- 12 Oct, 2023 1 commit
-
-
moto-meta authored
Differential Revision: D50086556 Pull Request resolved: https://github.com/pytorch/audio/pull/3648
-
- 09 Oct, 2023 1 commit
-
-
moto-meta authored
Differential Revision: D49965263 Pull Request resolved: https://github.com/pytorch/audio/pull/3639
-
- 02 Oct, 2023 1 commit
-
-
moto authored
Taken from https://github.com/pytorch/audio/pull/3234
-
- 13 Sep, 2023 1 commit
-
-
moto authored
-
- 30 Aug, 2023 1 commit
-
-
atalman authored
Summary: This reverts commit c5939616. Unblock 2.1.0 rc Pull Request resolved: https://github.com/pytorch/audio/pull/3586 Reviewed By: osalpekar Differential Revision: D48842032 Pulled By: atalman fbshipit-source-id: bbdf9e45c9aa5fde00f315a2ff491ed050bc1707
-
- 19 Aug, 2023 1 commit
-
-
Juan Villamizar authored
Summary: Added HIPIFY code and small changes for ROCm. Targeting RNN-T loss. Pull Request resolved: https://github.com/pytorch/audio/pull/2485 Reviewed By: huangruizhe Differential Revision: D43537864 Pulled By: mthrok fbshipit-source-id: 4bdb1f291dc51a12232ccd072b97ae94ae20cc0c
-
- 02 Jun, 2023 1 commit
-
-
moto authored
Summary: This commit removes compute_kaldi_pitch function and the underlying Kaldi integration from torchaudio. Kaldi pitch function was added in a short period of time by integrating the original Kaldi implementation, instead of reimplementing it in PyTorch. The Kaldi integration employed a hack which replaces the base vector/matrix implementation of Kaldi with PyTorch Tensor so that there is only one blas library within torchaudio. Recently, we are making torchaudio more lean, and we don't see a wide adoption of kaldi_pitch feature, so we decided to remove them. See some of the discussion https://github.com/pytorch/audio/issues/1269 Pull Request resolved: https://github.com/pytorch/audio/pull/3368 Differential Revision: D46406176 Pulled By: mthrok fbshipit-source-id: ee5e24d825188f379979ddccd680c7323b119b1e
-
- 20 May, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3348 The pull request adds a CTC-based forced alignment function that supports both CPU and CUDA deviced. The function takes the CTC emissions and target labels as inputs and generates the corresponding labels for each frame. Reviewed By: vineelpratap, xiaohui-zhang Differential Revision: D45867265 fbshipit-source-id: 3e25b06bf9bc8bb1bdcdc08de7f4434d912154cb
-
- 14 Feb, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: replicate of https://github.com/pytorch/audio/issues/2644 Pull Request resolved: https://github.com/pytorch/audio/pull/2880 Reviewed By: mthrok Differential Revision: D41633911 Pulled By: nateanl fbshipit-source-id: 73cf145d75c389e996aafe96571ab86dc21f86e5
-
- 04 Feb, 2023 1 commit
-
-
Chin-Yun Yu authored
Summary: close https://github.com/pytorch/audio/issues/1408 . Pull Request resolved: https://github.com/pytorch/audio/pull/3018 Reviewed By: xiaohui-zhang Differential Revision: D42961853 Pulled By: mthrok fbshipit-source-id: b9f847986e0afe416e7817ce4790e42cc0f83ee1
-
- 29 Dec, 2022 2 commits
-
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2930 Reviewed By: carolineechen, nateanl Differential Revision: D42280966 Pulled By: mthrok fbshipit-source-id: f9d5f1dc7c1a62d932fb2020aafb63734f2bf405
-
moto authored
Summary: * move helper functions to `detail` namespace. * move helper functions out of `buffer.h` Pull Request resolved: https://github.com/pytorch/audio/pull/2943 Reviewed By: carolineechen Differential Revision: D42271652 Pulled By: mthrok fbshipit-source-id: abbfc8e8bac97d4eeb34221d4c20763477bd982e
-
- 27 Dec, 2022 1 commit
-
-
moto authored
Summary: The `Buffer` class is responsible for converting `AVFrame` into `torch::Tensor` and storing the frames in accordance to `frames_per_chunk` and `buffer_chunk_size`. There are four operating modes of Buffer; [audio|video] x [chunked|unchunked]. Audio and video have a separate class implementations, but the behavior of chunked/unchunked depends on `frames_per_chunk<0` or not. Chunked mode is where frames should be returned by chunk of a unit number frames, while unchunked mode is where frames are returned as-is. When frames are accumulated, in chunked mode, old frames are dropped, while in unchunked mode all the frames are retained. Currently, the underlying buffer implementations are the same `std::dequeu<torch::Tensor>`. As we plan to make chunked-mode behavior more efficient by changing the underlying buffer container, it will be easier if the unchuked-mode behavior is kept as-is as a separate class. This commit makes the following changes. * Change `Buffer` class into pure virtual class (interface). * Split `AudioBuffer` into` UnchunkedAudioBuffer` and `ChunkedAudioBuffer`. * Split `VideoBuffer` into` UnchunkedVideoBuffer` and `ChunkedVideoBuffer`. Pull Request resolved: https://github.com/pytorch/audio/pull/2939 Reviewed By: carolineechen Differential Revision: D42247509 Pulled By: mthrok fbshipit-source-id: 7363e442a5b2db5dcbaaf0ffbfa702e088726d1b
-
- 21 Dec, 2022 1 commit
-
-
moto authored
Summary: This commit makes the following changes to the C++ library organization - Move sox-related feature implementations from `libtorchaudio` to `libtorchaudio_sox`. - Remove C++ implementation of `is_sox_available` and `is_ffmpeg_available` as it is now sufficient to check the existence of `libtorchaudio_sox` and `libtorchaudio_ffmpeg` to check the availability. This makes `libtorchaudio_sox` and `libtorchaudio_ffmpeg` independent from `libtorchaudio`. - Move PyBind11-based bindings (`_torchaudio_sox`, `_torchaudio_ffmpeg`) into `torchaudio.lib` so that the built library structure is less cluttered. Background: Originally, when the `libsox` was the only C++ extension and `libtorchaudio` was supposed to contain all the C++ code. The things are different now. We have a bunch of C++ extensions and we need to make the code/build structure more modular. The new `libtorchaudio_sox` contains the implementations and `_torchaudio_sox` contains the PyBin11-based bindings. Pull Request resolved: https://github.com/pytorch/audio/pull/2929 Reviewed By: hwangjeff Differential Revision: D42159594 Pulled By: mthrok fbshipit-source-id: 1a0fbca9e4143137f6363fc001b2378ce6029aa7
-
- 21 Sep, 2022 1 commit
-
-
moto authored
Summary: In https://github.com/pytorch/audio/issues/2694 CMakeLists.txt was not properly updated, so the tests are failing. This commit fix it. Pull Request resolved: https://github.com/pytorch/audio/pull/2699 Reviewed By: carolineechen Differential Revision: D39687409 Pulled By: mthrok fbshipit-source-id: 2e14f3c478f1f8a112a03839f2dbcca51215fed7
-
- 01 Sep, 2022 1 commit
-
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2648 Reviewed By: nateanl Differential Revision: D38976874 Pulled By: mthrok fbshipit-source-id: 0541dea2a633d97000b4b8609ff6b83f6b82c864
-
- 24 Aug, 2022 1 commit
-
-
moto authored
Summary: This commit adds FFmpeg-based encoder StreamWriter class. StreamWriter is pretty much the opposite of StreamReader class, and it supports; * Encoding audio / still image / video * Exporting to local file / streaming protocol / devices etc... * File-like object support (in later commit) * HW video encoding (in later commit) See also: https://fburl.com/gslide/z85kn5a9 (Meta internal) Pull Request resolved: https://github.com/pytorch/audio/pull/2628 Reviewed By: nateanl Differential Revision: D38816650 Pulled By: mthrok fbshipit-source-id: a9343b0d55755e186971dc96fb86eb52daa003c8
-
- 19 Aug, 2022 1 commit
-
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2636 At the early stage of torchaudio extension module, `torchaudio/csrc/pybind` directory was created so that all the code defining Python interface would be placed there and there will be only one extension module called `torchaudio._torchaudio`. However, the codebase has been evolved in a way separate extensions are defined for each feature (third party dependency) for the sake of more moduler file organization. What is left in `csrc/pybind` is libsox Python bindings. This commit moves it under `csrc/sox`. Follow-up rename `torchaudio._torchaudio` to `torchaudio._torchaudio_sox`. Reviewed By: carolineechen Differential Revision: D38829253 fbshipit-source-id: 3554af45a2beb0f902810c5548751264e093f28d
-
- 28 Jul, 2022 2 commits
-
-
moto authored
Summary: This commit gets rid of our copy of CTC decoder code and replace it with upstream Flashlight-Text repo. Pull Request resolved: https://github.com/pytorch/audio/pull/2580 Reviewed By: carolineechen Differential Revision: D38244906 Pulled By: mthrok fbshipit-source-id: d274240fc67675552d19ff35e9a363b9b9048721
-
moto authored
Summary: Extract the helper functions for defining library and extension so that they can be reused for building flashlight library and binding in https://github.com/pytorch/audio/issues/2580. Pull Request resolved: https://github.com/pytorch/audio/pull/2585 Reviewed By: carolineechen Differential Revision: D38233407 Pulled By: mthrok fbshipit-source-id: 96f7c62a8b70bb3ff5caede9730165d54a55272f
-
- 08 Jul, 2022 1 commit
-
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2531 Reviewed By: carolineechen Differential Revision: D37698120 Pulled By: mthrok fbshipit-source-id: d0fd6445d69758cd803a485cd17836d1936aa1ee
-
- 27 Jun, 2022 1 commit
-
-
moto authored
Summary: Follow-up of https://github.com/pytorch/audio/issues/2464. Add utility function to fetch the versions of FFmpeg. Pull Request resolved: https://github.com/pytorch/audio/pull/2467 Reviewed By: carolineechen Differential Revision: D37028006 Pulled By: mthrok fbshipit-source-id: 72adce1e6b43985760ce55b715b0e59af5244fdb
-
- 01 Jun, 2022 1 commit
-
-
moto authored
Summary: Extract from https://github.com/pytorch/audio/issues/2419. Move the `FileObj` definition to dedicated file, so that it can be reused from files other than StreamReader. Pull Request resolved: https://github.com/pytorch/audio/pull/2427 Reviewed By: carolineechen Differential Revision: D36794367 Pulled By: mthrok fbshipit-source-id: 999658f3f4d833566d933c9223e7a5d49d300574
-
- 28 May, 2022 1 commit
-
-
moto authored
Summary: Attempt to load ffmpeg extension at the top level import Preparation to use ffmpeg-based I/O as a fallback for sox_io backend. Pull Request resolved: https://github.com/pytorch/audio/pull/2417 Reviewed By: carolineechen Differential Revision: D36736989 Pulled By: mthrok fbshipit-source-id: 0beb6f459313b5ea91597393ccb12571444c54d9
-
- 27 May, 2022 1 commit
-
-
moto authored
Summary: * `Streamer` has been renamed to `StreamReader` when it was moved from prototype to beta. This commit applies the same name change to the C++ source code. * Fix miscellaneous lint issues * Make the code compilable on FFmpeg 5 Pull Request resolved: https://github.com/pytorch/audio/pull/2403 Reviewed By: carolineechen Differential Revision: D36613053 Pulled By: mthrok fbshipit-source-id: 69fedd6720d488dadf4dfe7d375ee76d216b215d
-
- 21 May, 2022 1 commit
-
-
moto authored
Summary: This commit adds file-like object support to Streaming API. ## Features - File-like objects are expected to implement `read(self, n)`. - Additionally `seek(self, offset, whence)` is used if available. - Without `seek` method, some formats cannot be decoded properly. - To work around this, one can use the existing `decoder` option to tell what decoder it should use. - The set of `decoder` and `decoder_option` arguments were added to `add_basic_[audio|video]_stream` method, similar to `add_[audio|video]_stream`. - So as to have the arguments common to both audio and video in front of the rest of the arguments, the order of the arguments are changed. - Also `dtype` and `format` arguments were changed to make them consistent across audio/video methods. ## Code structure The approach is very similar to how file-like object is supported in sox-based I/O. In Streaming API if the input src is string, it is passed to the implementation bound with TorchBind, if the src has `read` attribute, it is passed to the same implementation bound via PyBind 11.  ## Refactoring involved - Extracted to https://github.com/pytorch/audio/issues/2402 - Some implementation in the original TorchBind surface layer is converted to Wrapper class so that they can be re-used from PyBind11 bindings. The wrapper class serves to simplify the binding. - `add_basic_[audio|video]_stream` methods were removed from C++ layer as it was just constructing string and passing it to `add_[audio|video]_stream` method, which is simpler to do in Python. - The original core Streamer implementation kept the use of types in `c10` namespace minimum. All the `c10::optional` and `c10::Dict` were converted to the equivalents of `std` at binding layer. But since they work fine with PyBind11, Streamer core methods deal them directly. ## TODO: - [x] Check if it is possible to stream MP4 (yuv420p) from S3 and directly decode (with/without HW decoding). Pull Request resolved: https://github.com/pytorch/audio/pull/2400 Reviewed By: carolineechen Differential Revision: D36520073 Pulled By: mthrok fbshipit-source-id: a11d981bbe99b1ff0cc356e46264ac8e76614bc6
-
- 19 May, 2022 1 commit
-
-
moto authored
Summary: * Move the helper wrapping code in TorchBind layer to proper wrapper class for so that it will be re-used in PyBind11. * Move `add_basic_[audio|video]_stream` methods from C++ to Python, as they are just string manipulation. This will make PyBind11-based binding simpler as it needs not to deal with dtype. * Move `add_[audio|video]_stream` wrapper signature to Streamer core, so that Streamer directly deals with `c10::optional`.† † Related to this, there is a slight change in how the empty filter expression is stored. Originally, if an empty filter expression was given to `add_[audio|video]_stream` method, the `StreamReaderOutputStream` was showing it as empty string `""`, even though internally it was using `"anull"` or `"null"`. Now `StreamReaderOutputStream` shows the corresponding filter expression that is actually being used. Ref https://github.com/pytorch/audio/issues/2400 Pull Request resolved: https://github.com/pytorch/audio/pull/2402 Reviewed By: nateanl Differential Revision: D36488808 Pulled By: mthrok fbshipit-source-id: 877ca731364d10fc0cb9d97e75d55df9180f2047
-
- 13 May, 2022 1 commit
-
-
moto authored
Summary: This commit moves the Streaming API out of prototype module. * The related classes are renamed as following - `Streamer` -> `StreamReader`. - `SourceStream` -> `StreamReaderSourceStream` - `SourceAudioStream` -> `StreamReaderSourceAudioStream` - `SourceVideoStream` -> `StreamReaderSourceVideoStream` - `OutputStream` -> `StreamReaderOutputStream` This change is preemptive measurement for the possibility to add `StreamWriter` API. * Replace BUILD_FFMPEG build arg with USE_FFMPEG We are not building FFmpeg, so USE_FFMPEG is more appropriate --- After https://github.com/pytorch/audio/issues/2377 Remaining TODOs: (different PRs) - [ ] Introduce `is_ffmpeg_binding_available` function. - [ ] Refactor C++ code: - Rename `Streamer` to `StreamReader`. - Rename `streamer.[h|cpp]` to `stream_reader.[h|cpp]`. - Rename `prototype.cpp` to `stream_reader_binding.cpp`. - Introduce `stream_reader` directory. - [x] Enable FFmpeg in smoke test (https://github.com/pytorch/audio/issues/2381) Pull Request resolved: https://github.com/pytorch/audio/pull/2378 Reviewed By: carolineechen Differential Revision: D36359299 Pulled By: mthrok fbshipit-source-id: 6a57b702996af871e577fb7addbf3522081c1328
-
- 06 May, 2022 1 commit
-
-
moto authored
Summary: This commit changes the way torchaudio binary distributions are built. * For all the binary distributions (conda/pip on Linux/macOS/Windnows), build custom FFmpeg libraries. * The custom FFmpeg libraries do not use `--use-gpl` nor `--use-nonfree`, so that they stay LGPL. * The custom FFmpeg libraries employ rpath so that the torchaudio binary distributions look for the corresponding FFmpeg libraries installed in the runtime environment. * The torchaudio binary build process will use them to bootstrap its build process. * The custom FFmpeg libraries are NOT shipped. This commit also add disclaimer about FFmpeg in README. Pull Request resolved: https://github.com/pytorch/audio/pull/2355 Reviewed By: nateanl Differential Revision: D36202087 Pulled By: mthrok fbshipit-source-id: c30e5222ba190106c897e42f567cac9152dbd8ef
-
- 26 Apr, 2022 1 commit
-
-
Caroline Chen authored
Summary: Add support for lexicon free decoding based on [fairseq's](https://github.com/pytorch/fairseq/blob/main/examples/speech_recognition/new/decoders/flashlight_decoder.py#L53) implementation. Reached numerical parity with fairseq's decoder in offline experimentation Follow ups - Add pretrained LM support for lex free decoding - Add example in tutorial - Replace flashlight C++ source code with flashlight text submodule - [optional] fairseq compatibility test Pull Request resolved: https://github.com/pytorch/audio/pull/2342 Reviewed By: nateanl Differential Revision: D35856104 Pulled By: carolineechen fbshipit-source-id: b64286550984df906ebb747e82f6fb1f21948ac7
-
- 22 Mar, 2022 1 commit
-
-
moto authored
Summary: Originally, the global property TORCHAUDIO_THIRD_PARTIES was introduced to handle the optional third party dependencies that can change based on the build config. After revising the CMake, it turned out this is not really necessary, as our torchaudio/csrc/CMakeLists.txt properly branches out for conditional dependencies. Rather we should leave the global scope untouched. Pull Request resolved: https://github.com/pytorch/audio/pull/2282 Reviewed By: hwangjeff Differential Revision: D35059838 Pulled By: mthrok fbshipit-source-id: ed3557eaa9a669e4466d64893beab5089eca78b8
-
- 15 Feb, 2022 1 commit
-
-
moto authored
Summary: This commit fixes the issue with ffmpeg discovery at build time. The original implementation had issues like. 1. Wrong usage of FindFFMPEG, which caused mixture of ffmpeg libraries from system directory and user directory. 2. The optional `FFMPEG_ROOT` variable was not set within cmake. The issue 1 is problematic when a user does not have a permission to modify the environment. For example, an old version of ffmpeg, which is installed in a directory managed by the system (such as `/usr/local/lib`), then there is no way to specify a path in which user installs a supported version of ffmpeg. This commit changes the behavior by first searching the library in `FFMPEG_ROOT` environment variables, then resorting to the original behavior of searching the custom paths with system default path. Also this commirt removes support for `libavresample`, which is deprecated in ffmpeg 4 and removed in ffmpeg 5. Pull Request resolved: https://github.com/pytorch/audio/pull/2204 Reviewed By: carolineechen Differential Revision: D34225769 Pulled By: mthrok fbshipit-source-id: 95b0bfaaef31e2e69e6df29f789010f48a48210b
-
- 27 Jan, 2022 1 commit
-
-
Caroline Chen authored
Summary: Add support for CTC lexicon decoder without LM support by adding a non language model `ZeroLM` that returns score 0 for everything. Generalize the decoder class/API a bit to support this, adding it as an option for the kenlm decoder at the moment (will likely be separated out from kenlm when adding support for other kinds of LMs in the future) Pull Request resolved: https://github.com/pytorch/audio/pull/2174 Reviewed By: hwangjeff, nateanl Differential Revision: D33798674 Pulled By: carolineechen fbshipit-source-id: ef8265f1d046011b143597b3b7c691566b08dcde
-
- 02 Jan, 2022 1 commit
-
-
moto authored
Summary: `libtorchaudio_decoder`, `torchaudio_decoder` and `libtorchaudio_ffmpeg` need not to be linked against `libtorchaudio`. 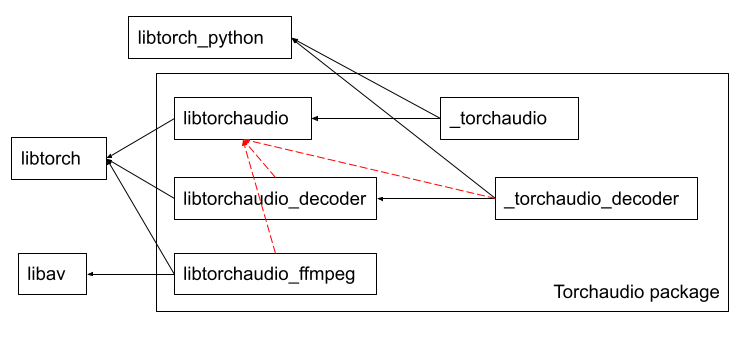 Pull Request resolved: https://github.com/pytorch/audio/pull/2121 Reviewed By: carolineechen Differential Revision: D33389197 Pulled By: mthrok fbshipit-source-id: ebb051e894e17519a87094b8056d26e7a1cd3281
-
- 30 Dec, 2021 1 commit
-
-
moto authored
Summary: This PR adds `BUILD_FFMPEG` switch to torchaudio build process so that features related to ffmpeg are built. The flag is false by default, so no CI jobs or development flow are affected. This is because handling the dependencies around ffmpeg is a bit tricky. Currently, the CMake file uses `pkg-config` to find an ffmpeg installation in the system. This works fine for both conda-based installation and system-managed installation (like `apt`). In subsequent PRs, I will find a solution that works for local development and binary distributions. Pull Request resolved: https://github.com/pytorch/audio/pull/2048 Reviewed By: hwangjeff, nateanl Differential Revision: D33367260 Pulled By: mthrok fbshipit-source-id: 94517acecb62bd6d4e96d4b7cbc3ab3c2a25706c
-
- 20 Dec, 2021 1 commit
-
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2085 Reviewed By: carolineechen Differential Revision: D33235225 Pulled By: mthrok fbshipit-source-id: 47fe9ec4c93a26322b3a362202ddd3c4654c3f8c
-
- 18 Dec, 2021 1 commit
-
-
moto authored
Summary: After all the C++ code from https://github.com/pytorch/audio/issues/2072 are added, this commit will enable decoder/KenLM integration in the build process. Pull Request resolved: https://github.com/pytorch/audio/pull/2078 Reviewed By: carolineechen Differential Revision: D33198183 Pulled By: mthrok fbshipit-source-id: 9d7fa76151d06fbbac3785183c7c2ff9862d3128
-
- 17 Dec, 2021 1 commit
-
-
moto authored
Summary: Similar to https://github.com/pytorch/audio/issues/2040 this commit refactor the part of the CMakeLists.txt which defines extension module so that second extension can be added easily. Pull Request resolved: https://github.com/pytorch/audio/pull/2077 Reviewed By: carolineechen Differential Revision: D33189998 Pulled By: mthrok fbshipit-source-id: dc562ce5360332479a7493c21a2930c6fcc6be84
-
- 04 Dec, 2021 1 commit
-
-
moto authored
Summary: (See https://github.com/pytorch/audio/issues/2038 description for the overall goal.) This commit turns the part that defines `libtorchaudio` into a function so that it becomes easy to define libraries in the same way as `libtorchaudio`. Built on top of https://github.com/pytorch/audio/issues/2039 Pull Request resolved: https://github.com/pytorch/audio/pull/2040 Reviewed By: hwangjeff Differential Revision: D32851990 Pulled By: mthrok fbshipit-source-id: a8206c62b076bc0849ada1a66c7502ae5ea35e28
-
- 03 Dec, 2021 1 commit
-
-
moto authored
Summary: (See https://github.com/pytorch/audio/issues/2038 description for the overall goal.) This PR cleans up CMake customization logic for `libtorchaudio`. It introduces base variables LIBTORCHAUDIO_INCLUDE_DIRS, LIBTORCHAUDIO_LINK_LIBRARIES and LIBTORCHAUDIO_COMPILE_DEFINITIONS, which are respectively used when calling `target_include_directories`, `target_link_libraries` and `target_compile_definitions`. The customization logic only modifies these variables. The original implementation called these functions multiple times (once par customization logic) and it is getting difficult to understand the customization logic. Pull Request resolved: https://github.com/pytorch/audio/pull/2039 Reviewed By: carolineechen, nateanl Differential Revision: D32683004 Pulled By: mthrok fbshipit-source-id: 4d41f21692ac139b1185a6ab69eb45d881ee7e73
-








