- 02 May, 2023 1 commit
-
-
Xiaohui Zhang authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3162 Reviewed By: mthrok Differential Revision: D43964995 Pulled By: xiaohui-zhang fbshipit-source-id: bba8fffe25f2f39f558f080fef319b1df4c6e440
-
- 01 May, 2023 2 commits
-
-
atalman authored
Summary: Adding win wheels builds Same as : https://github.com/pytorch/vision/pull/7540 Pull Request resolved: https://github.com/pytorch/audio/pull/3287 Reviewed By: osalpekar Differential Revision: D45452770 Pulled By: atalman fbshipit-source-id: e70ad3a8f456e805b46da3d1752c42208dadb8da
-
pbialecki authored
Summary: CC atalman malfet Pull Request resolved: https://github.com/pytorch/audio/pull/3284 Reviewed By: mthrok Differential Revision: D45444670 Pulled By: atalman fbshipit-source-id: d0cf8696a99000c2b9a7e41ceeb781f5a54daeda
-
- 29 Apr, 2023 1 commit
-
-
Zhaoheng Ni authored
Summary: The PR adds a tutorial that demonstrates how to use pre-trained `TorchAudio-SQUIM` pipelines to estimate objective and subjective metric scores (PESQ, STOI, Si-SDR, MOS). Pull Request resolved: https://github.com/pytorch/audio/pull/3279 Reviewed By: hwangjeff Differential Revision: D45415404 Pulled By: nateanl fbshipit-source-id: abcaeadcca0eabc2dca53b607eac6257a701c903
-
- 28 Apr, 2023 1 commit
-
-
Yuekai Zhang authored
Summary: This PR implements a CUDA based ctc prefix beam search decoder. Attach serveral benchmark results using V100 below: |decoder type| model |datasets | decoding time (secs)| beam size | batch size | model unit | subsampling times | vocab size | |--------------|---------|------|-----------------|------------|-------------|------------|-----------------------|------------| | cuctc | conformer nemo |dev clean |7.68s | 8 | 32 | bpe | 4 | 1000| | cuctc | conformer nemo |dev clean (sort by length) |1.6s | 8 | 32 | bpe | 4 | 1000| | cuctc | wav2vec2.0 torchaudio |dev clean |22s | 10 | 1 | char | 2 | 29| | cuctc | conformer espnet |aishell1 test | 5s | 10 | 24 | char | 4 | 4233| Note: 1. The design is to parallel computation through batch and vocab axis, for loop the frames axis. So it's more friendly with smaller sequence lengths, larger vocab size comparing with CPU implementations. 2. WER is the same as CPU implementations. However, it can't decode with LM now. Resolves: https://github.com/pytorch/audio/issues/2957. Pull Request resolved: https://github.com/pytorch/audio/pull/3096 Reviewed By: nateanl Differential Revision: D44709397 Pulled By: mthrok fbshipit-source-id: 3078c54a2b44dc00eb4a81b4c657487eeff8c155
-
- 25 Apr, 2023 1 commit
-
-
Jeff Hwang authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3277 Adds `StreamWriterCustomIO` to support encoding and writing media to arbitrary destinations. Reviewed By: mthrok Differential Revision: D44904807 fbshipit-source-id: 23a47531973a7dce0638feb825d38c81d46dc02f
-
- 19 Apr, 2023 2 commits
-
-
Zhaoheng Ni authored
Summary: The `master` branch of PyTorch has been updated to `main` recently. The url of `collect_env.py` in the new issue page should be updated as well. Pull Request resolved: https://github.com/pytorch/audio/pull/3271 Reviewed By: xiaohui-zhang Differential Revision: D45087038 Pulled By: nateanl fbshipit-source-id: 167262ae6ed179baabcf55064fc5f0f0ac3b0be9
-
hwangjeff authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3272 Reviewed By: mthrok Differential Revision: D45095440 Pulled By: hwangjeff fbshipit-source-id: 135eb0f5d9047bf172563a9a05a9d2e323796d4d
-
- 18 Apr, 2023 1 commit
-
-
nateanl authored
Summary: The PR adds the training recipe of DNN beamforming for multi-channel speech enhancement. Pull Request resolved: https://github.com/pytorch/audio/pull/3036 Reviewed By: hwangjeff Differential Revision: D45061841 Pulled By: nateanl fbshipit-source-id: 48ede5dd579efe200669dbc83e9cb4dea809e4b4
-
- 12 Apr, 2023 3 commits
-
-
Zhaoheng Ni authored
Summary: When `key_padding_mask` is not `None`, it needs to be combined with `attn_mask_rel_pos` as one mask for `scaled_dot_product_attention` function. Pull Request resolved: https://github.com/pytorch/audio/pull/3265 Reviewed By: hwangjeff Differential Revision: D44901093 Pulled By: nateanl fbshipit-source-id: 73ca7af48faf7f4eb36b35b603187a11e5582c70
-
moto authored
Summary: When `TORCHAUDIO_TEST_TEMP_DIR` is set, all the unit test temporary data are stored in the given directory. Running unit tests multiple times reuses the directory and the temporary files from the previous test runs are found there. FFmpeg save test writes reference data to the temporary directory, but it is not given the overwrite flag ("-y"), so it fails in such cases. This commit fixes that. Pull Request resolved: https://github.com/pytorch/audio/pull/3263 Reviewed By: hwangjeff Differential Revision: D44859003 Pulled By: mthrok fbshipit-source-id: 2db92fbdec1c015455f3779e10a18f7f1146166b -
moto authored
Summary: Preparation to land https://github.com/pytorch/audio/pull/3241 This commit applies patch to make the sox_io TorchScript test pass when dispatcher is enabled. Pull Request resolved: https://github.com/pytorch/audio/pull/3262 Reviewed By: hwangjeff Differential Revision: D44897513 Pulled By: mthrok fbshipit-source-id: 9b65f705cd02324328a2bc1c414aa4b7ca0fed32
-
- 11 Apr, 2023 2 commits
-
-
moto authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3258 Reviewed By: nateanl Differential Revision: D44859397 Pulled By: mthrok fbshipit-source-id: 361ac6a8c7092cc753f77d7745ec178760e8b9c3
-
moto authored
Summary: GCC should not be used when building FFmpeg for torchaudio, as torchaudio uses MSVC (cl.exe) Pull Request resolved: https://github.com/pytorch/audio/pull/3257 Reviewed By: nateanl Differential Revision: D44835169 Pulled By: mthrok fbshipit-source-id: 038c70caae58cec47dd2d6d08b8244c193104eda
-
- 10 Apr, 2023 4 commits
-
-
Zhaoheng Ni authored
Summary: Fix https://github.com/pytorch/audio/issues/3219. `torch.nn.MultiheadAttention` will throw an error if `torch.no_grad()` and mask are both given. The pull request fixes it by replacing the forward method with `torch.nn.functional.scaled_dot_product_attention`. Pull Request resolved: https://github.com/pytorch/audio/pull/3252 Reviewed By: mthrok Differential Revision: D44798634 Pulled By: nateanl fbshipit-source-id: abfa7fb84b7bd71848a92ab26da5a5f0f095c665
-
Zhaoheng Ni authored
Summary: Replace the attention computation with `torch.nn.functional.scaled_dot_product_attention` to improve running efficiency. Pull Request resolved: https://github.com/pytorch/audio/pull/3253 Reviewed By: mthrok Differential Revision: D44800353 Pulled By: nateanl fbshipit-source-id: 41550d868c809099aadbe812b0ebe2c38121efb8
-
Zhaoheng Ni authored
Summary: - Add citations of [`TorchAudio-Squim`](https://arxiv.org/abs/2304.01448) publication. - Update descriptions in the `SQUIM_OBJECTIVE` and `SQUIM_SUBJECTIVE` pipelines. Pull Request resolved: https://github.com/pytorch/audio/pull/3254 Reviewed By: hwangjeff Differential Revision: D44802015 Pulled By: nateanl fbshipit-source-id: ca08298ec1eafefdd671ff2e010ef18f7372f9f8
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3255 Prefixing what is always pointer with `p` does not improve readability... Reviewed By: hwangjeff Differential Revision: D44799531 fbshipit-source-id: bc2ce4e534009e2cb577719953207ddb82cf2d3d
-
- 07 Apr, 2023 5 commits
-
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3251 Removes unnecessary media type check in FilterGraph. Allows to define filters that have different media type for input and output. Reviewed By: nateanl Differential Revision: D44792340 fbshipit-source-id: e00497e0d30b5b3c3aacc66dd9b8c401757af288
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3249 - Put ptr member private so that it's more secure and subclasses won't mess with it - Remove unused `reset` method - Do not default construct the managed object - Introduce helper function for default allocation. (for AVFrame and AVPacket as they are allocated in both reader and writer) - for others, allocation logics are moved to where it is used. - Remove unused `pHWBufferRef` attribute from `StreamWriter`. Reviewed By: hwangjeff Differential Revision: D44775297 fbshipit-source-id: ff6db528152cd54c1ae398191110c30b9c1e238c
-
atalman authored
Summary: Remove temp channel for python 3.11, simplify logic around cuda Pull Request resolved: https://github.com/pytorch/audio/pull/3250 Reviewed By: mthrok Differential Revision: D44788219 Pulled By: atalman fbshipit-source-id: 421ff9e0bf1818b41e395708cc4589d4a9c865bd
-
Jeff Hwang authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3220 Introduces methods to `StreamReader` and `StreamWriter` that allow for reading and writing `AVPacket` instances rather than tensors. Useful for efficiently remuxing data pulled as is from source. Reviewed By: mthrok Differential Revision: D44271536 fbshipit-source-id: 9b9d743c0119a5eb564fa628fd6a67806d120985
-
moto authored
Summary: Follow up of https://github.com/pytorch/audio/issues/3243. Save compat module had different semantics than info and load, which requires different way of performing path normalization. Pull Request resolved: https://github.com/pytorch/audio/pull/3248 Reviewed By: hwangjeff Differential Revision: D44774997 Pulled By: mthrok fbshipit-source-id: 4b967ae3ca6b45850d455b8e95aaa31762c5457e
-
- 06 Apr, 2023 2 commits
-
-
moto authored
Summary: In https://github.com/pytorch/audio/pull/3232, the CTC decoder is excluded from binary distribution. To use CTCDecoder, users need to install flashlight-text. Currently, if flashlight-text is not available, torchaudio still attempts to import the custom bundle. This commit clean up this behavior by delaying the error until one of the components is actually used, and providing a better message. Pull Request resolved: https://github.com/pytorch/audio/pull/3246 Test Plan: Binary smoke tests import torchaudio without installing flashlight. Unit test CI jobs run the CTC decoder with flashlight installed. Reviewed By: jacobkahn Differential Revision: D44748413 Pulled By: mthrok fbshipit-source-id: 21d2cbd9961ed88405a739cc682071066712f5e4
-
Jeff Hwang authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3244 Adds methods to `StreamWriter` that allow for passing in `AVFrame` instances rather than tensors. Reviewed By: mthrok Differential Revision: D44589256 fbshipit-source-id: f100e0d349708482b873a9a4bae1eaf5eb65301a
-
- 05 Apr, 2023 2 commits
-
-
moto authored
Summary: In dispatcher mode, FFmpeg backend does not handle file-like object, and C++ implementation raises an issue. This commit fixes it by normalizing file-like object to string. Pull Request resolved: https://github.com/pytorch/audio/pull/3243 Reviewed By: nateanl Differential Revision: D44719280 Pulled By: mthrok fbshipit-source-id: 9dae459e2a5fb4992b4ef53fe4829fe8c35b2edd
-
moto authored
Summary: Following https://github.com/pytorch/audio/pull/3232, static build of flashlight-text has been disabled and removed from nightly build. This commit removes the related source/build from torchaudio code base. Pull Request resolved: https://github.com/pytorch/audio/pull/3236 Reviewed By: jacobkahn Differential Revision: D44712539 Pulled By: mthrok fbshipit-source-id: a201c89b5046f224526309cd4e17a5105e58a949
-
- 04 Apr, 2023 4 commits
-
-
moto authored
Summary: Recently, we added bunch of options to make StreamReader/Writer flexible. As a result, their methods have many number of arguments, and some of them have semantic grouping. For example, the arguments of ``StreamWriter.add_video_stream`` are roughly grouped as follow; - Information about input media format `frame_rate`, `width`, `height`, `format` - Information about encoder `encoder`, `encoder_option` - Information about codec configuration `codec_config` - Information about encode media format `encoder_format`, `encoder_frame_rate`, `encoder_width`, `encoder_height` - Information about additional processing `filter_desc` - Hardware acceleration `hw_accel` We do not know what arguments will be added in the future, but when we do, we want to keep them roughly grouped, by inserting the new argument somewhere in a middle without breaking backward compatibility. This commit puts most of them in keyword-only argument, so that we can rearrange them without breaking backward compatibility. Pull Request resolved: https://github.com/pytorch/audio/pull/3227 Reviewed By: hwangjeff Differential Revision: D44681620 Pulled By: mthrok fbshipit-source-id: b55f6168f4c2f3d0f59731b9bb0db4ae54e5a90f
-
moto authored
Summary: As we migrate to use upstream flashlight-text and KenLM, this PR disable building CTC decoder by default. This will stop shipping flashlight-text and KenLM bundle in torchaudio binary. Ref: https://github.com/pytorch/audio/issues/3088 cc jacobkahn Pull Request resolved: https://github.com/pytorch/audio/pull/3232 Reviewed By: hwangjeff Differential Revision: D44650872 Pulled By: mthrok fbshipit-source-id: 2415623abaf3cafa181135db5112d3c711137cd7
-
hwangjeff authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3235 Reviewed By: mthrok Differential Revision: D44653654 Pulled By: hwangjeff fbshipit-source-id: f28a6068e826581d76ed4a216adb6019b6486e53
-
moto authored
Summary: Linux GPU unit test on CircleCI relies on custom Docker image with CUDA 10.2. PyTorch 2.0 does not support CUDA 10, so these tests have not run for a while. We have GPU tests on GHA for Linux, so we can get rid of them. Windows GPU tests are not ported to GHA yet, but they are still working on CircleCI, so we don't delete them yet. Pull Request resolved: https://github.com/pytorch/audio/pull/3231 Reviewed By: hwangjeff Differential Revision: D44639302 Pulled By: mthrok fbshipit-source-id: c1fd39f4805a50a12af4259d423985fe453fd229
-
- 03 Apr, 2023 4 commits
-
-
moto authored
Summary: Currently, creating CTCDecoder object by passing a language model to `lm` argument without assigning it to a variable elsewhere causes `RuntimeError: Tried to call pure virtual function "LM::start"`. According to discussions on PyBind11, ( https://github.com/pybind/pybind11/discussions/4013 and https://github.com/pybind/pybind11/pull/2839 ) this is due to Python object garbage-collected by the time it's used by code implemented in C++. It attempts to call methods defined in Python, which overrides the base pure virtual function, but the object which provides this override gets deleted by garbage collrector, as the original object is not reference counted. This commit fixes this by simply assiging the given `lm` object as an attribute of CTCDecoder class. Address https://github.com/pytorch/audio/issues/3218 Pull Request resolved: https://github.com/pytorch/audio/pull/3230 Reviewed By: hwangjeff Differential Revision: D44642989 Pulled By: mthrok fbshipit-source-id: a90af828c7c576bc0eb505164327365ebaadc471
-
Moto Hira authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3233 Log usage when cuvid/nvenc is called. Reviewed By: nateanl Differential Revision: D44569410 fbshipit-source-id: 7c1e9fe70134af29c784fd076d1b128c9d2e0066
-
moto authored
Summary: Utilities functions are only available to Python, so no need to use TorchBind for them. This should allow us to remove link-whole flag when linking `libtorchaudio_ffmpeg` part. Pull Request resolved: https://github.com/pytorch/audio/pull/3228 Reviewed By: nateanl Differential Revision: D44639560 Pulled By: mthrok fbshipit-source-id: 5116073ee8c5ab572c63ad123942c4826bfe1100
-
moto authored
Summary: Initial step to migrate to upstream CTC decoder. https://circleci.com/api/v1.1/project/github/pytorch/audio/1174432/output/107/0?file=true&allocation-id=642636c6eaaa102ce75beb8e-0-build%2FB77C8AB Pull Request resolved: https://github.com/pytorch/audio/pull/3225 Reviewed By: nateanl Differential Revision: D44581338 Pulled By: mthrok fbshipit-source-id: 1517fa0cd5e4ba001d136eb0dfc2a9349afcd2da
-
- 01 Apr, 2023 1 commit
-
-
moto authored
Summary: This commit adds a new feature AudioEffector, which can be used to apply various effects and codecs to waveforms in Tensor. Under the hood it uses StreamWriter and StreamReader to apply filters and encode/decode. This is going to replace the deprecated `apply_codec` and `apply_sox_effect_tensor` functions. It can also perform online, chunk-by-chunk filtering. Tutorial to follow. closes https://github.com/pytorch/audio/issues/3161 Pull Request resolved: https://github.com/pytorch/audio/pull/3163 Reviewed By: hwangjeff Differential Revision: D44576660 Pulled By: mthrok fbshipit-source-id: 2c5cc87082ab431315d29d56d6ac9efaf4cf7aeb
-
- 31 Mar, 2023 3 commits
-
-
Nouran Ali authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3222 Reviewed By: nateanl Differential Revision: D44539424 Pulled By: mthrok fbshipit-source-id: 8fbcb5f9918c9930c939bcd448493fa5cf604545
-
Jeff Hwang authored
Summary: Pull Request resolved: https://github.com/pytorch/audio/pull/3223 Each `StreamProcessor` is responsible for processing a source stream. In the case where we support packet passthrough, `StreamProcessor`'s choice of decoder is irrelevant as no decoding is performed. Currently, however, `StreamProcessor` requires decoder params and fixes a decoder at construction time. To accommodate this future packet passthrough use case, this PR decouples the construction of `StreamProcessor` from the configuration of the decoder that it uses. Reviewed By: mthrok Differential Revision: D44554934 fbshipit-source-id: 1d1a89015e1181b71dfb95c928de4fc3ec6f63b6
-
moto authored
Summary: This commit adds the equivalent of `qscale` option in FFmpeg to StreamWriter.CodecConfig. `qscale` enables variable bit rate. The following figure illustrates the difference between currently available configs. From top to bottom; original, `compression_level=1`, `compression_level=9`, `bit_rate=192k`, `bit_rate=8k`, `qscale=9`, `qscale=1`. 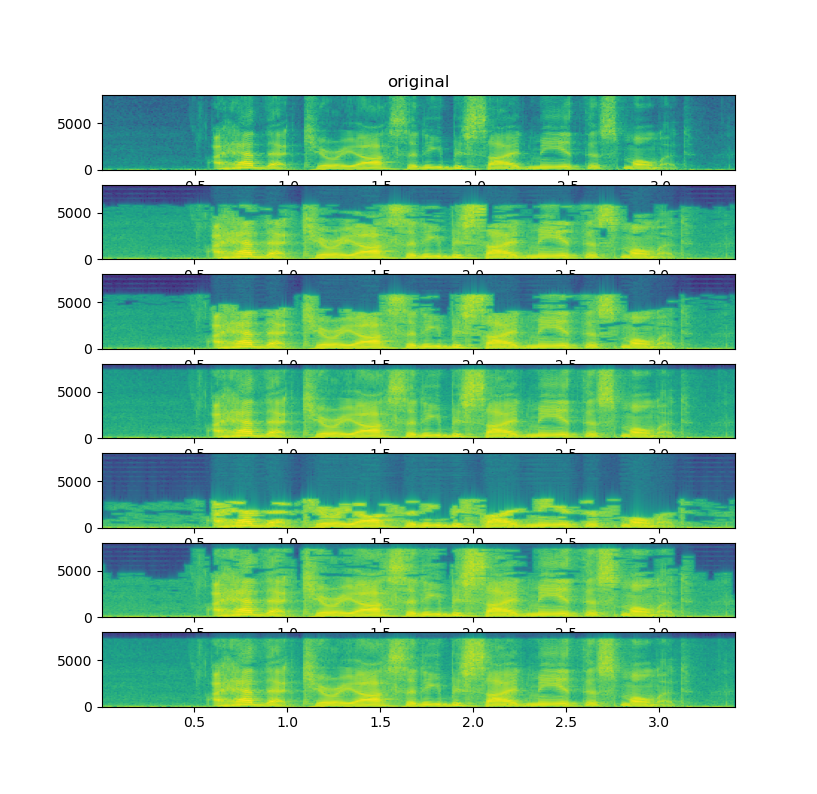 Pull Request resolved: https://github.com/pytorch/audio/pull/3224 Reviewed By: hwangjeff Differential Revision: D44563633 Pulled By: mthrok fbshipit-source-id: ff74cd803b5abf1222f087e3e46ba7d81a35f672
-
- 30 Mar, 2023 1 commit
-
-
moto authored
Summary: This commit adds support for changing the spec of media (such as sample rate, #channels, image size and frame rate) on-the-fly at encoding time. The motivation behind this addition is that certain media formats support only limited number of spec, and it is cumbersome to require client code to change the spec every time. For example, OPUS supports only 48kHz sampling rate, and vorbis only supports stereo. To make it easy to work with media of different formats, this commit makes it so that anything that's not compatible with the format is automatically converted, and allows users to specify the override. Notable implementation detail is that, for sample format and pixel format, the default value of encoder has higher precedent to source value, while for other attributes like sample rate and #channels, the source value has higher precedent as long as they are supported. Pull Request resolved: https://github.com/pytorch/audio/pull/3207 Reviewed By: nateanl Differential Revision: D44439622 Pulled By: mthrok fbshipit-source-id: 09524f201d485d201150481884a3e9e4d2aab081
-









