- 20 Jan, 2023 1 commit
-
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2995 Reviewed By: nateanl Differential Revision: D42624676 Pulled By: mthrok fbshipit-source-id: 10fbdaada06ae78e5fa2253eb3331c93c032eeb3
-
- 19 Jan, 2023 3 commits
-
-
Zhaoheng Ni authored
Summary: TorchAudio currently has one training recipe for HuBET + LibriSpeech pre-training. It may not suit well when users want to use customized dataset, or use a new training objective (such as contrastive loss in Wav2Vec2). The PR addresses the issue by providing a modularized training recipe for audio self-supervised learning. Users can inject customized model module, loss function, optimizer, lr scheduler, and datamodule for training a SSL model. Pull Request resolved: https://github.com/pytorch/audio/pull/2876 Reviewed By: hwangjeff Differential Revision: D42617414 Pulled By: nateanl fbshipit-source-id: 6413df45a9d106ed1d5ff830bf628c54368c5792
-
hwangjeff authored
Summary: In the Conformer RNN-T LibriSpeech recipe, there's no need to perform manual optimization. This PR modifies the recipe to use automatic optimization instead. Pull Request resolved: https://github.com/pytorch/audio/pull/2981 Reviewed By: mthrok Differential Revision: D42507228 Pulled By: hwangjeff fbshipit-source-id: 9712add951eba356e39f7e8c8dc3bf584ba48309
-
hwangjeff authored
Summary: For greater flexibility, this PR makes argument `lengths` optional for `add_noise` and `AddNoise`. Pull Request resolved: https://github.com/pytorch/audio/pull/2977 Reviewed By: nateanl Differential Revision: D42484211 Pulled By: hwangjeff fbshipit-source-id: 54757dcc73df194bb98c1d9d42a2f43f3027b190
-
- 17 Jan, 2023 2 commits
-
-
Moto Hira authored
Summary: When buffered data are cleared from ChunkedBuffer, the `num_buffered_frames` variable was not updated. This commit fixes that. Reviewed By: xiaohui-zhang Differential Revision: D42538519 fbshipit-source-id: a24a9afcebebd8956d977f05e9c2f0b603d060d1
-
Zhaoheng Ni authored
Summary: The mel spectrograms in the TTS tutorial are upside down. The PR fixes it by using `origin="lower"` in imshow. Pull Request resolved: https://github.com/pytorch/audio/pull/2989 Reviewed By: mthrok Differential Revision: D42538349 Pulled By: nateanl fbshipit-source-id: 4388103a49bdfabf1705c1f979d44ecedd5c910a
-
- 16 Jan, 2023 4 commits
-
-
moto authored
Summary: Split `convert_video` into memory allocation function and write function. Also put all the buffer implementations into detail namespace. Pull Request resolved: https://github.com/pytorch/audio/pull/2988 Reviewed By: xiaohui-zhang Differential Revision: D42536769 Pulled By: mthrok fbshipit-source-id: 36fbf437d4bfd521322846161ae08a48c782c540
-
Robin Scheibler authored
Summary: The `examples/source_separation` scripts use inconsistent keyword to indicate the WSJ0_2mix dataset. This PR does the following. 1. Use `wsj0mix` consistently as keyword indicating the WSJ0_2mix dataset 2. Corrects `args.data_dir` to `args.root_dir` in eval.py 3. Modify the parameters of `pytorch_lightning.Trainer` according to latest version (use `accelerator="gpu"` and `devices=args.num_devices`, instead of just `gpus=args.num_devices`) Pull Request resolved: https://github.com/pytorch/audio/pull/2987 Reviewed By: xiaohui-zhang Differential Revision: D42536992 Pulled By: nateanl fbshipit-source-id: 10a80263ad7054b1629d8fa023676b607e633d76
-
moto authored
Summary: So that the number of Tensor frames stored in buffers is always a multiple of frames_per_chunk. This makes it easy to store PTS values in aligned manner. Pull Request resolved: https://github.com/pytorch/audio/pull/2984 Reviewed By: nateanl Differential Revision: D42526670 Pulled By: mthrok fbshipit-source-id: d83ee914b7e50de3b51758069b0e0b6b3ebe2e54
-
moto authored
Summary: FilterGraph supports multi threading, and by default, the number of threads is determined automatically. Rather than an automatic behavior, which is unpredictable, it is better to fix the number of threads to 1. Follow-up: Add an interface to adjust it. Similar to https://github.com/pytorch/audio/pull/2949. Pull Request resolved: https://github.com/pytorch/audio/pull/2985 Reviewed By: nateanl Differential Revision: D42526958 Pulled By: mthrok fbshipit-source-id: c4f7f95317e93a39378107636a3ca30f6ddfe466
-
- 15 Jan, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: The PR adds three `Wav2Vec2Bundle ` pipeline objects for XLS-R models: - WAV2VEC2_XLSR_300M - WAV2VEC2_XLSR_1B - WAV2VEC2_XLSR_2B All three models use layer normalization in the feature extraction layers, hence `_normalize_waveform` is set to `True`. Pull Request resolved: https://github.com/pytorch/audio/pull/2978 Reviewed By: hwangjeff Differential Revision: D42501491 Pulled By: nateanl fbshipit-source-id: 2429ec880cc14798034843381e458e1b4664dac3
-
- 14 Jan, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: XLS-R tests are supposed to be skipped on gpu machines, but they are forced to run in [_skipIf](https://github.com/pytorch/audio/blob/main/test/torchaudio_unittest/common_utils/case_utils.py#L143-L145) decorator. This PR skips the XLS-R tests if the machine is CI and CUDA is available. Pull Request resolved: https://github.com/pytorch/audio/pull/2982 Reviewed By: xiaohui-zhang Differential Revision: D42520292 Pulled By: nateanl fbshipit-source-id: c6ee4d4a801245226c26d9cd13e039e8d910add2
-
- 13 Jan, 2023 2 commits
-
-
moto authored
Summary: Per the suggestion by nateanl, adding the visualization of feature fed to ASR. <img width="688" alt="Screen Shot 2023-01-12 at 8 19 59 PM" src="https://user-images.githubusercontent.com/855818/212215190-23be7553-4c04-40d9-944e-3ee2ff69c49b.png"> Pull Request resolved: https://github.com/pytorch/audio/pull/2974 Reviewed By: nateanl Differential Revision: D42484088 Pulled By: mthrok fbshipit-source-id: 2c839492869416554eac04aa06cd12078db21bd7
-
Zhaoheng Ni authored
Summary: XLSR (cross-lingual speech representation) are a set of cross-lingual self-supervised learning models for generating cross-lingual speech representation. It was first proposed in https://arxiv.org/pdf/2006.13979.pdf which is trained on 53 languages (so-called XLSR-53). This PR supports more XLS-R models from https://arxiv.org/pdf/2111.09296.pdf that have more parameters (300M, 1B, 2B) and are trained on 128 languages. Pull Request resolved: https://github.com/pytorch/audio/pull/2959 Reviewed By: mthrok Differential Revision: D42397643 Pulled By: nateanl fbshipit-source-id: 23e8e51a7cde0a226db4f4028db7df8f02b986ce
-
- 12 Jan, 2023 4 commits
-
-
mthrok authored
Summary: * Refactor _extension module so that * the implementation of initialization logic and its execution are separated. * logic goes to `_extension.utils` * the execution is at `_extension.__init__` * global variables are defined and modified in `__init__`. * Replace `is_sox_available()` with `_extension._SOX_INITIALIZED` * Replace `is_kaldi_available()` with `_extension._IS_KALDI_AVAILABLE` * Move `requies_sox()` and `requires_kaldi()` to break the circular dependency among `_extension` and `_internal.module_utils`. * Merge the sox-related initialization logic in `_extension.utils` module. Pull Request resolved: https://github.com/pytorch/audio/pull/2968 Reviewed By: hwangjeff Differential Revision: D42387251 Pulled By: mthrok fbshipit-source-id: 0c3245dfab53f9bc1b8a83ec2622eb88ec96673f -
moto authored
Summary: This commit add methods to query output configuration from FilterGraph object. * time_base -> required to compute PTS of output frame * sample_rate, num_channels -> required to compute PTS and pre allocate buffers for audio. Pull Request resolved: https://github.com/pytorch/audio/pull/2976 Reviewed By: xiaohui-zhang Differential Revision: D42466744 Pulled By: mthrok fbshipit-source-id: dd27109819bfb1fbe37b8233dd6a5e4224fe3f6c
-
moto authored
Summary: This commit adds `buffer_chunk_size=-1`, which does not drop buffered frames. Pull Request resolved: https://github.com/pytorch/audio/pull/2969 Reviewed By: xiaohui-zhang Differential Revision: D42403467 Pulled By: mthrok fbshipit-source-id: a0847e6878874ce7e4b0ec3f56e5fbb8ebdb5992
-
moto authored
Summary: Following the change in PyTorch core. https://github.com/pytorch/pytorch/commit/87e4a087784c805312a2b48bb063d2400df26c5e Pull Request resolved: https://github.com/pytorch/audio/pull/2973 Reviewed By: xiaohui-zhang Differential Revision: D42462709 Pulled By: mthrok fbshipit-source-id: 60c2aa3d63fe25d8e0b7aa476404e7a55d6eb87f
-
- 11 Jan, 2023 1 commit
-
-
pbialecki authored
Summary: CC atalman Pull Request resolved: https://github.com/pytorch/audio/pull/2951 Reviewed By: mthrok Differential Revision: D42459205 Pulled By: atalman fbshipit-source-id: b2d7c5604ba1f3bb4d9a45a052ac41054acd52dd
-
- 10 Jan, 2023 2 commits
-
-
moto authored
Summary: filter graph does not fallback to `best_effort_timestamp`, thus applying filters (like changing fps) on videos without PTS values failed. This commit changes the behavior by overwriting the PTS values with best_effort_timestamp. Pull Request resolved: https://github.com/pytorch/audio/pull/2970 Reviewed By: YosuaMichael Differential Revision: D42425771 Pulled By: mthrok fbshipit-source-id: 7b7a033ea2ad89bb49d6e1663d35d377dab2aae9
-
moto authored
Summary: * Add missing docsrtings * Add default values Pull Request resolved: https://github.com/pytorch/audio/pull/2971 Reviewed By: xiaohui-zhang Differential Revision: D42425796 Pulled By: mthrok fbshipit-source-id: a6a946875142a54424c059bbfbab1908a1564bd3
-
- 06 Jan, 2023 6 commits
-
-
Zhaoheng Ni authored
Summary: `InverseMelScale` is missing from the nightly documentation webpage. `MelScale` is better in Feature Extractions section. This PR moves both documents into Feature Extractions section. Pull Request resolved: https://github.com/pytorch/audio/pull/2967 Reviewed By: mthrok Differential Revision: D42387886 Pulled By: nateanl fbshipit-source-id: cdac020887817ea2530bfb26e8ed414ae4761420
-
moto authored
Summary: This commit adds utility functions that fetch the available/supported formats/devices/codecs. These functions are mostly same with commands like `ffmpeg -decoders`. But the use of `ffmpeg` CLI can report different resutls if there are multiple installation of FFmpegs. Or, the CLI might not be available. Pull Request resolved: https://github.com/pytorch/audio/pull/2958 Reviewed By: hwangjeff Differential Revision: D42371640 Pulled By: mthrok fbshipit-source-id: 96a96183815a126cb1adc97ab7754aef216fff6f
-
moto authored
Summary: Introduced in hotfix https://github.com/pytorch/audio/issues/2964 Pull Request resolved: https://github.com/pytorch/audio/pull/2966 Reviewed By: carolineechen Differential Revision: D42385913 Pulled By: mthrok fbshipit-source-id: 6c42dbfbb914b0329c09a1bca591f11cf2e3c1a6
-
moto authored
Summary: Put the helper functions in unnamed namespace. Pull Request resolved: https://github.com/pytorch/audio/pull/2962 Reviewed By: carolineechen Differential Revision: D42378781 Pulled By: mthrok fbshipit-source-id: 74daf613f8b78f95141ae4e7c4682d8d0e97f72e
-
moto authored
Summary: Follow-up of f70b970a Pull Request resolved: https://github.com/pytorch/audio/pull/2964 Reviewed By: xiaohui-zhang Differential Revision: D42380451 Pulled By: mthrok fbshipit-source-id: 0569a32be576042ab419b363e694fe7d2db1feb0
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2963 Phaser batch consistency test takes longer than the rest. Change the sample rate from 44100 to 8000. Reviewed By: hwangjeff Differential Revision: D42379064 fbshipit-source-id: 2005b833c696bb3c2bb1d21c38c39e6163d81d53
-
- 05 Jan, 2023 4 commits
-
-
Zhaoheng Ni authored
Summary: The generator part of HiFiGAN model is a vocoder which converts mel spectrogram to waveform. It makes more sense to name it as vocoder for better understanding. Pull Request resolved: https://github.com/pytorch/audio/pull/2955 Reviewed By: carolineechen Differential Revision: D42348864 Pulled By: nateanl fbshipit-source-id: c45a2f8d8d205ee381178ae5d37e9790a257e1aa
-
moto authored
Summary: lfilter, overdrive have faster implementation written in C++. If they are not available, torchaudio is supposed to fall back on Python-based implementation. The original fallback mechanism relied on error type and messages from PyTorch core, which has been changed. This commit updates it for more proper fallback mechanism. Pull Request resolved: https://github.com/pytorch/audio/pull/2953 Reviewed By: hwangjeff Differential Revision: D42344893 Pulled By: mthrok fbshipit-source-id: 18ce5c1aa1c69d0d2ab469b0b0c36c0221f5ccfd
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2956 Merge utility binding This commit updates the utility binding, so that we can use `is_module_available()` for checking the existence of extension modules. To ensure the existence of module, this commit migrates the binding of utility functions to PyBind11. Going forward, we should use TorchBind for ops that we want to support TorchScript, otherwise default to PyBind11. (PyBind has advantage of not copying strings.) Reviewed By: hwangjeff Differential Revision: D42355992 fbshipit-source-id: 4c71d65b24a0882a38a80dc097d45ba72b4c4a6b
-
Grigory Sizov authored
Summary: Closes [T138011314](https://www.internalfb.com/intern/tasks/?t=138011314) ## Description - Add bundle `HIFIGAN_GENERATOR_V3_LJSPEECH` to prototypes. The bundle contains pre-trained HiFiGAN generator weights from the [original HiFiGAN publication](https://github.com/jik876/hifi-gan#pretrained-model), converted slightly to fit our model - Add tests - unit tests checking that vocoder and mel-transform implementations in the bundle give the same results as the original ones. Part of the original HiFiGAN code is ported to this repo to enable these tests - integration test checking that waveform reconstructed from mel spectrogram by the bundle is close enough to the original - Add docs Pull Request resolved: https://github.com/pytorch/audio/pull/2921 Reviewed By: nateanl, mthrok Differential Revision: D42034761 Pulled By: sgrigory fbshipit-source-id: 8b0dadeed510b3c9371d6aa2c46ec7d8378f6048
-
- 04 Jan, 2023 5 commits
-
-
moto authored
Summary: Currently, when iterating media data with StreamReader, using the for-loop is the only way with public API. This does not support usecases like "Fetch one chunk after seek" well. ```python s = StreamReader s.add_audio_stream(...) s.seek(10) chunk = None for chunk, in s.stream(): break ``` This commit make the `fill_buffer` used in iterative method public API so that one acn do ```python s.seek(10) s.fill_buffer() chunk, = s.pop_chunks() ``` --- Also this commit moves the implementation to C++ so that it reduces the number of FFI boundary crossing. This improves the performance when the iteration is longer. AVI (generated with `ffmpeg -hide_banner -f lavfi -t ${duration} -i testsrc "${file}.avi"`) | Video Duration [sec] | Original [msec] | Fill Buffer C++ | One Go (reference) | |----------------------|----------|-----------------|--------| | 1 | 18 | 18.4 | 16.6 | | 5 | 44 | 42.6 | 35.1 | | 10 | 75.3 | 74.4 | 60.9 | | 30 | 200 | 195 | 158 | | 60 | 423 | 382 | 343 | MP4 (generated with `ffmpeg -hide_banner -f lavfi -t ${duration} -i testsrc "${file}.mp4"`) | Video Duration [sec] | Original [msec] | Fill Buffer C++ | One Go | |----------------------|-----------------|-----------------|--------| | 1 | 18.7 | 18.1 | 10.3 | | 5 | 42.2 | 40.6 | 25.2 | | 10 | 73.9 | 71.8 | 43.6 | | 30 | 202 | 194 | 116 | | 60 | 396 | 386 | 227 | * Original (Python implementation) ```python r = StreamReader(src) r.add_video_stream(1, decoder_option={"threads": "1"}) for chunk, in r.stream(): pass ``` * This (C++) ```python r = StreamReader(src) r.add_video_stream(1, decoder_option={"threads": "1"}) for chunk, in r.stream(): pass ``` * Using `process_all_packets` (process all in one go) ```python r = StreamReader(src) r.add_video_stream(1, decoder_option={"threads": "1"}) r.process_all_packets() ``` Pull Request resolved: https://github.com/pytorch/audio/pull/2954 Reviewed By: carolineechen Differential Revision: D42349446 Pulled By: mthrok fbshipit-source-id: 9e4e37923e46299c3f43f4ad17a2a2b938b2b197 -
moto authored
Summary: One can pass "threads" and "thread_type" to `decoder_option` of StreamReaader to change the multithreading configuration. These affects the timing that decoder starts emitting the decoded frames. i.e. how many packets at minimum have to be processed before the first frame is decoded. Overall, multithreading in decoder does not improve the performance. (One possible reason is because the design of StreamReader, "decode few frames then fetch them", does not suited to saturate the decoder with incoming packets.) num_threads=1 seems to exhibit overall good performance/resource balance. 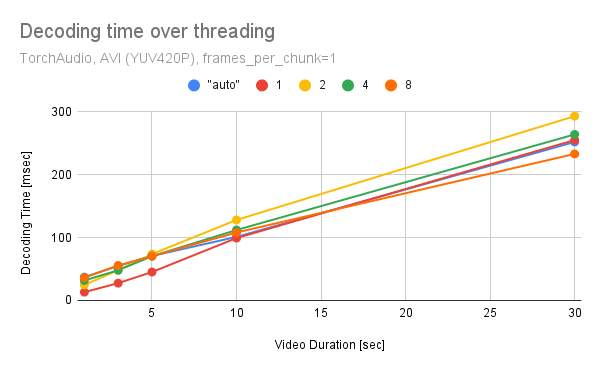 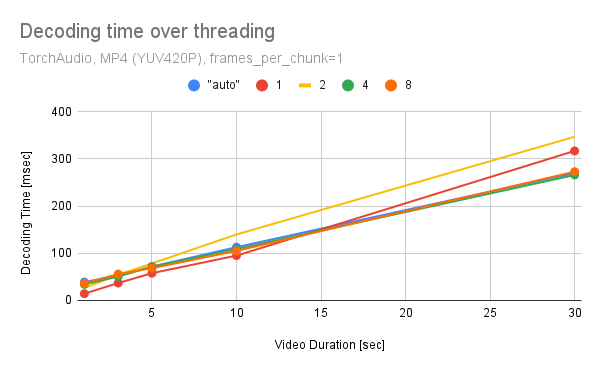 (Tested on 320x240 25 FPPS, YUV420P videos generated with `ffmpeg -f lavfi -t "${duration}" -i testsrc -pix_fmt "yuv420p"`) For this reason, we default to single thread execution in StreamReader. closes https://github.com/pytorch/audio/issues/2855 Follow-up: Apply similar change to encoder option in StreamWriter. Pull Request resolved: https://github.com/pytorch/audio/pull/2949 Reviewed By: carolineechen Differential Revision: D42343951 Pulled By: mthrok fbshipit-source-id: aea234717d37918f99fc24f575dbcfe7dcae1e80
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2866 Reviewed By: carolineechen Differential Revision: D42349474 Pulled By: mthrok fbshipit-source-id: 31455184031fff52719ef829e40bb1e09e11b0e7
-
hwangjeff authored
Summary: Currently, importing TorchAudio triggers a check of the CUDA version it was compiled with, which in turn calls `torch.ops.torchaudio.cuda_version()`. This function is available only if `libtorchaudio` is available; developers, however, may want to import TorchAudio regardless of its availability. To allow for such usage, this PR adds code that bypasses the check if `libtorchaudio` is not available. Pull Request resolved: https://github.com/pytorch/audio/pull/2952 Reviewed By: mthrok Differential Revision: D42336396 Pulled By: hwangjeff fbshipit-source-id: 465353cf46b218c0bcdf51ca5cf0b83c93185f39
-
Jeff Hwang authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/2935 Reviewed By: mthrok Differential Revision: D42302275 Pulled By: hwangjeff fbshipit-source-id: d995d335bf17d63d3c1dda77d8ef596570853638
-
- 30 Dec, 2022 4 commits
-
-
moto authored
Summary: * Split `convert_[yuv420p|nv12|nv12_cuda]` functions into allocation and data write functions. * Merge the `get_[interlaced|planar]_image_buffer` functions into `get_buffer` and `get_image_buffer`. * Disassemble `convert_XXX_image` helper functions. Pull Request resolved: https://github.com/pytorch/audio/pull/2946 Reviewed By: nateanl Differential Revision: D42287501 Pulled By: mthrok fbshipit-source-id: b8dd0d52fd563a112a16887b643bf497f77dfb80
-
Zhaoheng Ni authored
Summary: The `root` path can be confusing to users without reading the document. The PR adds runtime error for a better understanding. Pull Request resolved: https://github.com/pytorch/audio/pull/2944 Reviewed By: mthrok Differential Revision: D42281034 Pulled By: nateanl fbshipit-source-id: 6e5f4bfb118583d678d6b7a2565ef263fe8e4a5a
-
moto authored
Summary: This commit refactors and optimizes functions that converts AVFrames of `yuv420p` and `nv12` into PyTorch's Tensor. The performance is improved about 30%. 1. Reduce the number of intermediate Tensors allocated. 2. Replace 2 calls to `repeat_interleave` with `F::interpolate`. * (`F::interpolate` is about 5x faster than `repeat_interleave`. ) <details><summary>code</summary> ```bash #!/usr/bin/env bash set -e python -c """ import torch import torch.nn.functional as F a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() val1 = a.repeat_interleave(2, -1).repeat_interleave(2, -2) val2 = F.interpolate(a.view((1, 1, 7, 7, 1)), size=[14, 14, 1], mode=\"nearest\") print(torch.sum(torch.abs(val1 - val2[0, 0, :, :, 0]))) """ python3 -m timeit \ --setup """ import torch a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() """ \ """ a.repeat_interleave(2, -1).repeat_interleave(2, -2) """ python3 -m timeit \ --setup """ import torch import torch.nn.functional as F a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone() """ \ """ F.interpolate(a.view((1, 1, 7, 7, 1)), size=[14, 14, 1], mode=\"nearest\") """ ``` </details> ``` tensor(0) 10000 loops, best of 5: 38.3 usec per loop 50000 loops, best of 5: 7.1 usec per loop ``` ## Benchmark Result <details><summary>code</summary> ```bash #!/usr/bin/env bash set -e mkdir -p tmp for ext in avi mp4; do for duration in 1 5 10 30 60; do printf "Testing ${ext} ${duration} [sec]\n" test_data="tmp/test_${duration}.${ext}" if [ ! -f "${test_data}" ]; then printf "Generating test data\n" ffmpeg -hide_banner -f lavfi -t ${duration} -i testsrc "${test_data}" > /dev/null 2>&1 fi python -m timeit \ --setup="from torchaudio.io import StreamReader" \ """ r = StreamReader(\"${test_data}\") r.add_basic_video_stream(frames_per_chunk=-1, format=\"yuv420p\") r.process_all_packets() r.pop_chunks() """ done done ``` </details> 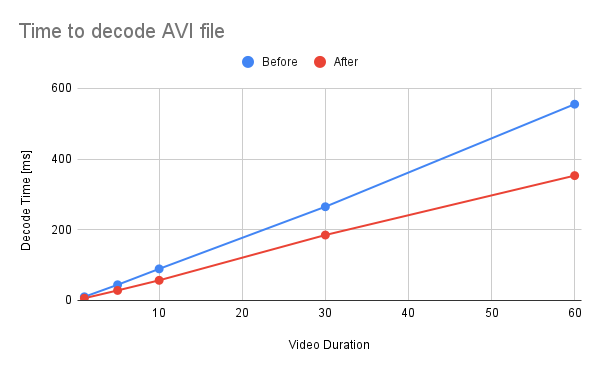 <details><summary>raw data</summary> Video Type - AVI Duration | Before | After -- | -- | -- 1 | 10.3 | 6.29 5 | 44.3 | 28.3 10 | 89.3 | 56.9 30 | 265 | 185 60 | 555 | 353 </details> 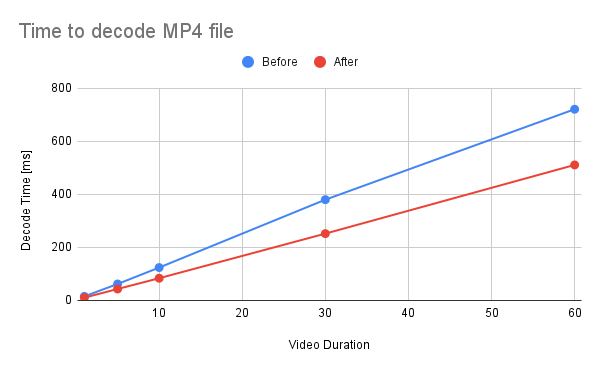 <details><summary>raw data</summary> Video Type - MP4 Duration | Before | After -- | -- | -- 1 | 15.3 | 10.5 5 | 62.1 | 43.2 10 | 124 | 83.8 30 | 380 | 252 60 | 721 | 511 </details> Pull Request resolved: https://github.com/pytorch/audio/pull/2945 Reviewed By: carolineechen Differential Revision: D42283269 Pulled By: mthrok fbshipit-source-id: 59840f943ff516b69ab8ad35fed7104c48a0bf0c -
moto authored
Summary: Artifact: [subtractive_synthesis_tutorial](https://output.circle-artifacts.com/output/job/4c1ce33f-834d-48e0-ba89-2e91acdcb572/artifacts/0/docs/tutorials/subtractive_synthesis_tutorial.html) Pull Request resolved: https://github.com/pytorch/audio/pull/2934 Reviewed By: carolineechen Differential Revision: D42284945 Pulled By: mthrok fbshipit-source-id: d255b8e8e2a601a19bc879f9e1c38edbeebaf9b3
-








