@@ -26,6 +26,7 @@ We further elaborate on the two methods, pruning and quantization, in the follow
...
@@ -26,6 +26,7 @@ We further elaborate on the two methods, pruning and quantization, in the follow
.. image:: ../../img/prune_quant.jpg
.. image:: ../../img/prune_quant.jpg
:target: ../../img/prune_quant.jpg
:target: ../../img/prune_quant.jpg
:scale: 40%
:scale: 40%
:align: center
:alt:
:alt:
NNI provides an easy-to-use toolkit to help users design and use model pruning and quantization algorithms.
NNI provides an easy-to-use toolkit to help users design and use model pruning and quantization algorithms.
...
@@ -46,8 +47,9 @@ There are several core features supported by NNI model compression:
...
@@ -46,8 +47,9 @@ There are several core features supported by NNI model compression:
.. image:: ../../img/compression_pipeline.png
.. image:: ../../img/compression_pipeline.png
:target: ../../img/compression_pipeline.png
:target: ../../img/compression_pipeline.png
:alt:
:alt:
:scale: 20%
:align: center
:scale: 30%
The overall compression pipeline in NNI is shown above. For compressing a pretrained model, pruning and quantization can be used alone or in combination.
The overall compression pipeline in NNI is shown above. For compressing a pretrained model, pruning and quantization can be used alone or in combination.
If users want to apply both, a sequential mode is recommended as common practise.
If users want to apply both, a sequential mode is recommended as common practise.
...
@@ -58,74 +60,6 @@ If users want to apply both, a sequential mode is recommended as common practise
...
@@ -58,74 +60,6 @@ If users want to apply both, a sequential mode is recommended as common practise
The interface and APIs are unified for both PyTorch and TensorFlow. Currently only PyTorch version has been supported, and TensorFlow version will be supported in future.
The interface and APIs are unified for both PyTorch and TensorFlow. Currently only PyTorch version has been supported, and TensorFlow version will be supported in future.
.. rubric:: Supported Pruning Algorithms
Pruning algorithms compress the original network by removing redundant weights or channels of layers, which can reduce model complexity and mitigate the over-fitting issue.
.. list-table::
:header-rows: 1
:widths: auto
* - Name
- Brief Introduction of Algorithm
* - :ref:`level-pruner`
- Pruning the specified ratio on each weight element based on absolute value of weight element
* - :ref:`l1-norm-pruner`
- Pruning output channels with the smallest L1 norm of weights (Pruning Filters for Efficient Convnets) `Reference Paper <https://arxiv.org/abs/1608.08710>`__
* - :ref:`l2-norm-pruner`
- Pruning output channels with the smallest L2 norm of weights
* - :ref:`fpgm-pruner`
- Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration `Reference Paper <https://arxiv.org/abs/1811.00250>`__
* - :ref:`slim-pruner`
- Pruning output channels by pruning scaling factors in BN layers(Learning Efficient Convolutional Networks through Network Slimming) `Reference Paper <https://arxiv.org/abs/1708.06519>`__
* - :ref:`activation-apoz-rank-pruner`
- Pruning output channels based on the metric APoZ (average percentage of zeros) which measures the percentage of zeros in activations of (convolutional) layers. `Reference Paper <https://arxiv.org/abs/1607.03250>`__
* - :ref:`activation-mean-rank-pruner`
- Pruning output channels based on the metric that calculates the smallest mean value of output activations
* - :ref:`taylor-fo-weight-pruner`
- Pruning filters based on the first order taylor expansion on weights(Importance Estimation for Neural Network Pruning) `Reference Paper <http://jankautz.com/publications/Importance4NNPruning_CVPR19.pdf>`__
* - :ref:`admm-pruner`
- Pruning based on ADMM optimization technique `Reference Paper <https://arxiv.org/abs/1804.03294>`__
* - :ref:`linear-pruner`
- Sparsity ratio increases linearly during each pruning rounds, in each round, using a basic pruner to prune the model.
* - :ref:`agp-pruner`
- Automated gradual pruning (To prune, or not to prune: exploring the efficacy of pruning for model compression) `Reference Paper <https://arxiv.org/abs/1710.01878>`__
* - :ref:`lottery-ticket-pruner`
- The pruning process used by "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks". It prunes a model iteratively. `Reference Paper <https://arxiv.org/abs/1803.03635>`__
* - :ref:`simulated-annealing-pruner`
- Automatic pruning with a guided heuristic search method, Simulated Annealing algorithm `Reference Paper <https://arxiv.org/abs/1907.03141>`__
* - :ref:`auto-compress-pruner`
- Automatic pruning by iteratively call SimulatedAnnealing Pruner and ADMM Pruner `Reference Paper <https://arxiv.org/abs/1907.03141>`__
* - :ref:`amc-pruner`
- AMC: AutoML for Model Compression and Acceleration on Mobile Devices `Reference Paper <https://arxiv.org/abs/1802.03494>`__
* - :ref:`movement-pruner`
- Movement Pruning: Adaptive Sparsity by Fine-Tuning `Reference Paper <https://arxiv.org/abs/2005.07683>`__
.. rubric:: Supported Quantization Algorithms
Quantization algorithms compress the original network by reducing the number of bits required to represent weights or activations, which can reduce the computations and the inference time.
.. list-table::
:header-rows: 1
:widths: auto
* - Name
- Brief Introduction of Algorithm
* - :ref:`naive-quantizer`
- Quantize weights to default 8 bits
* - :ref:`qat-quantizer`
- Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. `Reference Paper <http://openaccess.thecvf.com/content_cvpr_2018/papers/Jacob_Quantization_and_Training_CVPR_2018_paper.pdf>`__
* - :ref:`dorefa-quantizer`
- DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. `Reference Paper <https://arxiv.org/abs/1606.06160>`__
* - :ref:`bnn-quantizer`
- Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1. `Reference Paper <https://arxiv.org/abs/1602.02830>`__
* - :ref:`lsq-quantizer`
- Learned step size quantization. `Reference Paper <https://arxiv.org/pdf/1902.08153.pdf>`__
* - :ref:`observer-quantizer`
- Post training quantizaiton. Collect quantization information during calibration with observers.
.. rubric:: Model Speedup
.. rubric:: Model Speedup
The final goal of model compression is to reduce inference latency and model size.
The final goal of model compression is to reduce inference latency and model size.
...
@@ -137,7 +71,8 @@ The following figure shows how NNI prunes and speeds up your models.
...
@@ -137,7 +71,8 @@ The following figure shows how NNI prunes and speeds up your models.
.. image:: ../../img/nni_prune_process.png
.. image:: ../../img/nni_prune_process.png
:target: ../../img/nni_prune_process.png
:target: ../../img/nni_prune_process.png
:scale: 20%
:scale: 30%
:align: center
:alt:
:alt:
The detailed tutorial of Speedup Model with Mask can be found :doc:`here <../tutorials/cp_pruning_speedup>`.
The detailed tutorial of Speedup Model with Mask can be found :doc:`here <../tutorials/cp_pruning_speedup>`.
Pruning algorithms compress the original network by removing redundant weights or channels of layers, which can reduce model complexity and mitigate the over-fitting issue.
- Pruning the specified ratio on each weight element based on absolute value of weight element
.. _l1-norm-pruner:
* - :ref:`l1-norm-pruner`
- Pruning output channels with the smallest L1 norm of weights (Pruning Filters for Efficient Convnets) `Reference Paper <https://arxiv.org/abs/1608.08710>`__
L1 Norm Pruner
* - :ref:`l2-norm-pruner`
^^^^^^^^^^^^^^
- Pruning output channels with the smallest L2 norm of weights
- Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration `Reference Paper <https://arxiv.org/abs/1811.00250>`__
* - :ref:`slim-pruner`
.. _l2-norm-pruner:
- Pruning output channels by pruning scaling factors in BN layers(Learning Efficient Convolutional Networks through Network Slimming) `Reference Paper <https://arxiv.org/abs/1708.06519>`__
* - :ref:`activation-apoz-rank-pruner`
L2 Norm Pruner
- Pruning output channels based on the metric APoZ (average percentage of zeros) which measures the percentage of zeros in activations of (convolutional) layers. `Reference Paper <https://arxiv.org/abs/1607.03250>`__
^^^^^^^^^^^^^^
* - :ref:`activation-mean-rank-pruner`
- Pruning output channels based on the metric that calculates the smallest mean value of output activations
- Pruning filters based on the first order taylor expansion on weights(Importance Estimation for Neural Network Pruning) `Reference Paper <http://jankautz.com/publications/Importance4NNPruning_CVPR19.pdf>`__
.. _fpgm-pruner:
* - :ref:`admm-pruner`
- Pruning based on ADMM optimization technique `Reference Paper <https://arxiv.org/abs/1804.03294>`__
FPGM Pruner
* - :ref:`linear-pruner`
^^^^^^^^^^^
- Sparsity ratio increases linearly during each pruning rounds, in each round, using a basic pruner to prune the model.
- Automated gradual pruning (To prune, or not to prune: exploring the efficacy of pruning for model compression) `Reference Paper <https://arxiv.org/abs/1710.01878>`__
* - :ref:`lottery-ticket-pruner`
.. _slim-pruner:
- The pruning process used by "The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks". It prunes a model iteratively. `Reference Paper <https://arxiv.org/abs/1803.03635>`__
* - :ref:`simulated-annealing-pruner`
Slim Pruner
- Automatic pruning with a guided heuristic search method, Simulated Annealing algorithm `Reference Paper <https://arxiv.org/abs/1907.03141>`__
^^^^^^^^^^^
* - :ref:`auto-compress-pruner`
- Automatic pruning by iteratively call SimulatedAnnealing Pruner and ADMM Pruner `Reference Paper <https://arxiv.org/abs/1907.03141>`__
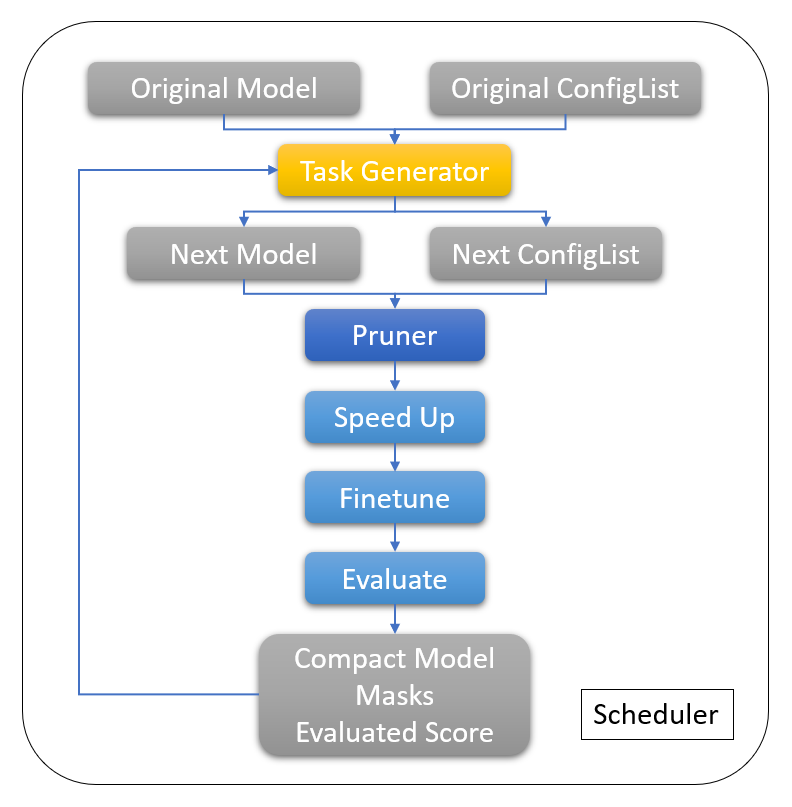
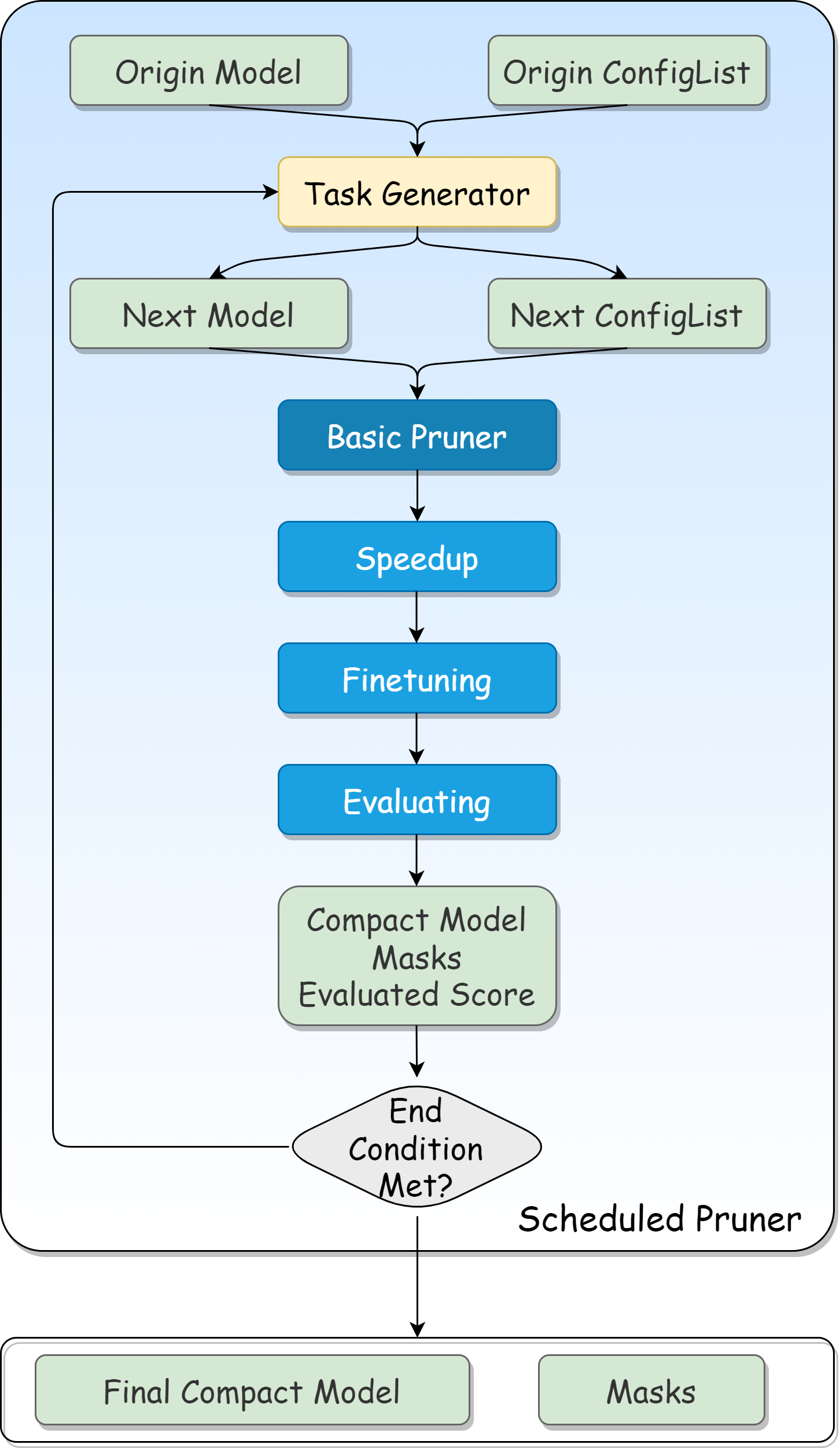
The full script can be found :githublink:`here <examples/model_compress/pruning/v2/scheduler_torch.py>`.
The full script can be found :githublink:`here <examples/model_compress/pruning/scheduler_torch.py>`.
In this example, we use dependency-aware mode L1 Norm Pruner as a basic pruner during each iteration.
In this example, we use dependency-aware mode L1 Norm Pruner as a basic pruner during each iteration.
Note we do not need to pass ``model`` and ``config_list`` to the pruner, because in each iteration the ``model`` and ``config_list`` used by the pruner are received from the task generator.
Note we do not need to pass ``model`` and ``config_list`` to the pruner, because in each iteration the ``model`` and ``config_list`` used by the pruner are received from the task generator.
...
@@ -56,7 +56,8 @@ The pruning result will return to the ``TaskGenerator`` at the end of each itera
...
@@ -56,7 +56,8 @@ The pruning result will return to the ``TaskGenerator`` at the end of each itera
The information included in the ``Task`` and ``TaskResult`` can be found :githublink:`here <nni/algorithms/compression/v2/pytorch/base/scheduler.py>`.
The information included in the ``Task`` and ``TaskResult`` can be found :githublink:`here <nni/algorithms/compression/v2/pytorch/base/scheduler.py>`.
A clearer iterative pruning flow chart can be found `here <v2_pruning.rst>`__.
A clearer iterative pruning flow chart can be found :doc:`here <pruning>`.
If you want to implement your own task generator, please following the ``TaskGenerator`` :githublink:`interface <nni/algorithms/compression/v2/pytorch/pruning/tools/base.py>`.
If you want to implement your own task generator, please following the ``TaskGenerator`` :githublink:`interface <nni/algorithms/compression/v2/pytorch/pruning/tools/base.py>`.
Two main functions should be implemented, ``init_pending_tasks(self) -> List[Task]`` and ``generate_tasks(self, task_result: TaskResult) -> List[Task]``.
Two main functions should be implemented, ``init_pending_tasks(self) -> List[Task]`` and ``generate_tasks(self, task_result: TaskResult) -> List[Task]``.
Quantization algorithms compress the original network by reducing the number of bits required to represent weights or activations, which can reduce the computations and the inference time.
- Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. `Reference Paper <http://openaccess.thecvf.com/content_cvpr_2018/papers/Jacob_Quantization_and_Training_CVPR_2018_paper.pdf>`__
- DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. `Reference Paper <https://arxiv.org/abs/1606.06160>`__
.. _dorefa-quantizer:
* - :ref:`bnn-quantizer`
- Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1. `Reference Paper <https://arxiv.org/abs/1602.02830>`__
DoReFa Quantizer
* - :ref:`lsq-quantizer`
^^^^^^^^^^^^^^^^
- Learned step size quantization. `Reference Paper <https://arxiv.org/pdf/1902.08153.pdf>`__
Note that: for fine-tuning a pruned model, run :githublink:`basic_pruners_torch.py <examples/model_compress/pruning/basic_pruners_torch.py>` first to get the mask file, then pass the mask path as argument to the script.
Note that: for fine-tuning a pruned model, run :githublink:`basic_pruners_torch.py <examples/model_compress/pruning/legacy/basic_pruners_torch.py>` first to get the mask file, then pass the mask path as argument to the script.
This avoids potential issues of counting them of masked models.
This avoids potential issues of counting them of masked models.
*
*
The experiment code can be found :githublink:`here <examples/model_compress/pruning/auto_pruners_torch.py>`.
The experiment code can be found :githublink:`here <examples/model_compress/pruning/legacy/auto_pruners_torch.py>`.
Experiment Result Rendering
Experiment Result Rendering
^^^^^^^^^^^^^^^^^^^^^^^^^^^
^^^^^^^^^^^^^^^^^^^^^^^^^^^
*
*
If you follow the practice in the :githublink:`example <examples/model_compress/pruning/auto_pruners_torch.py>`\ , for every single pruning experiment, the experiment result will be saved in JSON format as follows:
If you follow the practice in the :githublink:`example <examples/model_compress/pruning/legacy/auto_pruners_torch.py>`\ , for every single pruning experiment, the experiment result will be saved in JSON format as follows:
.. code-block:: json
.. code-block:: json
...
@@ -114,8 +114,8 @@ Experiment Result Rendering
...
@@ -114,8 +114,8 @@ Experiment Result Rendering
}
}
*
*
The experiment results are saved :githublink:`here <examples/model_compress/pruning/comparison_of_pruners>`.
The experiment results are saved :githublink:`here <examples/model_compress/pruning/legacy/comparison_of_pruners>`.
You can refer to :githublink:`analyze <examples/model_compress/pruning/comparison_of_pruners/analyze.py>` to plot new performance comparison figures.
You can refer to :githublink:`analyze <examples/model_compress/pruning/legacy/comparison_of_pruners/analyze.py>` to plot new performance comparison figures.
"from nni.algorithms.compression.v2.pytorch.pruning import L1NormPruner\npruner = L1NormPruner(model, config_list)\n\n# show the wrapped model structure, `PrunerModuleWrapper` have wrapped the layers that configured in the config_list.\nprint(model)"
"from nni.compression.pytorch.pruning import L1NormPruner\npruner = L1NormPruner(model, config_list)\n\n# show the wrapped model structure, `PrunerModuleWrapper` have wrapped the layers that configured in the config_list.\nprint(model)"

{kind=link}
{kind=link}