NNI supports running an experiment on `DLTS <https://github.com/microsoft/DLWorkspace.git>`__\ , called dlts mode. Before starting to use NNI dlts mode, you should have an account to access DLTS dashboard.
Setup Environment
-----------------
Step 1. Choose a cluster from DLTS dashboard, ask administrator for the cluster dashboard URL.
.. image:: ../../img/dlts-step1.png
:target: ../../img/dlts-step1.png
:alt: Choose Cluster
Step 2. Prepare a NNI config YAML like the following:
.. code-block:: yaml
# Set this field to "dlts"
trainingServicePlatform: dlts
authorName: your_name
experimentName: auto_mnist
trialConcurrency: 2
maxExecDuration: 3h
maxTrialNum: 100
searchSpacePath: search_space.json
useAnnotation: false
tuner:
builtinTunerName: TPE
classArgs:
optimize_mode: maximize
trial:
command: python3 mnist.py
codeDir: .
gpuNum: 1
image: msranni/nni
# Configuration to access DLTS
dltsConfig:
dashboard: # Ask administrator for the cluster dashboard URL
Remember to fill the cluster dashboard URL to the last line.
Step 3. Open your working directory of the cluster, paste the NNI config as well as related code to a directory.
.. image:: ../../img/dlts-step3.png
:target: ../../img/dlts-step3.png
:alt: Copy Config
Step 4. Submit a NNI manager job to the specified cluster.
.. image:: ../../img/dlts-step4.png
:target: ../../img/dlts-step4.png
:alt: Submit Job
Step 5. Go to Endpoints tab of the newly created job, click the Port 40000 link to check trial's information.
1.3 Report NNI results: Use the API: ``nni.report_intermediate_result(accuracy)`` to send ``accuracy`` to assessor. Use the API: ``nni.report_final_result(accuracy)`` to send `accuracy` to tuner.
**NOTE**\ :
.. code-block:: bash
accuracy - The `accuracy` could be any python object, but if you use NNI built-in tuner/assessor, `accuracy` should be a numerical variable (e.g. float, int).
tuner - The tuner will generate next parameters/architecture based on the explore history (final result of all trials).
assessor - The assessor will decide which trial should early stop based on the history performance of trial (intermediate result of one trial).
..
Step 2 - Define SearchSpace
The hyper-parameters used in ``Step 1.2 - Get predefined parameters`` is defined in a ``search_space.json`` file like below:
Refer to `define search space <../Tutorial/SearchSpaceSpec.rst>`__ to learn more about search space.
..
Step 3 - Define Experiment
..
To run an experiment in NNI, you only needed:
* Provide a runnable trial
* Provide or choose a tuner
* Provide a YAML experiment configure file
* (optional) Provide or choose an assessor
**Prepare trial**\ :
..
You can download nni source code and a set of examples can be found in ``nni/examples``, run ``ls nni/examples/trials`` to see all the trial examples.
Let's use a simple trial example, e.g. mnist, provided by NNI. After you cloned NNI source, NNI examples have been put in ~/nni/examples, run ``ls ~/nni/examples/trials`` to see all the trial examples. You can simply execute the following command to run the NNI mnist example:
This command will be filled in the YAML configure file below. Please refer to `here <../TrialExample/Trials.rst>`__ for how to write your own trial.
**Prepare tuner**\ : NNI supports several popular automl algorithms, including Random Search, Tree of Parzen Estimators (TPE), Evolution algorithm etc. Users can write their own tuner (refer to `here <../Tuner/CustomizeTuner.rst>`__\ ), but for simplicity, here we choose a tuner provided by NNI as below:
.. code-block:: bash
tuner:
name: TPE
classArgs:
optimize_mode: maximize
*name* is used to specify a tuner in NNI, *classArgs* are the arguments pass to the tuner (the spec of builtin tuners can be found `here <../Tuner/BuiltinTuner.rst>`__\ ), *optimization_mode* is to indicate whether you want to maximize or minimize your trial's result.
**Prepare configure file**\ : Since you have already known which trial code you are going to run and which tuner you are going to use, it is time to prepare the YAML configure file. NNI provides a demo configure file for each trial example, ``cat ~/nni/examples/trials/mnist-pytorch/config.yml`` to see it. Its content is basically shown below:
You can refer to `here <../Tutorial/Nnictl.rst>`__ for more usage guide of *nnictl* command line tool.
View experiment results
-----------------------
The experiment has been running now. Other than *nnictl*\ , NNI also provides WebUI for you to view experiment progress, to control your experiment, and some other appealing features.
Using multiple local GPUs to speed up search
--------------------------------------------
The following steps assume that you have 4 NVIDIA GPUs installed at local and PyTorch with CUDA support. The demo enables 4 concurrent trail jobs and each trail job uses 1 GPU.
**Prepare configure file**\ : NNI provides a demo configuration file for the setting above, ``cat ~/nni/examples/trials/mnist-pytorch/config_detailed.yml`` to see it. The trailConcurrency and trialGpuNumber are different from the basic configure file:
.. code-block:: bash
...
trialGpuNumber: 1
trialConcurrency: 4
...
trainingService:
platform: local
useActiveGpu: false # set to "true" if you are using graphical OS like Windows 10 and Ubuntu desktop
We can run the experiment with the following command:
You can use *nnictl* command line tool or WebUI to trace the training progress. *nvidia_smi* command line tool can also help you to monitor the GPU usage during training.
Now NNI supports running experiment on `AdaptDL <https://github.com/petuum/adaptdl>`__. Before starting to use NNI AdaptDL mode, you should have a Kubernetes cluster, either on-premises or `Azure Kubernetes Service(AKS) <https://azure.microsoft.com/en-us/services/kubernetes-service/>`__\ , a Ubuntu machine on which `kubeconfig <https://kubernetes.io/docs/concepts/configuration/organize-cluster-access-kubeconfig/>`__ is setup to connect to your Kubernetes cluster. In AdaptDL mode, your trial program will run as AdaptDL job in Kubernetes cluster.
Now NNI supports running experiment on `AdaptDL <https://github.com/petuum/adaptdl>`__, which is a resource-adaptive deep learning training and scheduling framework. With AdaptDL training service, your trial program will run as AdaptDL job in Kubernetes cluster.
AdaptDL aims to make distributed deep learning easy and efficient in dynamic-resource environments such as shared clusters and the cloud.
AdaptDL aims to make distributed deep learning easy and efficient in dynamic-resource environments such as shared clusters and the cloud.
Prerequisite for Kubernetes Service
Prerequisite
-----------------------------------
------------
Before starting to use NNI AdaptDL training service, you should have a Kubernetes cluster, either on-premises or `Azure Kubernetes Service(AKS) <https://azure.microsoft.com/en-us/services/kubernetes-service/>`__\ , a Ubuntu machine on which `kubeconfig <https://kubernetes.io/docs/concepts/configuration/organize-cluster-access-kubeconfig/>`__ is setup to connect to your Kubernetes cluster.
#. A **Kubernetes** cluster using Kubernetes 1.14 or later with storage. Follow this guideline to set up Kubernetes `on Azure <https://azure.microsoft.com/en-us/services/kubernetes-service/>`__\ , or `on-premise <https://kubernetes.io/docs/setup/>`__ with `cephfs <https://kubernetes.io/docs/concepts/storage/storage-classes/#ceph-rbd>`__\ , or `microk8s with storage add-on enabled <https://microk8s.io/docs/addons>`__.
#. A **Kubernetes** cluster using Kubernetes 1.14 or later with storage. Follow this guideline to set up Kubernetes `on Azure <https://azure.microsoft.com/en-us/services/kubernetes-service/>`__\ , or `on-premise <https://kubernetes.io/docs/setup/>`__ with `cephfs <https://kubernetes.io/docs/concepts/storage/storage-classes/#ceph-rbd>`__\ , or `microk8s with storage add-on enabled <https://microk8s.io/docs/addons>`__.
#. Helm install **AdaptDL Scheduler** to your Kubernetes cluster. Follow this `guideline <https://adaptdl.readthedocs.io/en/latest/installation/install-adaptdl.html>`__ to setup AdaptDL scheduler.
#. Helm install **AdaptDL Scheduler** to your Kubernetes cluster. Follow this `guideline <https://adaptdl.readthedocs.io/en/latest/installation/install-adaptdl.html>`__ to setup AdaptDL scheduler.
#. Prepare a **kubeconfig** file, which will be used by NNI to interact with your Kubernetes API server. By default, NNI manager will use ``$(HOME)/.kube/config`` as kubeconfig file's path. You can also specify other kubeconfig files by setting the **KUBECONFIG** environment variable. Refer this `guideline <https://kubernetes.io/docs/concepts/configuration/organize-cluster-access-kubeconfig>`__ to learn more about kubeconfig.
#. Prepare a **kubeconfig** file, which will be used by NNI to interact with your Kubernetes API server. By default, NNI manager will use ``$(HOME)/.kube/config`` as kubeconfig file's path. You can also specify other kubeconfig files by setting the **KUBECONFIG** environment variable. Refer this `guideline <https://kubernetes.io/docs/concepts/configuration/organize-cluster-access-kubeconfig>`__ to learn more about kubeconfig.
#. If your NNI trial job needs GPU resource, you should follow this `guideline <https://github.com/NVIDIA/k8s-device-plugin>`__ to configure **Nvidia device plugin for Kubernetes**.
#. If your NNI trial job needs GPU resource, you should follow this `guideline <https://github.com/NVIDIA/k8s-device-plugin>`__ to configure **Nvidia device plugin for Kubernetes**.
#. (Optional) Prepare a **NFS server** and export a general purpose mount as external storage.
#. (Optional) Prepare a **NFS server** and export a general purpose mount as external storage.
#. Install **NNI**\ , follow the install guide `here <../Tutorial/QuickStart.rst>`__.
#. Install **NNI**\ , follow the install guide :doc:`../installation`.
Verify Prerequisites
Verify the Prerequisites
^^^^^^^^^^^^^^^^^^^^
^^^^^^^^^^^^^^^^^^^^^^^^
.. code-block:: bash
.. code-block:: bash
...
@@ -34,10 +34,10 @@ Verify Prerequisites
...
@@ -34,10 +34,10 @@ Verify Prerequisites
kubectl api-versions | grep adaptdl
kubectl api-versions | grep adaptdl
# Expected: adaptdl.petuum.com/v1
# Expected: adaptdl.petuum.com/v1
Run an experiment
Usage
-----------------
-----
We have a CIFAR10 example that fully leverages the AdaptDL scheduler under ``examples/trials/cifar10_pytorch`` folder. (\ ``main_adl.py`` and ``config_adl.yaml``\ )
We have a CIFAR10 example that fully leverages the AdaptDL scheduler under :githublink:`examples/trials/cifar10_pytorch` folder. (:githublink:`main_adl.py <examples/trials/cifar10_pytorch/main_adl.py>` and :githublink:`config_adl.yaml <examples/trials/cifar10_pytorch/config_adl.yaml>`)
Here is a template configuration specification to use AdaptDL as a training service.
Here is a template configuration specification to use AdaptDL as a training service.
...
@@ -75,9 +75,10 @@ Here is a template configuration specification to use AdaptDL as a training serv
...
@@ -75,9 +75,10 @@ Here is a template configuration specification to use AdaptDL as a training serv
storageClass: dfs
storageClass: dfs
storageSize: 1Gi
storageSize: 1Gi
Those configs not mentioned below, are following the
.. note::
`default specs defined </Tutorial/ExperimentConfig.rst#configuration-spec>`__ in the NNI doc.
This configuration is written following the specification of `legacy experiment configuration <https://nni.readthedocs.io/en/v2.6/Tutorial/ExperimentConfig.html>`__. It is still supported, and will be updated to the latest version in future release.
The following explains the configuration fields of AdaptDL training service.
* **trainingServicePlatform**\ : Choose ``adl`` to use the Kubernetes cluster with AdaptDL scheduler.
* **trainingServicePlatform**\ : Choose ``adl`` to use the Kubernetes cluster with AdaptDL scheduler.
* **nniManagerIp**\ : *Required* to get the correct info and metrics back from the cluster, for ``adl`` training service.
* **nniManagerIp**\ : *Required* to get the correct info and metrics back from the cluster, for ``adl`` training service.
...
@@ -103,6 +104,9 @@ Those configs not mentioned below, are following the
...
@@ -103,6 +104,9 @@ Those configs not mentioned below, are following the
* **storageClass**\ : check `Kubernetes storage documentation <https://kubernetes.io/docs/concepts/storage/storage-classes/>`__ for how to use the appropriate ``storageClass``.
* **storageClass**\ : check `Kubernetes storage documentation <https://kubernetes.io/docs/concepts/storage/storage-classes/>`__ for how to use the appropriate ``storageClass``.
* **storageSize**\ : this value should be large enough to fit your model's checkpoints, or it could cause "disk quota exceeded" error.
* **storageSize**\ : this value should be large enough to fit your model's checkpoints, or it could cause "disk quota exceeded" error.
More Features
-------------
NFS Storage
NFS Storage
^^^^^^^^^^^
^^^^^^^^^^^
...
@@ -121,7 +125,6 @@ The ``adl`` training service can then mount it to the kubernetes for every trial
...
@@ -121,7 +125,6 @@ The ``adl`` training service can then mount it to the kubernetes for every trial
Use cases:
Use cases:
* If your training trials depend on a dataset of large size, you may want to download it first onto the NFS first,
* If your training trials depend on a dataset of large size, you may want to download it first onto the NFS first,
and mount it so that it can be shared across multiple trials.
and mount it so that it can be shared across multiple trials.
* The storage for containers are ephemeral and the trial containers will be deleted after a trial's lifecycle is over.
* The storage for containers are ephemeral and the trial containers will be deleted after a trial's lifecycle is over.
...
@@ -131,7 +134,7 @@ Use cases:
...
@@ -131,7 +134,7 @@ Use cases:
In short, it is not limited how a trial wants to read from or write on the NFS storage, so you may use it flexibly as per your needs.
In short, it is not limited how a trial wants to read from or write on the NFS storage, so you may use it flexibly as per your needs.
Monitor via Log Stream
Monitor via Log Stream
----------------------
^^^^^^^^^^^^^^^^^^^^^^
Follow the log streaming of a certain trial:
Follow the log streaming of a certain trial:
...
@@ -149,7 +152,7 @@ However you may still be able to access the past trial logs
...
@@ -149,7 +152,7 @@ However you may still be able to access the past trial logs
according to the following approach.
according to the following approach.
Monitor via TensorBoard
Monitor via TensorBoard
-----------------------
^^^^^^^^^^^^^^^^^^^^^^^
In the context of NNI, an experiment has multiple trials.
In the context of NNI, an experiment has multiple trials.
For easy comparison across trials for a model tuning process,
For easy comparison across trials for a model tuning process,
With local training service, the whole experiment (e.g., tuning algorithms, trials) runs on a single machine, i.e., user's dev machine. The generated trials run on this machine following ``trialConcurrency`` set in the configuration yaml file. If GPUs are used by trial, local training service will allocate required number of GPUs for each trial, like a resource scheduler.
Prerequisite
------------
You are recommended to go through quick start first, as this document page only explains the configuration of local training service, one part of the experiment configuration yaml file.
Usage
-----
.. code-block:: yaml
trainingService:
platform: local
useActiveGpu: false # optional
There are other supported fields for local training service, such as ``maxTrialNumberPerGpu``, ``gpuIndices``, for concurrently running multiple trials on one GPU, and running trials on a subset of GPUs on your machine. Please refer to :ref:`reference-local-config-label` in reference for detailed usage.
.. note::
Users should set **useActiveGpu** to `true`, if the local machine has GPUs and your trial uses GPU, but generated trials keep waiting. This is usually the case when you are using graphical OS like Windows 10 and Ubuntu desktop.
Then we explain how local training service works with different configurations of ``trialGpuNumber`` and ``trialConcurrency``. Suppose user's local machine has 4 GPUs, with configuration ``trialGpuNumber: 1`` and ``trialConcurrency: 4``, there will be 4 trials run on this machine concurrently, each of which uses 1 GPU. If the configuration is ``trialGpuNumber: 2`` and ``trialConcurrency: 2``, there will be 2 trials run on this machine concurrently, each of which uses 2 GPUs. Which GPU is allocated to which trial is decided by local training service, users do not need to worry about it. An exmaple configuration below.
.. code-block:: yaml
...
trialGpuNumber: 1
trialConcurrency: 4
...
trainingService:
platform: local
useActiveGpu: false
A complete example configuration file can be found :githublink:`examples/trials/mnist-pytorch/config.yml`.
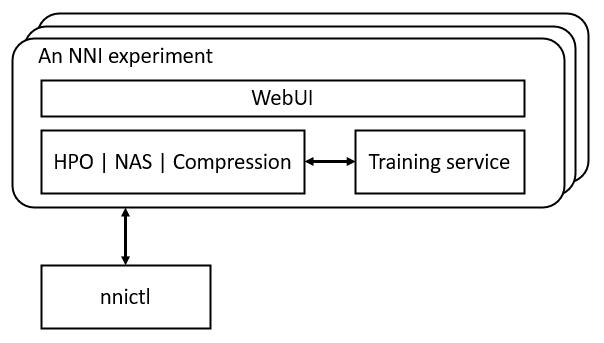
An NNI experiment is a unit of one tuning process. For example, it is one run of hyper-parameter tuning on a specific search space, it is one run of neural architecture search on a search space, or it is one run of automatic model compression on user specified goal on latency and accuracy. Usually, the tuning process requires many trials to explore feasible and potentially good-performing models. Thus, an important component of NNI experiment is **training service**, which is a unified interface to abstract diverse computation resources (e.g., local machine, remote servers, AKS). Users can easily run the tuning process on their prefered computation resource and platform. On the other hand, NNI experiment provides **WebUI** to visualize the tuning process to users.
During developing a DNN model, users need to manage the tuning process, such as, creating an experiment, adjusting an experiment, kill or rerun a trial in an experiment, dumping experiment data for customized analysis. Also, users may create a new experiment for comparison, or concurrently for new model developing tasks. Thus, NNI provides the functionality of **experiment management**. Users can use :doc:`../reference/nnictl` to interact with experiments.
The relation of the components in NNI experiment is illustrated in the following figure. Hyper-parameter optimization (HPO), neural architecture search (NAS), and model compression are three key features in NNI that help users develop and tune their models. Training serivce provides the ability of parallel running trials on available computation resources. WebUI visualizes the tuning process. *nnictl* is for managing the experiments.
.. image:: ../../img/experiment_arch.png
:scale: 80 %
:align: center
Before reading the following content, you are recommended to go through the quick start first.
NNI supports running an experiment on `PAI-DSW <https://help.aliyun.com/document_detail/194831.html>`__ , submit trials to `PAI-DLC <https://help.aliyun.com/document_detail/165137.html>`__ called dlc mode.
NNI supports running an experiment on `PAI-DSW <https://help.aliyun.com/document_detail/194831.html>`__ , submit trials to `PAI-DLC <https://help.aliyun.com/document_detail/165137.html>`__ which is deep learning containers based on Alibaba ACK.
PAI-DSW server performs the role to submit a job while PAI-DLC is where the training job runs.
PAI-DSW server performs the role to submit a job while PAI-DLC is where the training job runs.
Setup environment
Prerequisite
-----------------
------------
Step 1. Install NNI, follow the install guide `here <../Tutorial/QuickStart.rst>`__.
Step 1. Install NNI, follow the install guide `here <../Tutorial/QuickStart.rst>`__.
...
@@ -24,8 +24,8 @@ Step 4. Open your PAI-DSW server command line, download and install PAI-DLC pyth
...
@@ -24,8 +24,8 @@ Step 4. Open your PAI-DSW server command line, download and install PAI-DLC pyth
pip install ./pai-dlc-20201203 # pai-dlc-20201203 refer to unzipped sdk file name, replace it accordingly.
pip install ./pai-dlc-20201203 # pai-dlc-20201203 refer to unzipped sdk file name, replace it accordingly.
Run an experiment
Usage
-----------------
-----
Use ``examples/trials/mnist-pytorch`` as an example. The NNI config YAML file's content is like:
Use ``examples/trials/mnist-pytorch`` as an example. The NNI config YAML file's content is like:
...
@@ -78,6 +78,6 @@ Run the following commands to start the example experiment:
...
@@ -78,6 +78,6 @@ Run the following commands to start the example experiment:
Replace ``${NNI_VERSION}`` with a released version name or branch name, e.g., ``v2.3``.
Replace ``${NNI_VERSION}`` with a released version name or branch name, e.g., ``v2.3``.
Monitor your job
Monitor your job
----------------
^^^^^^^^^^^^^^^^
To monitor your job on DLC, you need to visit `DLC <https://pai-dlc.console.aliyun.com/#/jobs>`__ to check job status.
To monitor your job on DLC, you need to visit `DLC <https://pai-dlc.console.aliyun.com/#/jobs>`__ to check job status.
NNI has supported many training services listed below. Users can go through each page to learning how to configure the corresponding training service. NNI has high extensibility by design, users can customize new training service for their special resource, platform or needs.
.. toctree::
:hidden:
Local <local>
Remote <remote>
OpenPAI <openpai>
Kubeflow <kubeflow>
AdaptDL <adaptdl>
FrameworkController <frameworkcontroller>
AML <aml>
PAI-DLC <paidlc>
Hybrid <hybrid>
Customize a Training Service <customize>
.. list-table::
:header-rows: 1
* - Training Service
- Description
* - Local
- The whole experiment runs on your dev machine (i.e., a single local machine)
* - Remote
- The trials are dispatched to your configured remote servers
* - OpenPAI
- Running trials on OpenPAI, a DNN model training platform based on Kubernetes
* - Kubeflow
- Running trials with Kubeflow, a DNN model training framework based on Kubernetes
* - AdaptDL
- Running trials on AdaptDL, an elastic DNN model training platform
* - FrameworkController
- Running trials with FrameworkController, a DNN model training framework on Kubernetes
* - AML
- Running trials on AML cloud service
* - PAI-DLC
- Running trials on PAI-DLC, which is deep learning containers based on Alibaba ACK
* - Hybrid
- Support jointly using multiple above training services
For `Kubeflow <../TrainingService/KubeflowMode.rst>`_, `FrameworkController <../TrainingService/FrameworkControllerMode.rst>`_, and `AdaptDL <../TrainingService/AdaptDLMode.rst>`_ training platforms, it is suggested to use `v1 config schema <../Tutorial/ExperimentConfig.rst>`_ for now.
For `Kubeflow <../TrainingService/KubeflowMode.rst>`_, `FrameworkController <../TrainingService/FrameworkControllerMode.rst>`_, and `AdaptDL <../TrainingService/AdaptDLMode.rst>`_ training platforms, it is suggested to use `v1 config schema <../Tutorial/ExperimentConfig.rst>`_ for now.
.. _reference-local-config-label:
LocalConfig
LocalConfig
-----------
-----------
Detailed usage can be found `here <../TrainingService/LocalMode.rst>`__.
Introduction of the corresponding local training service can be found :doc:`../experiment/local`.

{kind=link}