这只是 NNI 支持的一小部分库。 如果对 NNI 感兴趣,可参考[教程](TrialExample/Trials.md)来继续学习。
除了这些案例,也欢迎更多的用户将 NNI 应用到自己的工作中,如果有任何疑问,请参考[实现 Trial](TrialExample/Trials.md)。 如果想成为 NNI 的贡献者,无论是分享示例,还是实现 Tuner 或其它内容,我们都非常期待您的参与。更多信息请[参考这里](Tutorial/Contributing.md)。
* 可选。在使用 pai 模式时,为私有 Docker 仓库设置认证文件,[见参考文档](https://github.com/microsoft/pai/blob/2ea69b45faa018662bc164ed7733f6fdbb4c42b3/docs/faq.md#q-how-to-use-private-docker-registry-job-image-when-submitting-an-openpai-job)。提供 authFile 的本地路径即可, NNI 会上传此文件。
[EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)
Provided here are: Search space and tuners for finding the best tuple (alpha, beta, gamma) for EfficientNet-B1 with grid search, as discussed in Section 3.3 in [paper](https://arxiv.org/abs/1905.11946).
## Instructions
1. Set your working directory here in this directory.
2. Run `git clone https://github.com/ultmaster/EfficientNet-PyTorch` to clone this modified version of [EfficientNet-PyTorch](https://github.com/lukemelas/EfficientNet-PyTorch). The modifications were done to adhere to the original [Tensorflow version](https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet) as close as possible (including EMA, label smoothing and etc.); also added are the part which gets parameters from tuner and reports intermediate/final results. Clone it into `EfficientNet-PyTorch`; the files like `main.py`, `train_imagenet.sh` will appear inside, as specified in the configuration files.
3. Run `nnictl create --config config_net.yml` to find the best EfficientNet-B1. Adjust the training service (PAI/local/remote), batch size in the config files according to the environment.
For training on ImageNet, read `EfficientNet-PyTorch/train_imagenet.sh`. Download ImageNet beforehand and extract it adhering to [PyTorch format](https://pytorch.org/docs/stable/torchvision/datasets.html#imagenet) and then replace `/mnt/data/imagenet` in with the location of the ImageNet storage. This file should also be a good example to follow for mounting ImageNet into the container on OpenPAI.
## Results
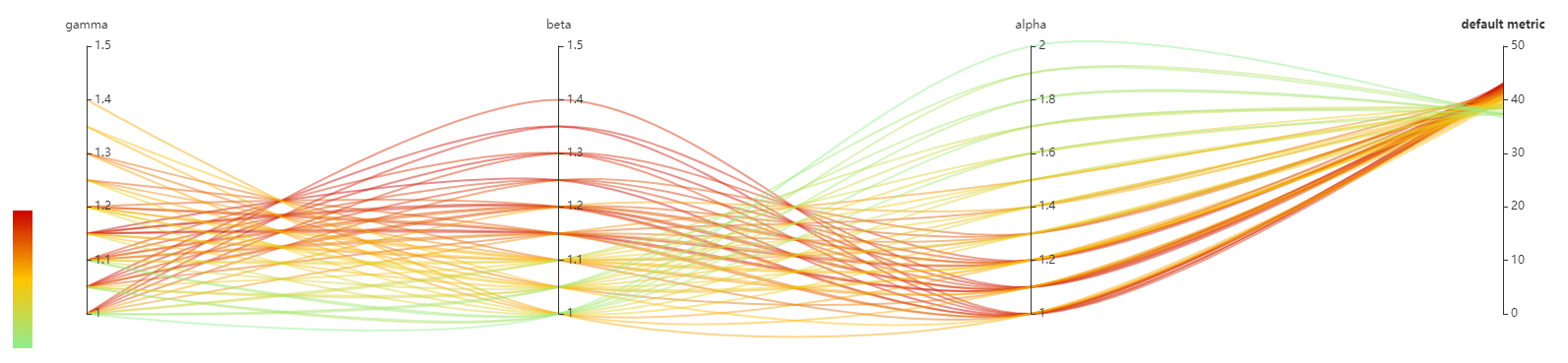
The follow image is a screenshot, demonstrating the relationship between acc@1 and alpha, beta, gamma.

{kind=link}