Currently, we have several filter pruning algorithm for the convolutional layers: FPGM Pruner, L1Filter Pruner, L2Filter Pruner, Activation APoZ Rank Filter Pruner, Activation Mean Rank Filter Pruner, Taylor FO On Weight Pruner. In these filter pruning algorithms, the pruner will prune each convolutional layer separately. While pruning a convolution layer, the algorithm will quantify the importance of each filter based on some specific rules(such as l1-norm), and prune the less important filters.
As [dependency analysis utils](./CompressionUtils.md) shows, if the output channels of two convolutional layers(conv1, conv2) are added together, then these two conv layers have channel dependency with each other(more details please see [Compression Utils](./CompressionUtils.md)). Take the following figure as an example.

If we prune the first 50% of output channels(filters) for conv1, and prune the last 50% of output channels for conv2. Although both layers have pruned 50% of the filters, the speedup module still needs to add zeros to align the output channels. In this case, we cannot harvest the speed benefit from the model pruning.
To better gain the speed benefit of the model pruning, we add a dependency-aware mode for the Filter Pruner. In the dependency-aware mode, the pruner prunes the model not only based on the l1 norm of each filter, but also the topology of the whole network architecture.
In the dependency-aware mode(`dependency_aware` is set `True`), the pruner will try to prune the same output channels for the layers that have the channel dependencies with each other, as shown in the following figure.

Take the dependency-aware mode of L1Filter Pruner as an example. Specifically, the pruner will calculate the L1 norm (for example) sum of all the layers in the dependency set for each channel. Obviously, the number of channels that can actually be pruned of this dependency set in the end is determined by the minimum sparsity of layers in this dependency set(denoted by `min_sparsity`). According to the L1 norm sum of each channel, the pruner will prune the same `min_sparsity` channels for all the layers. Next, the pruner will additionally prune `sparsity` - `min_sparsity` channels for each convolutional layer based on its own L1 norm of each channel. For example, suppose the output channels of `conv1` , `conv2` are added together and the configured sparsities of `conv1` and `conv2` are 0.3, 0.2 respectively. In this case, the `dependency-aware pruner` will
- First, prune the same 20% of channels for `conv1` and `conv2` according to L1 norm sum of `conv1` and `conv2`.
- Second, the pruner will additionally prune 10% channels for `conv1` according to the L1 norm of each channel of `conv1`.
In addition, for the convolutional layers that have more than one filter group, `dependency-aware pruner` will also try to prune the same number of the channels for each filter group. Overall, this pruner will prune the model according to the L1 norm of each filter and try to meet the topological constrains(channel dependency, etc) to improve the final speed gain after the speedup process.
In the dependency-aware mode, the pruner will provide a better speed gain from the model pruning.
## Usage
In this section, we will show how to enable the dependency-aware mode for the filter pruner. Currently, only the one-shot pruners such as FPGM Pruner, L1Filter Pruner, L2Filter Pruner, Activation APoZ Rank Filter Pruner, Activation Mean Rank Filter Pruner, Taylor FO On Weight Pruner, support the dependency-aware mode.
To enable the dependency-aware mode for `L1FilterPruner`:
In order to compare the performance of the pruner with or without the dependency-aware mode, we use L1FilterPruner to prune the Mobilenet_v2 separately when the dependency-aware mode is turned on and off. To simplify the experiment, we use the uniform pruning which means we allocate the same sparsity for all convolutional layers in the model.
We trained a Mobilenet_v2 model on the cifar10 dataset and prune the model based on this pretrained checkpoint. The following figure shows the accuracy and FLOPs of the model pruned by different pruners.

In the figure, the `Dependency-aware` represents the L1FilterPruner with dependency-aware mode enabled. `L1 Filter` is the normal `L1FilterPruner` without the dependency-aware mode, and the `No-Dependency` means pruner only prunes the layers that has no channel dependency with other layers. As we can see in the figure, when the dependency-aware mode enabled, the pruner can bring higher accuracy under the same Flops.
@@ -114,7 +114,9 @@ FPGMPruner prune filters with the smallest geometric median.

>Previous works utilized “smaller-norm-less-important” criterion to prune filters with smaller norm values in a convolutional neural network. In this paper, we analyze this norm-based criterion and point out that its effectiveness depends on two requirements that are not always met: (1) the norm deviation of the filters should be large; (2) the minimum norm of the filters should be small. To solve this problem, we propose a novel filter pruning method, namely Filter Pruning via Geometric Median (FPGM), to compress the model regardless of those two requirements. Unlike previous methods, FPGM compresses CNN models by pruning filters with redundancy, rather than those with “relatively less” importance.
>Previous works utilized “smaller-norm-less-important” criterion to prune filters with smaller norm values in a convolutional neural network. In this paper, we analyze this norm-based criterion and point out that its effectiveness depends on two requirements that are not always met: (1) the norm deviation of the filters should be large; (2) the minimum norm of the filters should be small. To solve this problem, we propose a novel filter pruning method, namely Filter Pruning via Geometric Median (FPGM), to compress the model regardless of those two requirements. Unlike previous methods, FPGM compresses CNN models by pruning filters with redundancy, rather than those with “relatively less” importance.
We also provide a dependency-aware mode for this pruner to get better speedup from the pruning. Please reference [dependency-aware](./DependencyAware.md) for more details.
### Usage
...
...
@@ -154,6 +156,8 @@ This is an one-shot pruner, In ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https:
> 4. A new kernel matrix is created for both the th and 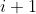th layers, and the remaining kernel
> weights are copied to the new model.
In addition, we also provide a dependency-aware mode for the L1FilterPruner. For more details about the dependency-aware mode, please reference [dependency-aware mode](./DependencyAware.md).
### Usage
PyTorch code
...
...
@@ -189,6 +193,8 @@ The experiments code can be found at [examples/model_compress]( https://github.c
This is a structured pruning algorithm that prunes the filters with the smallest L2 norm of the weights. It is implemented as a one-shot pruner.
We also provide a dependency-aware mode for this pruner to get better speedup from the pruning. Please reference [dependency-aware](./DependencyAware.md) for more details.
ActivationAPoZRankFilter Pruner is a pruner which prunes the filters with the smallest importance criterion `APoZ` calculated from the output activations of convolution layers to achieve a preset level of network sparsity. The pruning criterion `APoZ` is explained in the paper [Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures](https://arxiv.org/abs/1607.03250).
...
...
@@ -216,6 +224,8 @@ The APoZ is defined as:

We also provide a dependency-aware mode for this pruner to get better speedup from the pruning. Please reference [dependency-aware](./DependencyAware.md) for more details.
### Usage
PyTorch code
...
...
@@ -234,6 +244,8 @@ Note: ActivationAPoZRankFilterPruner is used to prune convolutional layers withi
You can view [example](https://github.com/microsoft/nni/blob/master/examples/model_compress/model_prune_torch.py) for more information.
### User configuration for ActivationAPoZRankFilter Pruner
##### PyTorch
...
...
@@ -247,6 +259,8 @@ You can view [example](https://github.com/microsoft/nni/blob/master/examples/mod
ActivationMeanRankFilterPruner is a pruner which prunes the filters with the smallest importance criterion `mean activation` calculated from the output activations of convolution layers to achieve a preset level of network sparsity. The pruning criterion `mean activation` is explained in section 2.2 of the paper[Pruning Convolutional Neural Networks for Resource Efficient Inference](https://arxiv.org/abs/1611.06440). Other pruning criteria mentioned in this paper will be supported in future release.
We also provide a dependency-aware mode for this pruner to get better speedup from the pruning. Please reference [dependency-aware](./DependencyAware.md) for more details.
### Usage
PyTorch code
...
...
@@ -265,6 +279,7 @@ Note: ActivationMeanRankFilterPruner is used to prune convolutional layers withi
You can view [example](https://github.com/microsoft/nni/blob/master/examples/model_compress/model_prune_torch.py) for more information.
### User configuration for ActivationMeanRankFilterPruner
##### PyTorch
...
...
@@ -273,6 +288,7 @@ You can view [example](https://github.com/microsoft/nni/blob/master/examples/mod
```
***
## TaylorFOWeightFilter Pruner
TaylorFOWeightFilter Pruner is a pruner which prunes convolutional layers based on estimated importance calculated from the first order taylor expansion on weights to achieve a preset level of network sparsity. The estimated importance of filters is defined as the paper [Importance Estimation for Neural Network Pruning](http://jankautz.com/publications/Importance4NNPruning_CVPR19.pdf). Other pruning criteria mentioned in this paper will be supported in future release.
...
...
@@ -281,6 +297,8 @@ TaylorFOWeightFilter Pruner is a pruner which prunes convolutional layers based

We also provide a dependency-aware mode for this pruner to get better speedup from the pruning. Please reference [dependency-aware](./DependencyAware.md) for more details.

{kind=link}

{kind=link}

{kind=link}
