed_nonprofiled_sec>`
-
`nsys-rep`
: Path to the
`.nsys-rep`
file.
-
`engine`
: Engine name (e.g.,
`vllm`
).
-
`model`
: Model name (e.g.,
`llama`
,
`gpt-oss`
,
`ds`
).
-
`elapsed_nonprofiled_sec`
: Wall-clock runtime (in seconds) without
profiling. Specify
`0`
to use the elapsed time from the nsys-rep file
(this may inflate non-GPU time if actual runtime without profiling is
less). Multiple entries can be provided, separated by spaces.
-
`--out_dir`
Output directory for the generated CSV and HTML files.
If not specified, results are saved in the current directory.
-
`--title`
Title for the HTML chart/visualization.
-
`--nsys_cmd`
Path to the
`nsys`
command.
Default:
`nsys`
(assumes it is in your PATH).
Use this if
`nsys`
is not in your system PATH.
## Notes
-
Make sure you have pandas installed.
-
Make sure nsys is installed, and specify the path to the
`nsys`
command with
`--nsys_cmd`
if it is not in your PATH.
-
For more details on available engines and models, see the help string in
the script or run:
```
bash
python3 gputrc2graph.py
--help
```
## Example 1: analyze a single profile
To analyze the GPU cycles for say, gpt-oss model with vLLM engine:
1.
Run the following command to collect nsys profile, for vllm serve config.
```
bash
nsys profile
-t
cuda
-o
run1
-f
true
--trace-fork-before-exec
=
true
\
--cuda-graph-trace
=
node
--delay
<DELAY>
--duration
<DURATION>
\
vllm serve openai/gpt-oss-120b ...
```
where:
-
DELAY: how many seconds to delay nsys from collecting profiles, needed so
that profiles aren't captured till vllm server has come up and load
generation starts.
-
DURATION: how many seconds for nsys profile to run before generating the
profile. This should be > the duration of the run.
2.
Run again, this time without collecting the profile, and get the total run
time in seconds. This value will be used by the script to calculate the
CPU(non-GPU) seconds for the analysis.
3.
Say the run elapsed time is 306 seconds, from step #2. Run script to
analyze:
```
bash
python3 gputrc2graph.py
\
--in_file
run1.nsys-rep,vllm,gpt-oss,306
\
--title
"vLLM-gpt-oss profile"
```
The command will produce 2 files for analysis:
-
result.html: this categorizes kernel names into different categories in a
stacked bar chart.
-
result.csv: shows how the kernel names are mapped to the different
categories.
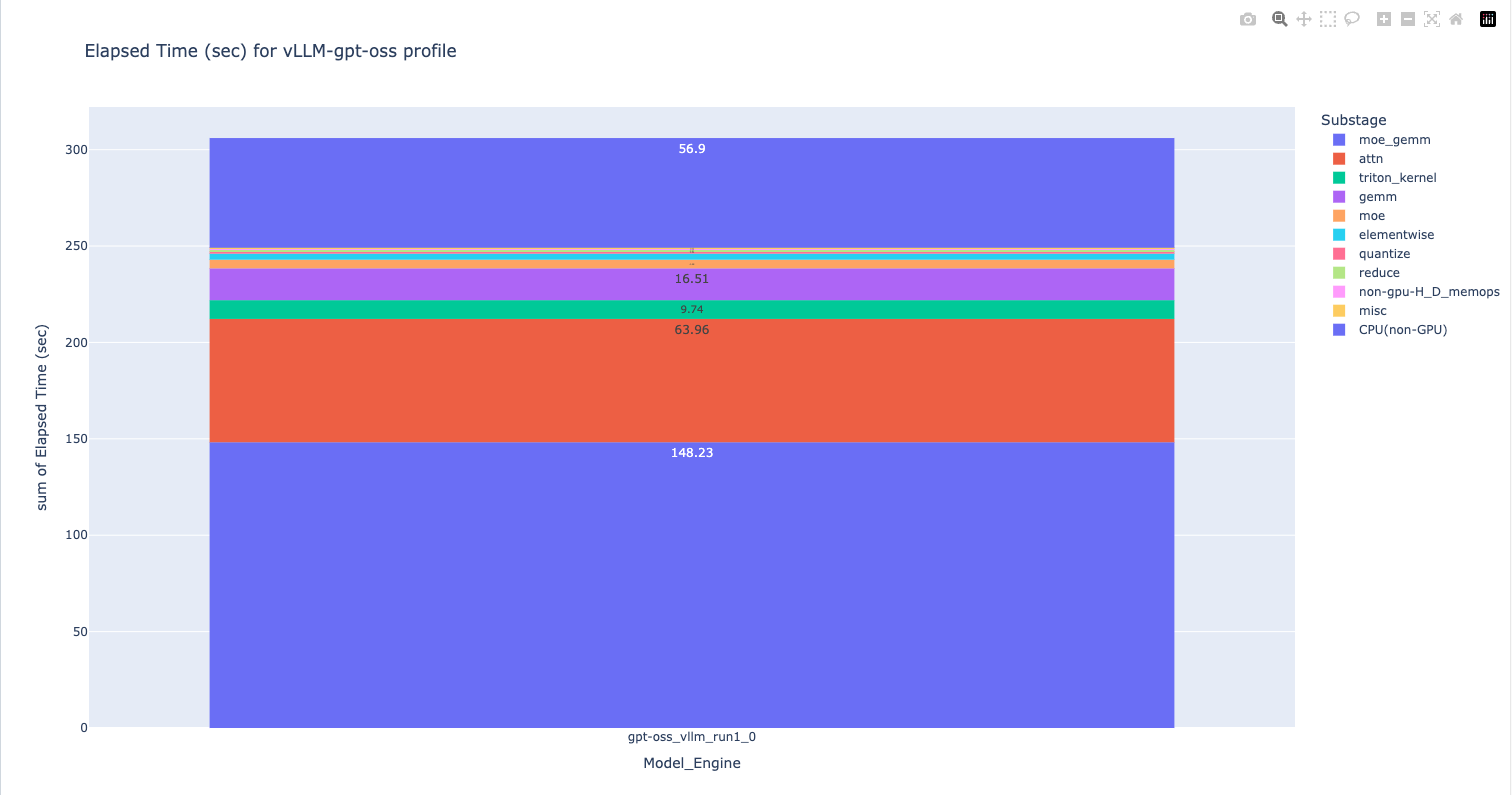
### HTML visualization with result.html
The html file shows the number of elapsed seconds due to different GPU
Substages or categories, which consist of moe_gemm (Mixture of Experts GEMM)
kernels the biggest category, at 148 seconds, followed by "attn" or attention
kernels. This lets the user prioritize the kernels to focus on for performance
optimizations.

There's also an appended data table underneath the bar chart for copying out to other post-processing tools.

### Kernel to category mapping with result.csv
Suppose the user would like to focus on improving triton kernels. It's not the
biggest consumer of cycles at 9.74 sec but perhaps it hasn't been optimized.
The next step is to use the result.csv to dive into what the kernels are which
compose the triton kernel GPU cycles. The following image shows that
triton_poi_fused__to_copy_add_addmm_cat_.. kernel to be the biggest
contributor to GPU cycles.

## Example 2: analyze multiple profiles
Suppose the user has multiple nsys trace files, captured for different models,
say llama and gpt-oss in this case, and wish to compare their GPU/non-GPU
time, something like the following command can be used.
```
bash
python3 gputrc2graph.py
\
--in_file
run1.nsys-rep,vllm,llama,100 run2.nsys-rep,vllm,gpt-oss,102
\
--out_dir
results
\
--title
"Comparison of vLLM Models"
```
The analysis process is similar to example 1 but now there will be multiple
stack bar charts that can be compared. The categories for the different
kernels will remain the same, so that it's easy to compare the GPU cycles for
the same categories.
Once a category is shown to have more cycles for one configuration than
another, the next step would be to use the csv file to see what kernels are
mapped into that category, and which kernels are taking the largest amount of
time which would cause a difference for the overall category.
## Example 3: add new classification for a new model
Suppose there's a new model ABC that is available for engine DEF, and say there
are 4 kernels to be classified into "gemm" and "attn", where the gemm kernels
have names with "
*H*
" or "
*I*
" in them, and attn kernels have names with "
*J*
"
or "
*K*
" in them, add a new entry like so:
```
python
engine_model
=
{
'DEF'
:
{
'ABC'
:
{
'layer_anno'
:
{
'Stage'
:
{
'.*'
:
'layer'
,
},
'Substage'
:
{
'H|I'
:
'gemm'
,
'J|K'
:
'attn'
,
'CUDA mem'
:
'non-gpu-H_D_memops'
,
'.*'
:
'misc'
}
}
},
}
'vllm'
:
{...}
```
Basically Substage is a dictionary with a list of key/value pairs, where the
keys are regex's of the kernel names to be classified, and values are the
classification bins which one wishes to compare across engines/models.
The last 2 entries are common for all engine/models, consisting of CUDA memory
operations and a 'misc' for anything that's leftover and can't be classified.
When invoking gputrc2graph.py, specify a trace file with this new model/engine
like the following:
```
bash
--infile
new.nsys-rep,DEF,ABC,<runtime>
```
tools/profiler/nsys_profile_tools/gputrc2graph.py
0 → 100755
View file @
1f83e7d8
# SPDX-License-Identifier: Apache-2.0
# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
"""
This generates gpu kernel analysis output from nsys rep. Will call nsys
stats -r cuda_gpu_kern_trace, get non-overlapped gpu cycles, then generate
csv and html output for analysis
"""
import
argparse
import
logging
import
os
import
regex
as
re
logger
=
logging
.
getLogger
(
__name__
)
# helper data class for annotating kernels
class
EngineModelData
:
# engine + model mappings
engine_model
=
{
'vllm'
:
{
'llama'
:
{
'layer_anno'
:
{
'Stage'
:
{
'.*'
:
'layer'
,
},
'Substage'
:
{
'gemm'
:
'gemm'
,
'fused_moe_kernel|GroupProblemShape|group_gemm_starts'
:
'moe_gemm'
,
#llama4
'moe|sigmoid'
:
'moe'
,
#llama4
'CatArrayBatched|prepare_inputs'
:
'prepare_next'
,
'flash'
:
'attn'
,
'ncclDevKernel|cross_device_reduce'
:
'nccl_and_custom_ar'
,
'_norm_'
:
'norm'
,
'act_and_mul_'
:
'silu'
,
'rotary_embedding_kernel'
:
'rope'
,
'SoftMax'
:
'softmax'
,
'elementwise'
:
'elementwise'
,
'fp8_quant'
:
'quantize'
,
'reduce_kernel'
:
'reduce'
,
'triton'
:
'triton_kernel'
,
'CUDA mem'
:
'non-gpu-H_D_memops'
,
'.*'
:
'misc'
}
}
},
'ds'
:
{
'layer_anno'
:
{
'Stage'
:
{
'.*'
:
'layer'
,
},
'Substage'
:
{
'block_fp8|gemm_fp8_blockwise'
:
'block_fp8_gemm'
,
'fused_moe_kernel|_group_gemm|GroupProblemShape|GemmUniversal'
:
'moe_gemm'
,
'gemm|matmul|nvjet'
:
'gemm'
,
'moe|sigmoid|expert'
:
'moe'
,
'_fwd_|FlashAttn|_mla_|_attn_'
:
'attn'
,
'CatArrayBatched'
:
'prepare_next'
,
'ncclDevKernel|cross_device_reduce'
:
'nccl_and_custom_ar'
,
'Norm|_norm_'
:
'norm'
,
'sbtopk'
:
'topk'
,
'act_and_mul_'
:
'activation'
,
'compute_position_kernel'
:
'rope'
,
'elementwise'
:
'elementwise'
,
'fp8_quant|quant_fp8|cvt_fp16_to_fp4'
:
'quantize'
,
'reduce'
:
'reduce'
,
'SoftMax'
:
'softmax'
,
'triton'
:
'triton_kernel'
,
'CUDA mem'
:
'non-gpu-H_D_memops'
,
'.*'
:
'misc'
}
}
},
'gpt-oss'
:
{
'layer_anno'
:
{
'Stage'
:
{
'.*'
:
'layer'
,
},
'Substage'
:
{
'block_fp8|gemm_fp8_blockwise'
:
'block_fp8_gemm'
,
'fused_moe_kernel|_group_gemm|GroupProblemShape|GemmUniversal|bmm_'
# this section is triton_moe_gemm
'|matmul_ogs_|_topk_forward|_combined_routing'
'|_sum_bitmatrix_rows|_compute_writeback_idx'
:
'moe_gemm'
,
'gemm|matmul|nvjet'
:
'gemm'
,
'moe|sigmoid|expert|splitKreduce'
:
'moe'
,
'_fwd_|FlashAttn|_mla_|_attn_|_flash_|flash::prepare_varlen|fmha'
:
'attn'
,
'CatArrayBatched'
:
'prepare_next'
,
'ncclDevKernel|cross_device_reduce'
:
'nccl_and_custom_ar'
,
'Norm|_norm_'
:
'norm'
,
'sbtopk'
:
'topk'
,
'act_and_mul_'
:
'activation'
,
'compute_position_kernel'
:
'rope'
,
'elementwise'
:
'elementwise'
,
'fp8_quant|quant_fp8|cvt_fp16_to_fp4|quantize'
:
'quantize'
,
'reduce'
:
'reduce'
,
'SoftMax'
:
'softmax'
,
'triton'
:
'triton_kernel'
,
'CUDA mem'
:
'non-gpu-H_D_memops'
,
'.*'
:
'misc'
}
}
}
},
}
class
GPUTrace2Graph
:
"""
Parses output of nsys report, generates csv and bar chart output
"""
def
__init__
(
self
,
nsys_cmd
):
self
.
nsys_cmd
=
nsys_cmd
import
pandas
as
pd
# avoid importing till needed
self
.
pd
=
pd
self
.
pd
.
options
.
mode
.
copy_on_write
=
True
# helper functions for generating trace->summary csvs
def
gen_nonoverlapped_sum_from_gputrace
(
self
,
in_file
,
out_file
):
logger
.
info
(
'loading %s'
,
in_file
)
df
=
self
.
pd
.
read_csv
(
in_file
,
usecols
=
[
'Start (ns)'
,
'Duration (ns)'
,
'Device'
,
'Strm'
,
'Name'
])
df
[
'End (ns)'
]
=
df
[
'Start (ns)'
]
+
df
[
'Duration (ns)'
]
df
=
self
.
sum_non_overlapping_intervals
(
df
)
# get ready to print table with elapsed times per kernel
df
[
'Instances'
]
=
1
df_sum
=
df
.
groupby
(
'Name'
,
as_index
=
False
).
agg
({
'Elapsed Time (ns)'
:
'sum'
,
'Duration (ns)'
:
'sum'
,
'Instances'
:
'size'
})
# generate csv
df_sum
[
'Total Time (sec)'
]
=
df_sum
[
'Duration (ns)'
]
/
1e9
df_sum
[
'Elapsed Time (sec)'
]
=
df_sum
[
'Elapsed Time (ns)'
]
/
1e9
df_sum
=
df_sum
.
sort_values
(
by
=
'Elapsed Time (sec)'
,
ascending
=
False
)
df_sum
[[
'Elapsed Time (sec)'
,
'Total Time (sec)'
,
'Instances'
,
'Name'
]].
to_csv
(
out_file
,
index
=
False
)
def
sum_non_overlapping_intervals
(
self
,
df
):
"""
returns new sorted df with Elapsed Time (ns) column using
vectorized operations
"""
logger
.
info
(
"sorting %s trace records by start time"
,
str
(
df
.
shape
))
# Sort by start time and reset index
df
=
df
.
sort_values
(
by
=
'Start (ns)'
).
reset_index
(
drop
=
True
)
# Initialize elapsed time as duration
df
[
'Elapsed Time (ns)'
]
=
df
[
'Duration (ns)'
]
# Get numpy arrays for faster operations
starts
=
df
[
'Start (ns)'
].
values
ends
=
df
[
'End (ns)'
].
values
# Keep track of current interval end
current_end
=
ends
[
0
]
display_units
=
int
(
len
(
df
)
/
100
)
# Update current_end for overlapping intervals
for
i
in
range
(
1
,
len
(
df
)):
if
i
%
display_units
==
0
:
print
(
f
'processing trace:
{
int
(
i
/
len
(
df
)
*
100
)
}
%'
,
end
=
"
\r
"
)
if
starts
[
i
]
<=
current_end
:
if
ends
[
i
]
>
current_end
:
# Partial overlap
df
.
iloc
[
i
,
df
.
columns
.
get_loc
(
'Elapsed Time (ns)'
)]
=
ends
[
i
]
-
current_end
current_end
=
ends
[
i
]
else
:
# Complete overlap
df
.
iloc
[
i
,
df
.
columns
.
get_loc
(
'Elapsed Time (ns)'
)]
=
0
else
:
# No overlap
current_end
=
ends
[
i
]
return
df
# functions for generating html files
def
make_html
(
self
,
df
,
output_dir
,
title
):
""" make html graph from df """
import
plotly.express
as
px
if
df
.
empty
:
return
output_name
=
output_dir
+
'/result'
if
not
title
:
title
=
'Model_Engine'
x
=
'Model_Engine'
y
=
'Elapsed Time (sec)'
color
=
'Substage'
""" generate kernel mapping table """
# Sort Model_Engine categories by last field after underscore
df
[
'Model_Engine'
]
=
self
.
pd
.
Categorical
(
df
[
'Model_Engine'
],
sorted
(
df
[
'Model_Engine'
].
unique
(),
key
=
lambda
x
:
x
.
split
(
'_'
)[
-
1
]))
df
[[
'Model_Engine'
,
color
,
'Instances'
,
'Name'
,
y
]].
sort_values
(
by
=
color
).
to_csv
(
f
'
{
output_name
}
.csv'
,
index
=
False
)
graph
=
px
.
histogram
(
df
.
round
(
2
),
x
=
x
,
y
=
y
,
title
=
(
f
'
{
y
}
for
{
title
}
'
),
color
=
color
,
text_auto
=
True
)
# wrap x axis labels
graph
.
update_xaxes
(
automargin
=
True
)
graph
.
write_html
(
f
'
{
output_name
}
.html'
)
"""
Generate data table with columns per Model_Engine into result.html
"""
pivot_df
=
df
.
pivot_table
(
values
=
'Elapsed Time (sec)'
,
index
=
'Substage'
,
columns
=
'Model_Engine'
,
aggfunc
=
'sum'
,
observed
=
False
).
round
(
2
)
# Add sum row at bottom
pivot_df
.
loc
[
'total_elapsed_sec'
]
=
pivot_df
.
sum
()
pivot_df
.
fillna
(
''
).
to_html
(
'temp.html'
)
print
(
'got'
)
with
(
open
(
f
'
{
output_name
}
.html'
,
'a'
,
encoding
=
'utf-8'
)
as
outfile
,
open
(
'temp.html'
,
encoding
=
'utf-8'
)
as
infile
):
outfile
.
write
(
infile
.
read
())
os
.
remove
(
'temp.html'
)
print
(
f
'Finished generating:
\n
'
f
'
{
output_name
}
.html for stack bar chart
\n
'
f
'
{
output_name
}
.csv for Kernel-Substage mapping'
)
def
anno_gpu_kernname
(
self
,
df
,
mapping
):
""" add "stage" and "substage" columns """
def
anno_gpu_kernname_helper
(
name
,
stage
):
for
kern_name
,
val
in
mapping
[
'layer_anno'
][
stage
].
items
():
if
re
.
search
(
kern_name
,
name
):
return
val
for
stage
in
[
'Stage'
,
'Substage'
]:
df
[
stage
]
=
df
[
'Name'
].
apply
(
anno_gpu_kernname_helper
,
stage
=
stage
)
def
make_nongpu_row
(
self
,
df
,
nongpu_sec
):
""" this will append non-gpu time entry at end of df """
nongpu_row
=
self
.
pd
.
DataFrame
([
df
.
iloc
[
-
1
]])
nongpu_row
[
'Substage'
]
=
nongpu_row
[
'Name'
]
=
'CPU(non-GPU)'
nongpu_row
[
'Instances'
]
=
1
nongpu_row
[
'Elapsed Time (sec)'
]
=
nongpu_sec
return
(
nongpu_row
)
def
is_valid_file
(
self
,
base_file
):
""" asserts if base_file is non-existent or is empty """
assert
os
.
path
.
isfile
(
base_file
)
and
os
.
path
.
getsize
(
base_file
)
>
0
,
\
f
"
{
base_file
}
doesn't exist or is empty"
def
should_gen_file
(
self
,
new_file
,
base_file
):
""" figure out if new file should be generated from base_file """
self
.
is_valid_file
(
base_file
)
if
(
os
.
path
.
exists
(
new_file
)
and
(
os
.
path
.
getmtime
(
new_file
)
>
os
.
path
.
getmtime
(
base_file
))
and
(
os
.
path
.
getsize
(
base_file
)
>
0
)):
logger
.
info
(
'reusing %s'
,
new_file
)
return
False
else
:
logger
.
info
(
'generating %s'
,
new_file
)
return
True
def
gen_sum_file
(
self
,
file
):
"""
generates sum file from nsys trace with times per kernel and
returns the name of the sum file
"""
import
subprocess
file_dir
=
os
.
path
.
dirname
(
file
)
file_name
=
os
.
path
.
basename
(
file
)
if
not
file_dir
:
file_dir
=
'.'
# Walk through trace and get the total non-overlapped time
nsys_stats_file
=
f
'
{
file_dir
}
/
{
file_name
}
_cuda_gpu_trace.csv'
sum_file
=
f
'
{
file_dir
}
/
{
file_name
}
_cuda_gpu_kernel_tracesum.csv'
if
self
.
should_gen_file
(
nsys_stats_file
,
file
):
cmd
=
[
self
.
nsys_cmd
,
'stats'
,
'-r'
,
'cuda_gpu_trace'
,
file
,
'-o'
,
f
'
{
file_dir
}
/
{
file_name
}
'
]
cmd_str
=
' '
.
join
(
cmd
)
logger
.
info
(
'+ %s'
,
cmd_str
)
try
:
subprocess
.
run
(
cmd
)
except
Exception
:
logger
.
error
(
"%s failed, specify --nsys_cmd for correct nsys path"
,
cmd_str
)
exit
(
1
)
logger
.
info
(
'generating non-overalapped sum %s'
,
sum_file
)
self
.
gen_nonoverlapped_sum_from_gputrace
(
nsys_stats_file
,
sum_file
)
self
.
is_valid_file
(
sum_file
)
logger
.
info
(
'Finished generating %s'
,
sum_file
)
return
sum_file
def
gen_graph
(
self
,
in_file
,
out_dir
,
title
):
""" generates graph and csv file from in_file into out_dir """
# Initialize an empty DataFrame to store combined data
combined_df
=
self
.
pd
.
DataFrame
()
for
idx
,
(
file
,
engine
,
model
,
total_sec
)
in
enumerate
(
in_file
):
file_dir
=
os
.
path
.
dirname
(
file
)
file_name
=
os
.
path
.
basename
(
file
)
if
not
file_dir
:
file_dir
=
'.'
sum_file
=
self
.
gen_sum_file
(
file
)
# read kernel summary file
df
=
self
.
pd
.
read_csv
(
sum_file
)
# annotate kernel to their categories
assert
EngineModelData
.
engine_model
.
get
(
engine
)
assert
EngineModelData
.
engine_model
[
engine
].
get
(
model
)
# remove nsys-rep from file_name for shorter x-label
file_name
=
file_name
.
replace
(
'.nsys-rep'
,
''
)
df
[
'Model_Engine'
]
=
f
'
{
model
}
_
{
engine
}
_
{
file_name
}
_
{
idx
}
'
self
.
anno_gpu_kernname
(
df
,
EngineModelData
.
engine_model
[
engine
][
model
])
# patch in non-gpu time
gpu_sec
=
round
(
df
[
'Elapsed Time (sec)'
].
sum
(),
1
)
total_sec
=
round
(
float
(
total_sec
),
1
)
if
total_sec
<
gpu_sec
:
logger
.
warning
(
"Elapsed sec %.2f < GPU sec %.2f resetting Elapsed sec "
,
total_sec
,
gpu_sec
,
)
total_sec
=
gpu_sec
nongpu_row
=
self
.
make_nongpu_row
(
df
,
total_sec
-
gpu_sec
)
df
=
self
.
pd
.
concat
([
df
,
nongpu_row
],
ignore_index
=
True
)
combined_df
=
self
.
pd
.
concat
([
combined_df
,
df
],
ignore_index
=
True
)
if
out_dir
is
None
:
out_dir
=
'.'
else
:
os
.
makedirs
(
out_dir
,
exist_ok
=
True
)
# generate html file
self
.
make_html
(
combined_df
,
out_dir
,
title
)
def
parse_tuple
(
s
):
return
tuple
(
s
.
split
(
','
))
def
main
():
logging
.
basicConfig
(
format
=
(
'%(asctime)s - %(levelname)s - %(message)s'
),
level
=
logging
.
INFO
)
parser
=
argparse
.
ArgumentParser
(
description
=
(
'Process nsys rep and generate kernel non-overlapped cycles.
\n
'
'Example:
\n
'
"gputrc2graph.py --in_file d1.nsys-rep,vllm,llama,100
\n
"
"d2.nsys-rep,vllm,gpt-oss,102 "
"--out_dir results/ --title
\"
Model=gpt-oss vLLM chart
\"
"
),
formatter_class
=
argparse
.
RawDescriptionHelpFormatter
)
# Build help string showing available engine/model combinations
engine_model_help
=
[]
for
engine
,
models
in
EngineModelData
.
engine_model
.
items
():
model_list
=
list
(
models
.
keys
())
engine_model_help
.
append
(
f
"
{
engine
}
:[
{
','
.
join
(
model_list
)
}
]"
)
engine_model_str
=
' '
.
join
(
engine_model_help
)
parser
.
add_argument
(
'--in_file'
,
type
=
parse_tuple
,
nargs
=
'+'
,
help
=
(
'list of (nsys-rep, engine, model, elapsed_nonprofiled_sec) '
'separated by space. Elapsed_nonprofiled_sec is runtime without '
'profiling used to calculate non-gpu time. Specify 0 to use '
'elapsed time from nsys-rep but that might inflate non-gpu time. '
f
'Available engine:[model] are:
{
engine_model_str
}
'
f
'Example: --infile d1.nsys-rep,vllm,llama,100 '
'd2.nsys-rep,vllm,gpt-oss,102'
),
required
=
True
)
parser
.
add_argument
(
'--out_dir'
,
help
=
(
'output dir for result.csv/html'
))
parser
.
add_argument
(
'--title'
,
help
=
(
'title for html chart'
))
parser
.
add_argument
(
'--nsys_cmd'
,
help
=
(
'nsys cmd, e.g. /usr/bin/nsys, Default: nsys'
),
default
=
"nsys"
)
args
=
parser
.
parse_args
()
gputrace
=
GPUTrace2Graph
(
args
.
nsys_cmd
)
gputrace
.
gen_graph
(
args
.
in_file
,
args
.
out_dir
,
args
.
title
)
if
__name__
==
'__main__'
:
main
()
tools/profiler/nsys_profile_tools/images/csv1.png
0 → 100644
View file @
1f83e7d8
145 KB
tools/profiler/nsys_profile_tools/images/html.png
0 → 100644
View file @
1f83e7d8
70.5 KB
tools/profiler/nsys_profile_tools/images/html_tbl.png
0 → 100644
View file @
1f83e7d8
35.8 KB
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

 Grace Ho <grho@nvidia.com>
Grace Ho <grho@nvidia.com>{kind=link}

{kind=link}
{kind=link}
 Grace Ho <grho@nvidia.com>
Grace Ho <grho@nvidia.com>