
docs: add reference to docs.ollama.com (#12800)
Showing
{kind=link}
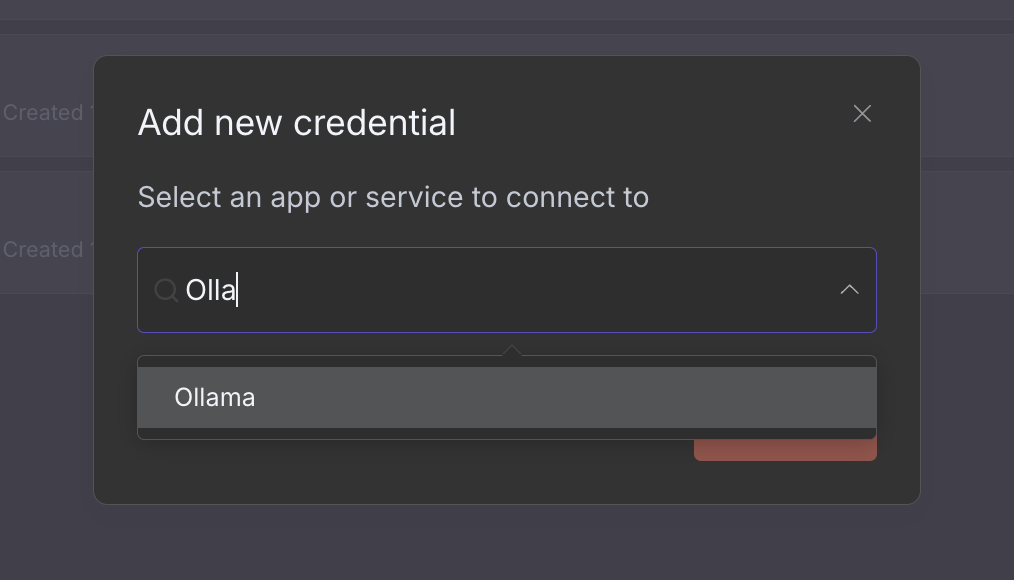
52.6 KB
{kind=link}
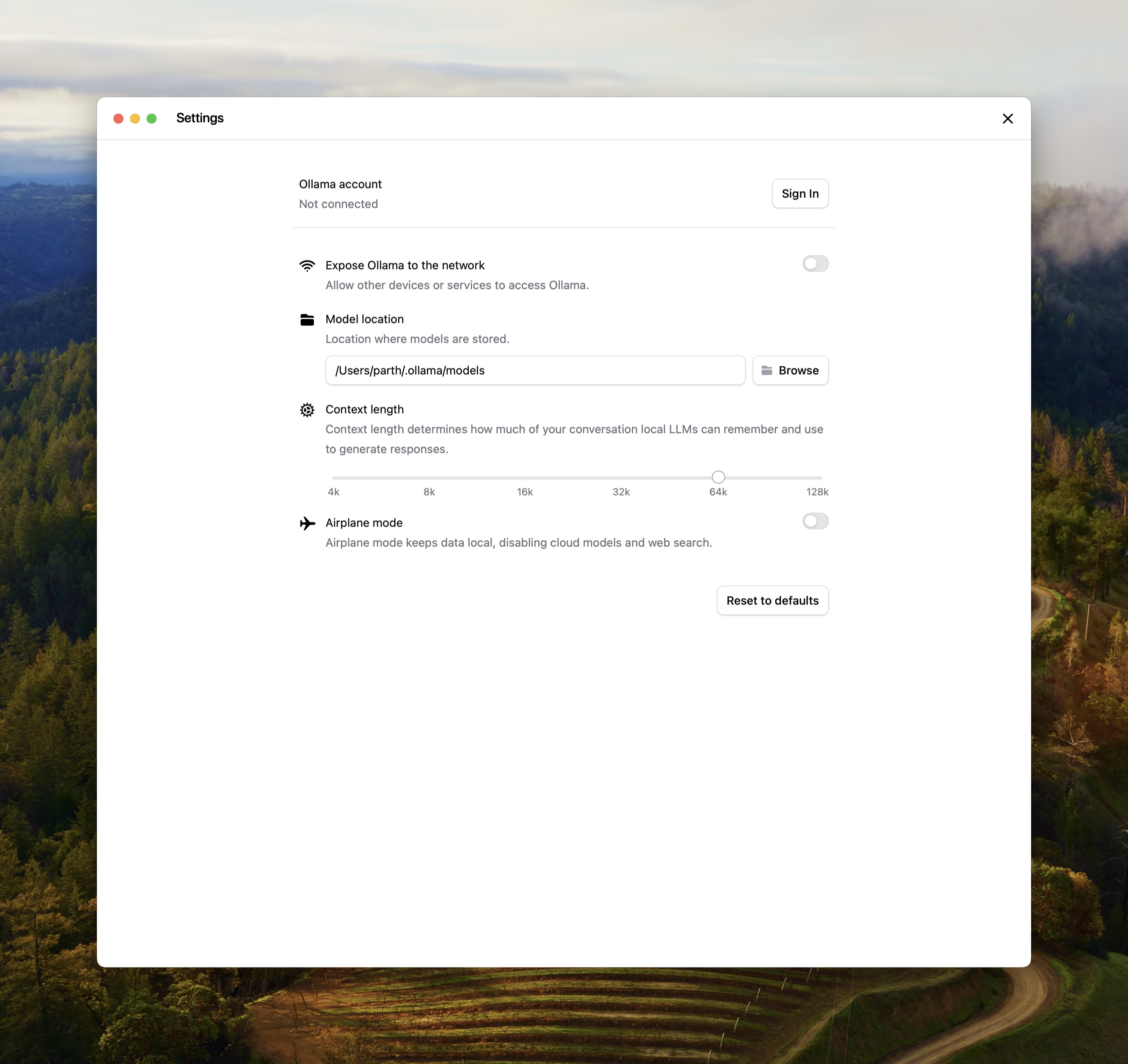
3.57 MB
{kind=link}
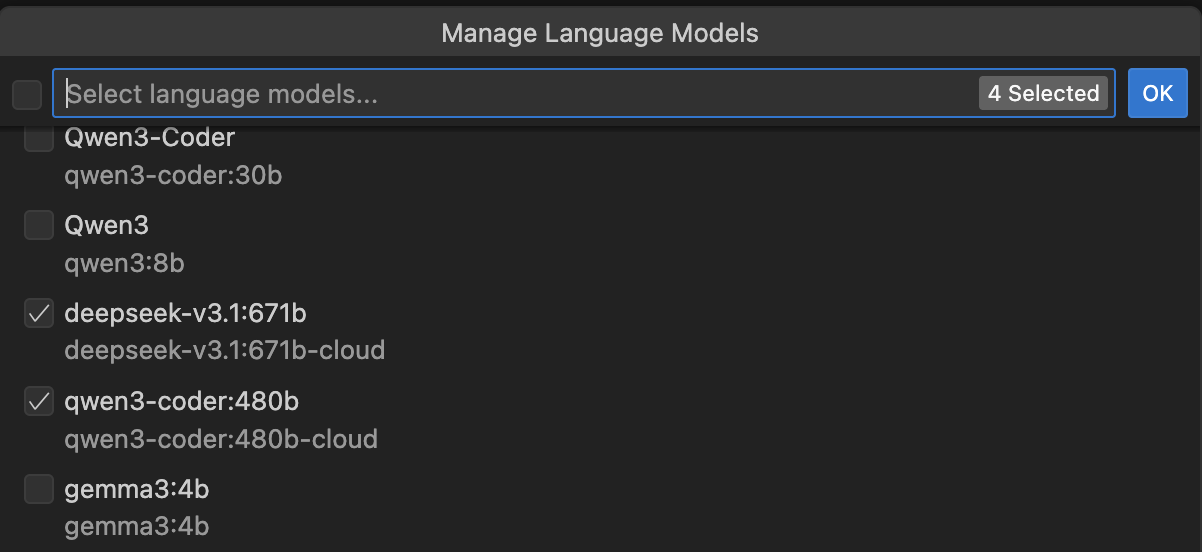
76.6 KB
{kind=link}
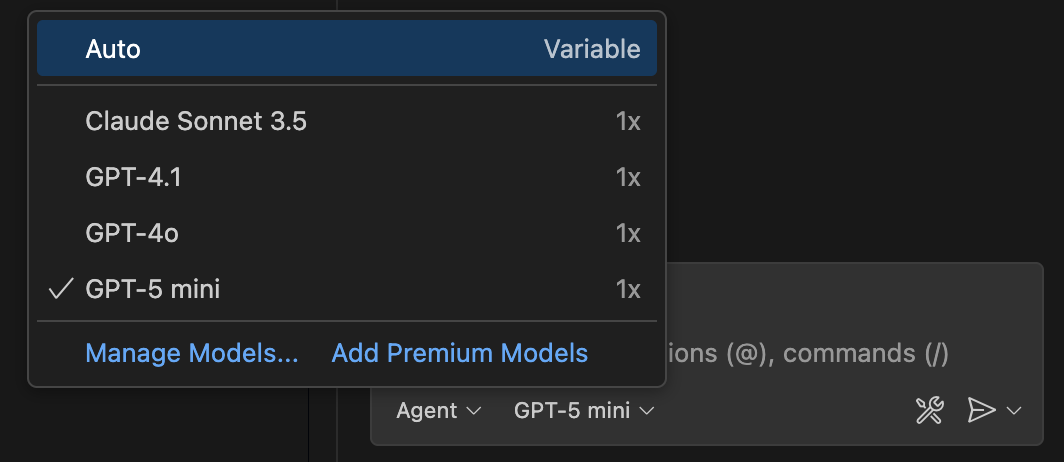
55.5 KB
{kind=link}
25.2 KB
docs/images/welcome.png
0 → 100644
{kind=link}
233 KB
{kind=link}
186 KB
{kind=link}
182 KB
{kind=link}
146 KB
{kind=link}
38.4 KB
docs/images/zed-settings.png
0 → 100644
{kind=link}
57.1 KB
docs/import.mdx
0 → 100644
docs/index.mdx
0 → 100644
docs/integrations/cline.mdx
0 → 100644
docs/integrations/codex.mdx
0 → 100644
docs/integrations/droid.mdx
0 → 100644
docs/integrations/goose.mdx
0 → 100644
docs/integrations/n8n.mdx
0 → 100644