
Merge pull request #233 from microsoft/master
merge master
Showing
docs/en_US/pruners.rst
0 → 100644
docs/en_US/quantizers.rst
0 → 100644
{kind=link}
36.1 KB
{kind=link}

221 KB
{kind=link}
125 KB
{kind=link}
16.1 KB
{kind=link}
54.4 KB
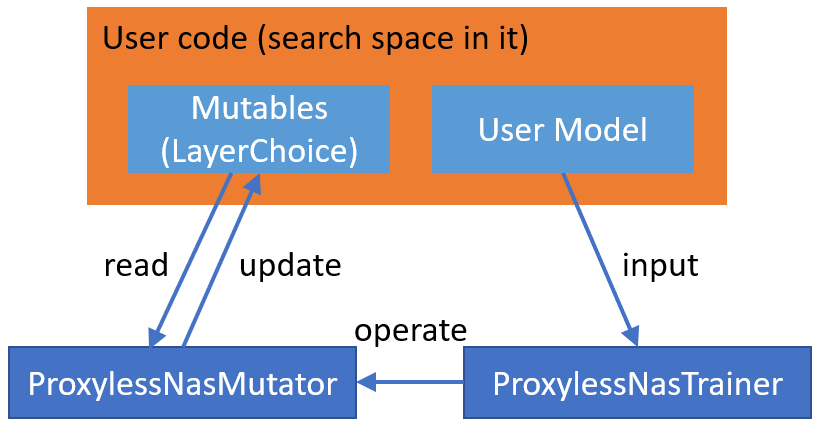
docs/img/proxylessnas.png
0 → 100644
{kind=link}
26.3 KB
docs/zh_CN/NAS/Advanced.md
0 → 100644
docs/zh_CN/NAS/NasGuide.md
0 → 100644