
Merge pull request #223 from microsoft/master
merge master
Showing
docs/img/apoz.png
0 → 100644
{kind=link}
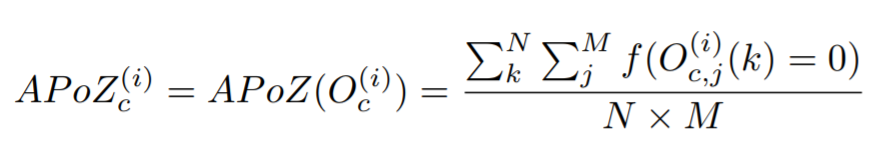
36.1 KB
docs/img/fpgm_fig1.png
0 → 100644
{kind=link}
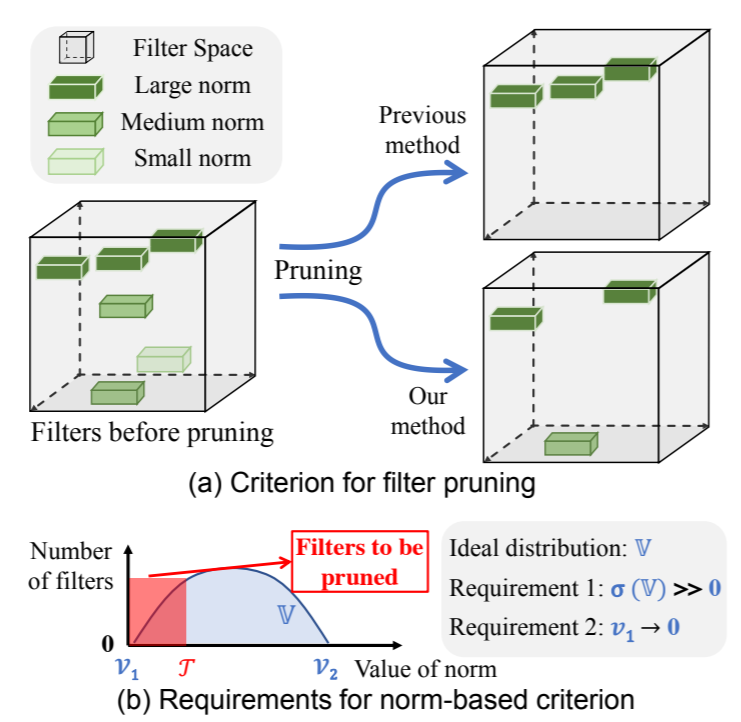
111 KB
examples/nas/spos/README.md
0 → 100644
examples/nas/spos/blocks.py
0 → 100644
examples/nas/spos/network.py
0 → 100644
examples/nas/spos/scratch.py
0 → 100644
examples/nas/spos/tester.py
0 → 100644