
Refactor and optimize yuv420p and nv12 processing (#2945)
Summary:
This commit refactors and optimizes functions that converts AVFrames of `yuv420p` and `nv12` into PyTorch's Tensor.
The performance is improved about 30%.
1. Reduce the number of intermediate Tensors allocated.
2. Replace 2 calls to `repeat_interleave` with `F::interpolate`.
* (`F::interpolate` is about 5x faster than `repeat_interleave`. )
<details><summary>code</summary>
```bash
#!/usr/bin/env bash
set -e
python -c """
import torch
import torch.nn.functional as F
a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone()
val1 = a.repeat_interleave(2, -1).repeat_interleave(2, -2)
val2 = F.interpolate(a.view((1, 1, 7, 7, 1)), size=[14, 14, 1], mode=\"nearest\")
print(torch.sum(torch.abs(val1 - val2[0, 0, :, :, 0])))
"""
python3 -m timeit \
--setup """
import torch
a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone()
""" \
"""
a.repeat_interleave(2, -1).repeat_interleave(2, -2)
"""
python3 -m timeit \
--setup """
import torch
import torch.nn.functional as F
a = torch.arange(49, dtype=torch.uint8).reshape(7, 7).clone()
""" \
"""
F.interpolate(a.view((1, 1, 7, 7, 1)), size=[14, 14, 1], mode=\"nearest\")
"""
```
</details>
```
tensor(0)
10000 loops, best of 5: 38.3 usec per loop
50000 loops, best of 5: 7.1 usec per loop
```
## Benchmark Result
<details><summary>code</summary>
```bash
#!/usr/bin/env bash
set -e
mkdir -p tmp
for ext in avi mp4; do
for duration in 1 5 10 30 60; do
printf "Testing ${ext} ${duration} [sec]\n"
test_data="tmp/test_${duration}.${ext}"
if [ ! -f "${test_data}" ]; then
printf "Generating test data\n"
ffmpeg -hide_banner -f lavfi -t ${duration} -i testsrc "${test_data}" > /dev/null 2>&1
fi
python -m timeit \
--setup="from torchaudio.io import StreamReader" \
"""
r = StreamReader(\"${test_data}\")
r.add_basic_video_stream(frames_per_chunk=-1, format=\"yuv420p\")
r.process_all_packets()
r.pop_chunks()
"""
done
done
```
</details>
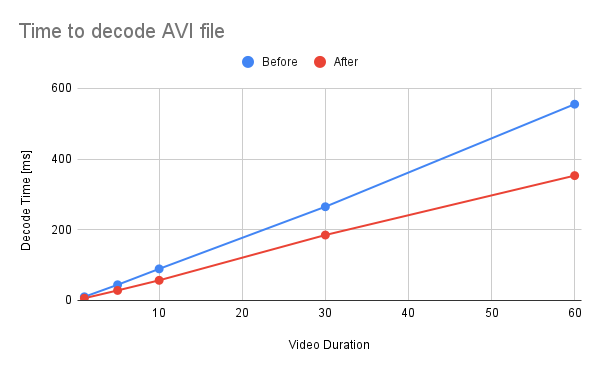
<details><summary>raw data</summary>
Video Type - AVI
Duration | Before | After
-- | -- | --
1 | 10.3 | 6.29
5 | 44.3 | 28.3
10 | 89.3 | 56.9
30 | 265 | 185
60 | 555 | 353
</details>
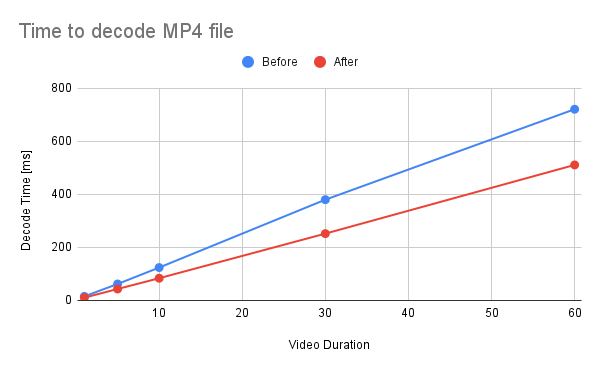
<details><summary>raw data</summary>
Video Type - MP4
Duration | Before | After
-- | -- | --
1 | 15.3 | 10.5
5 | 62.1 | 43.2
10 | 124 | 83.8
30 | 380 | 252
60 | 721 | 511
</details>
Pull Request resolved: https://github.com/pytorch/audio/pull/2945
Reviewed By: carolineechen
Differential Revision: D42283269
Pulled By: mthrok
fbshipit-source-id: 59840f943ff516b69ab8ad35fed7104c48a0bf0c
Showing
Please register or sign in to comment