.. note:: :doc:`Example usage of NAS benchmarks </tutorials/nasbench_as_dataset>`.
.. note:: :doc:`Example usage of NAS benchmarks </tutorials/nasbench_as_dataset>`.
Introduction
------------
To improve the reproducibility of NAS algorithms as well as reducing computing resource requirements, researchers proposed a series of NAS benchmarks such as `NAS-Bench-101 <https://arxiv.org/abs/1902.09635>`__, `NAS-Bench-201 <https://arxiv.org/abs/2001.00326>`__, `NDS <https://arxiv.org/abs/1905.13214>`__, etc. NNI provides a query interface for users to acquire these benchmarks. Within just a few lines of code, researcher are able to evaluate their NAS algorithms easily and fairly by utilizing these benchmarks.
To improve the reproducibility of NAS algorithms as well as reducing computing resource requirements, researchers proposed a series of NAS benchmarks such as `NAS-Bench-101 <https://arxiv.org/abs/1902.09635>`__, `NAS-Bench-201 <https://arxiv.org/abs/2001.00326>`__, `NDS <https://arxiv.org/abs/1905.13214>`__, etc. NNI provides a query interface for users to acquire these benchmarks. Within just a few lines of code, researcher are able to evaluate their NAS algorithms easily and fairly by utilizing these benchmarks.
Prerequisites
Prerequisites
-------------
-------------
* Please prepare a folder to household all the benchmark databases. By default, it can be found at ``${HOME}/.cache/nni/nasbenchmark``. Or you can place it anywhere you like, and specify it in ``NASBENCHMARK_DIR`` via ``export NASBENCHMARK_DIR=/path/to/your/nasbenchmark`` before importing NNI.
* Please prepare a folder to household all the benchmark databases. By default, it can be found at ``${HOME}/.cache/nni/nasbenchmark``. Or you can place it anywhere you like, and specify it in ``NASBENCHMARK_DIR`` via ``export NASBENCHMARK_DIR=/path/to/your/nasbenchmark`` before importing NNI.
* Please install ``peewee`` via ``pip3 install peewee``, which NNI uses to connect to database.
* Please install ``peewee`` via ``pip3 install peewee``, which NNI uses to connect to database.
...
@@ -51,7 +47,7 @@ Please make sure there is at least 10GB free disk space and note that the conver
...
@@ -51,7 +47,7 @@ Please make sure there is at least 10GB free disk space and note that the conver
Example Usages
Example Usages
--------------
--------------
Please refer to `examples usages of Benchmarks API <../BenchmarksExample.rst>`__.
Please refer to :doc:`examples usages of Benchmarks API </tutorials/nasbench_as_dataset>`.
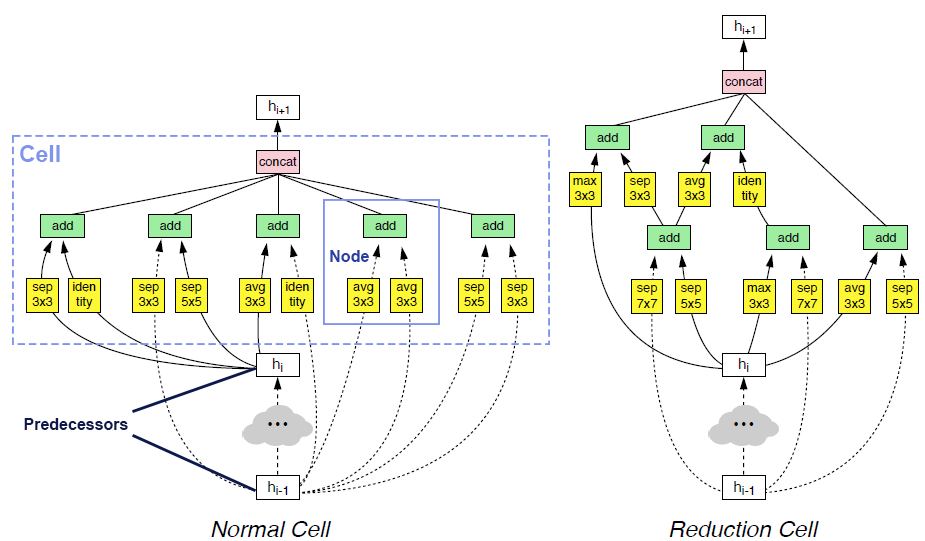
Notably, NAS-Bench-101 eliminates invalid cells (e.g., there is no path from input to output, or there is redundant computation). Furthermore, isomorphic cells are de-duplicated, i.e., all the remaining cells are computationally unique.
Notably, NAS-Bench-101 eliminates invalid cells (e.g., there is no path from input to output, or there is redundant computation). Furthermore, isomorphic cells are de-duplicated, i.e., all the remaining cells are computationally unique.
API Documentation
See :doc:`example usages </tutorials/nasbench_as_dataset>` and :ref:`API references <nas-bench-101-reference>`.
^^^^^^^^^^^^^^^^^
.. automodule:: nni.nas.benchmarks.nasbench101
:members:
:imported-members:
NAS-Bench-201
NAS-Bench-201
-------------
-------------
...
@@ -79,12 +70,7 @@ NAS-Bench-201
...
@@ -79,12 +70,7 @@ NAS-Bench-201
NAS-Bench-201 is a cell-wise search space that views nodes as tensors and edges as operators. The search space contains all possible densely-connected DAGs with 4 nodes, resulting in 15,625 candidates in total. Each operator (i.e., edge) is selected from a pre-defined operator set (\ ``NONE``, ``SKIP_CONNECT``, ``CONV_1X1``, ``CONV_3X3`` and ``AVG_POOL_3X3``\ ). Training appraoches vary in the dataset used (CIFAR-10, CIFAR-100, ImageNet) and number of epochs scheduled (12 and 200). Each combination of architecture and training approach is repeated 1 - 3 times with different random seeds.
NAS-Bench-201 is a cell-wise search space that views nodes as tensors and edges as operators. The search space contains all possible densely-connected DAGs with 4 nodes, resulting in 15,625 candidates in total. Each operator (i.e., edge) is selected from a pre-defined operator set (\ ``NONE``, ``SKIP_CONNECT``, ``CONV_1X1``, ``CONV_3X3`` and ``AVG_POOL_3X3``\ ). Training appraoches vary in the dataset used (CIFAR-10, CIFAR-100, ImageNet) and number of epochs scheduled (12 and 200). Each combination of architecture and training approach is repeated 1 - 3 times with different random seeds.
API Documentation
See :doc:`example usages </tutorials/nasbench_as_dataset>` and :ref:`API references <nas-bench-201-reference>`.
^^^^^^^^^^^^^^^^^
.. automodule:: nni.nas.benchmarks.nasbench201
:members:
:imported-members:
NDS
NDS
---
---
...
@@ -96,17 +82,9 @@ NDS
...
@@ -96,17 +82,9 @@ NDS
Instead of storing results obtained with different configurations in separate files, we dump them into one single database to enable comparison in multiple dimensions. Specifically, we use ``model_family`` to distinguish model types, ``model_spec`` for all hyper-parameters needed to build this model, ``cell_spec`` for detailed information on operators and connections if it is a NAS cell, ``generator`` to denote the sampling policy through which this configuration is generated. Refer to API documentation for details.
Instead of storing results obtained with different configurations in separate files, we dump them into one single database to enable comparison in multiple dimensions. Specifically, we use ``model_family`` to distinguish model types, ``model_spec`` for all hyper-parameters needed to build this model, ``cell_spec`` for detailed information on operators and connections if it is a NAS cell, ``generator`` to denote the sampling policy through which this configuration is generated. Refer to API documentation for details.
Available Operators
-------------------
Here is a list of available operators used in NDS.
Here is a list of available operators used in NDS.
.. automodule:: nni.nas.benchmarks.nds.constants
.. automodule:: nni.nas.benchmarks.nds.constants
:noindex:
:noindex:
API Documentation
See :doc:`example usages </tutorials/nasbench_as_dataset>` and :ref:`API references <nds-reference>`.
NNI provides powerful APIs for users to easily express model space (or search space).
NNI provides powerful (and multi-level) APIs for users to easily express model space (or search space).
Firstly, users can use high-level APIs (e.g., ValueChoice, LayerChoice) which are building blocks / skeletons of building blocks to construct their search space.
For advanced cases, NNI also provides interface to customize new mutators for expressing more complicated model spaces.
* *Mutation Primitives*: high-level APIs (e.g., ValueChoice, LayerChoice) that are utilities to build blocks in search space. In most cases, mutation pritimives should be straightforward yet expressive enough. **We strongly recommend users to try them first,** and report issues if those APIs are not satisfying.
* *Hyper-module Library*: plug-and-play modules that are proved useful. They are usually well studied in research, and comes with pre-searched results. (For example, the optimal activation function in `AutoActivation <https://arxiv.org/abs/1710.05941>`__ is reported to be `Swish <https://pytorch.org/docs/stable/generated/torch.nn.SiLU.html>`__).
.. tip:: In most cases, this should be simple but expressive enough. We strongly recommend users to try them first, and report issues if those APIs are not satisfying.
* *Mutator*: for advanced users only. NNI provides interface to customize new mutators for expressing more complicated model spaces.
.. _mutation-primitives:
The following table summarizes all the APIs we have provided for constructing search space.
Mutation Primitives
.. list-table::
-------------------
:header-rows: 1
:widths: auto
To make users easily express a model space within their PyTorch/TensorFlow model, NNI provides some inline mutation APIs as shown below.
* - Name
.. note:: We can actively adding more mutation primitives. If you have any suggestions, feel free to `ask here <https://github.com/microsoft/nni/issues>`__.
Hyper-module is a (PyTorch) module which contains many architecture/hyperparameter candidates for this module. By using hypermodule in user defined model, NNI will help users automatically find the best architecture/hyperparameter of the hyper-modules for this model. This follows the design philosophy of Retiarii that users write DNN model as a space.
We are planning to support some of the hyper-modules commonly used in the community, such as AutoDropout, AutoActivation. These are considered complementary to :ref:`mutation-primitives`, as they are often more concrete, specific, and tailored for particular needs.
Besides the inline mutation APIs demonstrated :ref:`above <mutation-primitives>`, NNI provides a more general approach to express a model space, i.e., *Mutator*, to cover more complex model spaces. Those inline mutation APIs are also implemented with mutator in the underlying system, which can be seen as a special case of model mutation. Please read :doc:`./mutator` for details.
@@ -48,11 +48,14 @@ Evaluators with PyTorch-Lightning
...
@@ -48,11 +48,14 @@ Evaluators with PyTorch-Lightning
UseBuilt-inEvaluators
UseBuilt-inEvaluators
^^^^^^^^^^^^^^^^^^^^^^^
^^^^^^^^^^^^^^^^^^^^^^^
NNIprovidessomecommonlyusedmodelevaluatorsforusers' convenience. These evaluators are built upon the awesome library PyTorch-Lightning.
NNIprovidessomecommonlyusedmodelevaluatorsforusers' convenience. These evaluators are built upon the awesome library PyTorch-Lightning. Read the :doc:`reference </reference/nas/evaluator>` for their detailed usages.
We recommend to read the `serialization tutorial <./Serialization.rst>`__ before using these evaluators. A few notes to summarize the tutorial:
* :class:`nni.retiarii.evaluator.pytorch.Classification`: for classification tasks.
* :class:`nni.retiarii.evaluator.pytorch.Regression`: for regression tasks.
1. :class:`nni.retarii.evaluator.pytorch.DataLoader`` should be used in place of ``torch.utils.data.DataLoader``.
We recommend to read the :doc:`serialization tutorial <serialization>` before using these evaluators. A few notes to summarize the tutorial:
1. :class:`nni.retiarii.evaluator.pytorch.DataLoader` should be used in place of ``torch.utils.data.DataLoader``.
2. The datasets used in data-loader should be decorated with :meth:`nni.trace` recursively.
2. The datasets used in data-loader should be decorated with :meth:`nni.trace` recursively.
For example,
For example,
...
@@ -141,39 +144,3 @@ Then, users need to wrap everything (including LightningModule, trainer and data
...
@@ -141,39 +144,3 @@ Then, users need to wrap everything (including LightningModule, trainer and data
Execution engine is for running Retiarii Experiment. NNI supports three execution engines, users can choose a specific engine according to the type of their model mutation definition and their requirements for cross-model optimizations.
Execution engine is for running Retiarii Experiment. NNI supports three execution engines, users can choose a specific engine according to the type of their model mutation definition and their requirements for cross-model optimizations.
* **Pure-python execution engine** is the default engine, it supports the model space expressed by `inline mutation API <./MutationPrimitives.rst>`__.
* **Pure-python execution engine** is the default engine, it supports the model space expressed by :doc:`mutation primitives <construct_space>`.
* **Graph-based execution engine** supports the use of `inline mutation APIs <./MutationPrimitives.rst>`__ and model spaces represented by `mutators <./Mutators.rst>`__. It requires the user's model to be parsed by `TorchScript <https://pytorch.org/docs/stable/jit.html>`__.
* **Graph-based execution engine** supports the use of :doc:`mutation primitives <construct_space>` and model spaces represented by :doc:`mutators <mutator>`. It requires the user's model to be parsed by `TorchScript <https://pytorch.org/docs/stable/jit.html>`__.
* **CGO execution engine** has the same requirements and capabilities as the **Graph-based execution engine**. But further enables cross-model optimizations, which makes model space exploration faster.
* **CGO execution engine** has the same requirements and capabilities as the **Graph-based execution engine**. But further enables cross-model optimizations, which makes model space exploration faster.
...
@@ -14,9 +14,7 @@ Pure-python Execution Engine
...
@@ -14,9 +14,7 @@ Pure-python Execution Engine
Pure-python Execution Engine is the default engine, we recommend users to keep using this execution engine, if they are new to NNI NAS. Pure-python execution engine plays magic within the scope of inline mutation APIs, while does not touch the rest of user model. Thus, it has minimal requirement on user model.
Pure-python Execution Engine is the default engine, we recommend users to keep using this execution engine, if they are new to NNI NAS. Pure-python execution engine plays magic within the scope of inline mutation APIs, while does not touch the rest of user model. Thus, it has minimal requirement on user model.
One steps are needed to use this engine now.
Rememeber to add :meth:`nni.retiarii.model_wrapper` decorator outside the whole PyTorch model before using this engine.
1. Add ``@nni.retiarii.model_wrapper`` decorator outside the whole PyTorch model.
.. note:: You should always use ``super().__init__()`` instead of ``super(MyNetwork, self).__init__()`` in the PyTorch model, because the latter one has issues with model wrapper.
.. note:: You should always use ``super().__init__()`` instead of ``super(MyNetwork, self).__init__()`` in the PyTorch model, because the latter one has issues with model wrapper.
...
@@ -25,11 +23,11 @@ Graph-based Execution Engine
...
@@ -25,11 +23,11 @@ Graph-based Execution Engine
For graph-based execution engine, it converts user-defined model to a graph representation (called graph IR) using `TorchScript <https://pytorch.org/docs/stable/jit.html>`__, each instantiated module in the model is converted to a subgraph. Then mutations are applied to the graph to generate new graphs. Each new graph is then converted back to PyTorch code and executed on the user specified training service.
For graph-based execution engine, it converts user-defined model to a graph representation (called graph IR) using `TorchScript <https://pytorch.org/docs/stable/jit.html>`__, each instantiated module in the model is converted to a subgraph. Then mutations are applied to the graph to generate new graphs. Each new graph is then converted back to PyTorch code and executed on the user specified training service.
Users may find ``@basic_unit`` helpful in some cases. ``@basic_unit`` here means the module will not be converted to a subgraph, instead, it is converted to a single graph node as a basic unit.
Users may find ``@basic_unit`` helpful in some cases. :meth:`nni.retiarii.basic_unit` here means the module will not be converted to a subgraph, instead, it is converted to a single graph node as a basic unit.
``@basic_unit`` is usually used in the following cases:
``@basic_unit`` is usually used in the following cases:
* When users want to tune initialization parameters of a module using ``ValueChoice``, then decorate the module with ``@basic_unit``. For example, ``self.conv = MyConv(kernel_size=nn.ValueChoice([1, 3, 5]))``, here ``MyConv`` should be decorated.
* When users want to tune initialization parameters of a module using :class:`nni.retiarii.nn.pytorch.ValueChoice`, then decorate the module with ``@basic_unit``. For example, ``self.conv = MyConv(kernel_size=nn.ValueChoice([1, 3, 5]))``, here ``MyConv`` should be decorated.
* When a module cannot be successfully parsed to a subgraph, decorate the module with ``@basic_unit``. The parse failure could be due to complex control flow. Currently Retiarii does not support adhoc loop, if there is adhoc loop in a module's forward, this class should be decorated as serializable module. For example, the following ``MyModule`` should be decorated.
* When a module cannot be successfully parsed to a subgraph, decorate the module with ``@basic_unit``. The parse failure could be due to complex control flow. Currently Retiarii does not support adhoc loop, if there is adhoc loop in a module's forward, this class should be decorated as serializable module. For example, the following ``MyModule`` should be decorated.
...
@@ -43,12 +41,12 @@ Users may find ``@basic_unit`` helpful in some cases. ``@basic_unit`` here means
...
@@ -43,12 +41,12 @@ Users may find ``@basic_unit`` helpful in some cases. ``@basic_unit`` here means
for i in range(10): # <- adhoc loop
for i in range(10): # <- adhoc loop
...
...
* Some inline mutation APIs require their handled module to be decorated with ``@basic_unit``. For example, user-defined module that is provided to ``LayerChoice`` as a candidate op should be decorated.
* Some inline mutation APIs require their handled module to be decorated with ``@basic_unit``. For example, user-defined module that is provided to :class:`nni.retiarii.nn.pytorch.LayerChoice` as a candidate op should be decorated.
Three steps are need to use graph-based execution engine.
Three steps are need to use graph-based execution engine.
1. Remove ``@nni.retiarii.model_wrapper`` if there is any in your model.
1. Remove ``@nni.retiarii.model_wrapper`` if there is any in your model.
2. Add ``config.execution_engine = 'base'`` to ``RetiariiExeConfig``. The default value of ``execution_engine`` is 'py', which means pure-python execution engine.
2. Add ``config.execution_engine = 'base'`` to :class:`nni.retiarii.experiment.pytorch.RetiariiExeConfig`. The default value of ``execution_engine`` is 'py', which means pure-python execution engine.
3. Add ``@basic_unit`` when necessary following the above guidelines.
3. Add ``@basic_unit`` when necessary following the above guidelines.
For exporting top models, graph-based execution engine supports exporting source code for top models by running ``exp.export_top_models(formatter='code')``.
For exporting top models, graph-based execution engine supports exporting source code for top models by running ``exp.export_top_models(formatter='code')``.
...
@@ -106,15 +104,3 @@ Advanced users can also implement their own trainers by inheriting ``MultiModelS
...
@@ -106,15 +104,3 @@ Advanced users can also implement their own trainers by inheriting ``MultiModelS
Sometimes, a mutated model cannot be executed (e.g., due to shape mismatch). When a trial running multiple models contains
Sometimes, a mutated model cannot be executed (e.g., due to shape mismatch). When a trial running multiple models contains
a bad model, CGO execution engine will re-run each model independently in separate trials without cross-model optimizations.
a bad model, CGO execution engine will re-run each model independently in separate trials without cross-model optimizations.
@@ -51,7 +51,7 @@ In ``exp_config``, ``dummy_input`` is required for tracing shape info.
...
@@ -51,7 +51,7 @@ In ``exp_config``, ``dummy_input`` is required for tracing shape info.
End-to-end ProxylessNAS with Latency Constraints
End-to-end ProxylessNAS with Latency Constraints
------------------------------------------------
------------------------------------------------
`ProxylessNAS <https://arxiv.org/pdf/1812.00332.pdf>`__ is a hardware-aware one-shot NAS algorithm. ProxylessNAS applies the expected latency of the model to build a differentiable metric and design efficient neural network architectures for hardware. The latency loss is added as a regularization term for architecture parameter optimization. In this example, nn-Meter provides a latency estimator to predict expected latency for the mixed operation on other types of mobile and edge hardware.
`ProxylessNAS <https://arxiv.org/abs/1812.00332>`__ is a hardware-aware one-shot NAS algorithm. ProxylessNAS applies the expected latency of the model to build a differentiable metric and design efficient neural network architectures for hardware. The latency loss is added as a regularization term for architecture parameter optimization. In this example, nn-Meter provides a latency estimator to predict expected latency for the mixed operation on other types of mobile and edge hardware.
To run the one-shot ProxylessNAS demo, first install nn-Meter by running:
To run the one-shot ProxylessNAS demo, first install nn-Meter by running:
@@ -15,138 +14,74 @@ Retiarii for Neural Architecture Search
...
@@ -15,138 +14,74 @@ Retiarii for Neural Architecture Search
.. note:: PyTorch is the **only supported framework on Retiarii**. Inquiries of NAS support on Tensorflow is in `this discussion <https://github.com/microsoft/nni/discussions/4605>`__. If you intend to run NAS with DL frameworks other than PyTorch and Tensorflow, please `open new issues <https://github.com/microsoft/nni/issues>`__ to let us know.
.. note:: PyTorch is the **only supported framework on Retiarii**. Inquiries of NAS support on Tensorflow is in `this discussion <https://github.com/microsoft/nni/discussions/4605>`__. If you intend to run NAS with DL frameworks other than PyTorch and Tensorflow, please `open new issues <https://github.com/microsoft/nni/issues>`__ to let us know.
.. Using rubric to prevent the section heading to be include into toc
Basics
------
.. rubric:: Motivation
Automatic neural architecture search is playing an increasingly important role in finding better models. Recent research has proven the feasibility of automatic NAS and has led to models that beat many manually designed and tuned models. Representative works include `NASNet <https://arxiv.org/abs/1707.07012>`__, `ENAS <https://arxiv.org/abs/1802.03268>`__, `DARTS <https://arxiv.org/abs/1806.09055>`__, `Network Morphism <https://arxiv.org/abs/1806.10282>`__, and `Evolution <https://arxiv.org/abs/1703.01041>`__. In addition, new innovations continue to emerge.
Automatic neural architecture search is playing an increasingly important role in finding better models. Recent research has proven the feasibility of automatic NAS and has led to models that beat many manually designed and tuned models. Representative works include `NASNet <https://arxiv.org/abs/1707.07012>`__, `ENAS <https://arxiv.org/abs/1802.03268>`__, `DARTS <https://arxiv.org/abs/1806.09055>`__, `Network Morphism <https://arxiv.org/abs/1806.10282>`__, and `Evolution <https://arxiv.org/abs/1703.01041>`__. In addition, new innovations continue to emerge.
However, it is pretty hard to use existing NAS work to help develop common DNN models. Therefore, we designed `Retiarii <https://www.usenix.org/system/files/osdi20-zhang_quanlu.pdf>`__, a novel NAS/HPO framework, and implemented it in NNI. It helps users easily construct a model space (or search space, tuning space), and utilize existing NAS algorithms. The framework also facilitates NAS innovation and is used to design new NAS algorithms.
High-level speaking, aiming to solve any particular task with neural architecture search typically requires: search space design, search strategy selection, and performance evaluation. The three components work together with the following loop (from the famous `NAS survey <https://arxiv.org/abs/1808.05377>`__):
In summary, we highlight the following features for Retiarii:
* Simple APIs are provided for defining model search space within a deep learning model.
In this figure:
* SOTA NAS algorithms are built-in to be used for exploring model search space.
* System-level optimizations are implemented for speeding up the exploration.
.. rubric:: Overview
* *Model search space* means a set of models from which the best model is explored/searched. Sometimes we use *search space* or *model space* in short.
* *Exploration strategy* is the algorithm that is used to explore a model search space. Sometimes we also call it *search strategy*.
* *Model evaluator* is responsible for training a model and evaluating its performance.
High-level speaking, aiming to solve any particular task with neural architecture search typically requires: search space design, search strategy selection, and performance evaluation. The three components work together with the following loop (the figure is from the famous `NAS survey <https://arxiv.org/abs/1808.05377>`__):
The process is similar to :doc:`Hyperparameter Optimization </hpo/index>`, except that the target is the best architecture rather than hyperparameter. Concretely, an exploration strategy selects an architecture from a predefined search space. The architecture is passed to a performance evaluation to get a score, which represents how well this architecture performs on a particular task. This process is repeated until the search process is able to find the best architecture.
The current NAS framework in NNI is powered by the research of `Retiarii: A Deep Learning Exploratory-Training Framework <https://www.usenix.org/system/files/osdi20-zhang_quanlu.pdf>`__, where we highlight the following features:
* :doc:`Simple APIs to construct search space easily <construct_space>`
* :doc:`SOTA NAS algorithms to explore search space <exploration_strategy>`
* :doc:`Experiment backend support to scale up experiments on large-scale AI platforms </experiment/overview>`
Why NAS with NNI
----------------
We list out the three perspectives where NAS can be particularly challegning without NNI. NNI provides solutions to relieve users' engineering effort when they want to try NAS techniques in their own scenario.
Search Space Design
^^^^^^^^^^^^^^^^^^^
The search space defines which architectures can be represented in principle. Incorporating prior knowledge about typical properties of architectures well-suited for a task can reduce the size of the search space and simplify the search. However, this also introduces a human bias, which may prevent finding novel architectural building blocks that go beyond the current human knowledge. Search space design can be very challenging for beginners, who might not possess the experience to balance the richness and simplicity.
In NNI, we provide a wide range of APIs to build the search space. There are :doc:`high-level APIs <construct_space>`, that enables incorporating human knowledge about what makes a good architecture or search space. There are also :doc:`low-level APIs <mutator>`, that is a list of primitives to construct a network from operator to operator.
Exploration strategy
^^^^^^^^^^^^^^^^^^^^
The exploration strategy details how to explore the search space (which is often exponentially large). It encompasses the classical exploration-exploitation trade-off since, on the one hand, it is desirable to find well-performing architectures quickly, while on the other hand, premature convergence to a region of suboptimal architectures should be avoided. The "best" exploration strategy for a particular scenario is usually found via trial-and-error. As many state-of-the-art strategies are implemented with their own code-base, it becomes very troublesome to switch from one to another.
In NNI, we have also provided :doc:`a list of strategies <exploration_strategy>`. Some of them are powerful yet time consuming, while others might be suboptimal but really efficient. Given that all strategies are implemented with a unified interface, users can always find one that matches their need.
Performance estimation
^^^^^^^^^^^^^^^^^^^^^^
The objective of NAS is typically to find architectures that achieve high predictive performance on unseen data. Performance estimation refers to the process of estimating this performance. The problem with performance estimation is mostly its scalability, i.e., how can I run and manage multiple trials simultaneously.
In NNI, we standardize this process is implemented with :doc:`evaluator <evaluator>`, which is responsible of estimating a model's performance. The choices of evaluators also range from the simplest option, e.g., to perform a standard training and validation of the architecture on data, to complex configurations and implementations. Evaluators are run in *trials*, where trials can be spawn onto distributed platforms with our powerful :doc:`training service </experiment/training_service>`.
Tutorials
---------
To start using NNI NAS framework, we recommend at least going through the following tutorials:
* :doc:`Quickstart </tutorials/hello_nas>`
* :doc:`construct_space`
* :doc:`exploration_strategy`
* :doc:`evaluator`
Resources
---------
The following articles will help with a better understanding of the current arts of NAS:
To be consistent, we will use the following terminologies throughout our documentation:
* `Neural Architecture Search: A Survey <https://arxiv.org/abs/1808.05377>`__
* `A Comprehensive Survey of Neural Architecture Search: Challenges and Solutions <https://arxiv.org/abs/2006.02903>`__
* *Model search space*: it means a set of models from which the best model is explored/searched. Sometimes we use *search space* or *model space* in short.
* *Exploration strategy*: the algorithm that is used to explore a model search space. Sometimes we also call it *search strategy*.
* *Model evaluator*: it is used to train a model and evaluate the model's performance.
Concretely, an exploration strategy selects an architecture from a predefined search space. The architecture is passed to a performance evaluation to get a score, which represents how well this architecture performs on a particular task. This process is repeated until the search process is able to find the best architecture.
During such process, we list out the core engineering challenges (which are also pointed out by the famous `NAS survey <https://arxiv.org/abs/1808.05377>`__) and the solutions NNI has provided to address them:
* **Search space design:** The search space defines which architectures can be represented in principle. Incorporating prior knowledge about typical properties of architectures well-suited for a task can reduce the size of the search space and simplify the search. However, this also introduces a human bias, which may prevent finding novel architectural building blocks that go beyond the current human knowledge. In NNI, we provide a wide range of APIs to build the search space. There are :doc:`high-level APIs <construct_space>`, that enables incorporating human knowledge about what makes a good architecture or search space. There are also :doc:`low-level APIs <mutator>`, that is a list of primitives to construct a network from operator to operator.
* **Exploration strategy:** The exploration strategy details how to explore the search space (which is often exponentially large). It encompasses the classical exploration-exploitation trade-off since, on the one hand, it is desirable to find well-performing architectures quickly, while on the other hand, premature convergence to a region of suboptimal architectures should be avoided. In NNI, we have also provided :doc:`a list of strategies <exploration_strategy>`. Some of them are powerful, but time consuming, while others might be suboptimal but really efficient. Users can always find one that matches their need.
* **Performance estimation / evaluator:** The objective of NAS is typically to find architectures that achieve high predictive performance on unseen data. Performance estimation refers to the process of estimating this performance. In NNI, this process is implemented with :doc:`evaluator <evaluator>`, which is responsible of estimating a model's performance. The choices of evaluators also range from the simplest option, e.g., to perform a standard training and validation of the architecture on data, to complex configurations and implementations.
.. rubric:: Writing Model Space
The following APIs are provided to ease the engineering effort of writing a new search space.
- Policy-based reinforcement learning, based on implementation of tianshou. `Reference <https://arxiv.org/abs/1611.01578>`__
* - :ref:`darts-strategy`
- :ref:`One-shot <one-shot-nas>`
- Continuous relaxation of the architecture representation, allowing efficient search of the architecture using gradient descent. `Reference <https://arxiv.org/abs/1806.09055>`__
* - :ref:`enas-strategy`
- :ref:`One-shot <one-shot-nas>`
- RL controller learns to generate the best network on a super-net. `Reference <https://arxiv.org/abs/1802.03268>`__
* - :ref:`fbnet-strategy`
- :ref:`One-shot <one-shot-nas>`
- Choose the best block by using Gumbel Softmax random sampling and differentiable training. `Reference <https://arxiv.org/abs/1812.03443>`__
* - :ref:`spos-strategy`
- :ref:`One-shot <one-shot-nas>`
- Train a super-net with uniform path sampling. `Reference <https://arxiv.org/abs/1904.00420>`__
* - :ref:`proxylessnas-strategy`
- :ref:`One-shot <one-shot-nas>`
- A low-memory-consuming optimized version of differentiable architecture search. `Reference <https://arxiv.org/abs/1812.00332>`__
.. rubric:: Evaluators
The evaluator APIs can be used to build performance assessment component of your neural architecture search process.
.. list-table::
:header-rows: 1
:widths: auto
* - Name
- Type
- Brief Description
* - :ref:`functional-evaluator`
- General
- Evaluate with any Python function
* - :ref:`classification-evaluator`
- Built upon `PyTorch Lightning <https://www.pytorchlightning.ai/>`__
- For classification tasks
* - :ref:`regression-evaluator`
- Built upon `PyTorch Lightning <https://www.pytorchlightning.ai/>`__
Besides the inline mutation APIs demonstrated :ref:`above <mutation-primitives>`, NNI provides a more general approach to express a model space, i.e., *Mutator*, to cover more complex model spaces. Those inline mutation APIs are also implemented with mutator in the underlying system, which can be seen as a special case of model mutation.
Besides the mutation primitives demonstrated in the :doc:`basic tutorial <construct_space>`, NNI provides a more general approach to express a model space, i.e., *Mutator*, to cover more complex model spaces. The high-level APIs are also implemented with mutator in the underlying system, which can be seen as a special case of model mutation.
.. note:: Mutator and inline mutation APIs cannot be used together.
.. warning:: Mutator and inline mutation APIs can NOT be used together.
A mutator is a piece of logic to express how to mutate a given model. Users are free to write their own mutators. Then a model space is expressed with a base model and a list of mutators. A model in the model space is sampled by applying the mutators on the base model one after another. An example is shown below.
A mutator is a piece of logic to express how to mutate a given model. Users are free to write their own mutators. Then a model space is expressed with a base model and a list of mutators. A model in the model space is sampled by applying the mutators on the base model one after another. An example is shown below.
...
@@ -18,7 +18,7 @@ A mutator is a piece of logic to express how to mutate a given model. Users are
...
@@ -18,7 +18,7 @@ A mutator is a piece of logic to express how to mutate a given model. Users are
Write a mutator
Write a mutator
---------------
---------------
User-defined mutator should inherit ``Mutator`` class, and implement mutation logic in the member function ``mutate``.
User-defined mutator should inherit :class:`nni.retiarii.Mutator` class, and implement mutation logic in the member function :meth:`nni.retiarii.Mutator.mutate`.
.. code-block:: python
.. code-block:: python
...
@@ -35,9 +35,9 @@ User-defined mutator should inherit ``Mutator`` class, and implement mutation lo
...
@@ -35,9 +35,9 @@ User-defined mutator should inherit ``Mutator`` class, and implement mutation lo
The input of ``mutate`` is graph IR (Intermediate Representation) of the base model (please refer to `here <./ApiReference.rst>`__ for the format and APIs of the IR), users can mutate the graph using the graph's member functions (e.g., ``get_nodes_by_label``, ``update_operation``). The mutation operations can be combined with the API ``self.choice``, in order to express a set of possible mutations. In the above example, the node's operation can be changed to any operation from ``candidate_op_list``.
The input of :meth:`nni.retiarii.Mutator.mutate` is graph IR (Intermediate Representation) of the base model, users can mutate the graph using the graph's member functions (e.g., :meth:`nni.retiarii.Model.get_nodes_by_label`). The mutation operations can be combined with the API ``self.choice``, in order to express a set of possible mutations. In the above example, the node's operation can be changed to any operation from ``candidate_op_list``.
Use placeholder to make mutation easier: ``nn.Placeholder``. If you want to mutate a subgraph or node of your model, you can define a placeholder in this model to represent the subgraph or node. Then, use mutator to mutate this placeholder to make it real modules.
Use placeholder to make mutation easier: :class:`nni.retiarii.nn.pytorch.Placeholder`. If you want to mutate a subgraph or node of your model, you can define a placeholder in this model to represent the subgraph or node. Then, use mutator to mutate this placeholder to make it real modules.
.. code-block:: python
.. code-block:: python
...
@@ -62,51 +62,3 @@ Starting an experiment is almost the same as using inline mutation APIs. The onl
...
@@ -62,51 +62,3 @@ Starting an experiment is almost the same as using inline mutation APIs. The onl
In multi-trial NAS, a sampled model should be able to be executed on a remote machine or a training platform (e.g., AzureML, OpenPAI). "Serialization" enables re-instantiation of model evaluator in another process or machine, such that, both the model and its model evaluator should be correctly serialized. To make NNI correctly serialize model evaluator, users should apply ``nni.trace`` on some of their functions and objects. API references can be found in :func:`nni.trace`.
In multi-trial NAS, a sampled model should be able to be executed on a remote machine or a training platform (e.g., AzureML, OpenPAI). "Serialization" enables re-instantiation of model evaluator in another process or machine, such that, both the model and its model evaluator should be correctly serialized. To make NNI correctly serialize model evaluator, users should apply :func:`nni.trace <nni.common.serializer.trace>` on some of their functions and objects. API references can be found in :func:`nni.trace <nni.common.serializer.trace>`.
Serialization is implemented as a combination of `json-tricks <https://json-tricks.readthedocs.io/en/latest/>`_ and `cloudpickle <https://github.com/cloudpipe/cloudpickle>`_. Essentially, it is json-tricks, that is a enhanced version of Python JSON, enabling handling of serialization of numpy arrays, date/times, decimal, fraction and etc. The difference lies in the handling of class instances. Json-tricks deals with class instances with ``__dict__`` and ``__class__``, which in most of our cases are not reliable (e.g., datasets, dataloaders). Rather, our serialization deals with class instances with two methods:
Serialization is implemented as a combination of `json-tricks <https://json-tricks.readthedocs.io/en/latest/>`_ and `cloudpickle <https://github.com/cloudpipe/cloudpickle>`_. Essentially, it is json-tricks, that is a enhanced version of Python JSON, enabling handling of serialization of numpy arrays, date/times, decimal, fraction and etc. The difference lies in the handling of class instances. Json-tricks deals with class instances with ``__dict__`` and ``__class__``, which in most of our cases are not reliable (e.g., datasets, dataloaders). Rather, our serialization deals with class instances with two methods:
1. If the class / factory that creates the object is decorated with ``nni.trace``, we can serialize the class / factory function, along with the parameters, such that the instance can be re-instantiated.
1. If the class / factory that creates the object is decorated with :func:`nni.trace <nni.common.serializer.trace>`, we can serialize the class / factory function, along with the parameters, such that the instance can be re-instantiated.
2. Otherwise, cloudpickle is used to serialize the object into a binary.
2. Otherwise, cloudpickle is used to serialize the object into a binary.
The recommendation is, unless you are absolutely certain that there is no problem and extra burden to serialize the object into binary, always add ``nni.trace``. In most cases, it will be more clean and neat, and enables possibilities such as mutation of parameters (will be supported in future).
The recommendation is, unless you are absolutely certain that there is no problem and extra burden to serialize the object into binary, always add :func:`nni.trace <nni.common.serializer.trace>`. In most cases, it will be more clean and neat, and enables possibilities such as mutation of parameters (will be supported in future).
.. warning::
.. warning::
**What will happen if I forget to "trace" my objects?**
**What will happen if I forget to "trace" my objects?**
It is likely that the program can still run. NNI will try to serialize the untraced object into a binary. It might fail in complex cases. For example, when the object is too large. Even if it succeeds, the result might be a substantially large object. For example, if you forgot to add ``nni.trace`` on ``MNIST``, the MNIST dataset object wil be serialized into binary, which will be dozens of megabytes because the object has the whole 60k images stored inside. You might see warnings and even errors when running experiments. To avoid such issues, the easiest way is to always remember to add ``nni.trace`` to non-primitive objects.
It is likely that the program can still run. NNI will try to serialize the untraced object into a binary. It might fail in complex cases. For example, when the object is too large. Even if it succeeds, the result might be a substantially large object. For example, if you forgot to add :func:`nni.trace <nni.common.serializer.trace>` on ``MNIST``, the MNIST dataset object wil be serialized into binary, which will be dozens of megabytes because the object has the whole 60k images stored inside. You might see warnings and even errors when running experiments. To avoid such issues, the easiest way is to always remember to add :func:`nni.trace <nni.common.serializer.trace>` to non-primitive objects.
.. note:: In Retiarii, serializer will throw exception when one of an single object in the recursive serialization is larger than 64 KB when binary serialized. This indicates that such object needs to be wrapped by ``nni.trace``. In rare cases, if you insist on pickling large data, the limit can be overridden by setting an environment variable ``PICKLE_SIZE_LIMIT``, whose unit is byte. Please note that even if the experiment might be able to run, this can still cause performance issues and even the crash of NNI experiment.
.. note:: In Retiarii, serializer will throw exception when one of an single object in the recursive serialization is larger than 64 KB when binary serialized. This indicates that such object needs to be wrapped by :func:`nni.trace <nni.common.serializer.trace>`. In rare cases, if you insist on pickling large data, the limit can be overridden by setting an environment variable ``PICKLE_SIZE_LIMIT``, whose unit is byte. Please note that even if the experiment might be able to run, this can still cause performance issues and even the crash of NNI experiment.
To trace a function or class, users can use decorator like,
To trace a function or class, users can use decorator like,
...
@@ -26,11 +26,15 @@ To trace a function or class, users can use decorator like,
...
@@ -26,11 +26,15 @@ To trace a function or class, users can use decorator like,
class MyClass:
class MyClass:
...
...
Inline trace that traces instantly on the object instantiation or function invoke is also acceptable: ``nni.trace(MyClass)(parameters)``.
Inline trace that traces instantly on the object instantiation or function invoke is also acceptable:
Assuming a class ``cls`` is already traced, when it is serialized, its class type along with initialization parameters will be dumped. As the parameters are possibly class instances (if not primitive types like ``int`` and ``str``), their serialization will be a similar problem. We recommend decorate them with ``nni.trace`` as well. In other words, ``nni.trace`` should be applied recursively if necessary.
.. code-block:: python
nni.trace(MyClass)(parameters)
Assuming a class ``cls`` is already traced, when it is serialized, its class type along with initialization parameters will be dumped. As the parameters are possibly class instances (if not primitive types like ``int`` and ``str``), their serialization will be a similar problem. We recommend decorate them with :func:`nni.trace <nni.common.serializer.trace>` as well. In other words, :func:`nni.trace <nni.common.serializer.trace>` should be applied recursively if necessary.
Below is an example, ``transforms.Compose``, ``transforms.Normalize``, and ``MNIST`` are serialized manually using ``nni.trace``. ``nni.trace`` takes a class / function as its argument, and returns a wrapped class and function that has the same behavior with the original class / function. The usage of the wrapped class / function is also identical to the original one, except that the arguments are recorded. No need to apply ``nni.trace`` to ``pl.Classification`` and ``pl.DataLoader`` because they are already traced.
Below is an example, ``transforms.Compose``, ``transforms.Normalize``, and ``MNIST`` are serialized manually using :func:`nni.trace <nni.common.serializer.trace>`. :func:`nni.trace <nni.common.serializer.trace>` takes a class / function as its argument, and returns a wrapped class and function that has the same behavior with the original class / function. The usage of the wrapped class / function is also identical to the original one, except that the arguments are recorded. No need to apply :func:`nni.trace <nni.common.serializer.trace>` to :class:`pl.Classification <nni.retiarii.evaluator.pytorch.Classification>` and :class:`pl.DataLoader <nni.retiarii.evaluator.pytorch.DataLoader>` because they are already traced.
.. code-block:: python
.. code-block:: python
...
@@ -57,6 +61,6 @@ Below is an example, ``transforms.Compose``, ``transforms.Normalize``, and ``MNI
...
@@ -57,6 +61,6 @@ Below is an example, ``transforms.Compose``, ``transforms.Normalize``, and ``MNI
**What's the relationship between model_wrapper, basic_unit and nni.trace?**
**What's the relationship between model_wrapper, basic_unit and nni.trace?**
They are fundamentally different. ``model_wrapper`` is used to wrap a base model (search space), ``basic_unit`` to annotate a module as primitive. ``nni.trace`` is to enable serialization of general objects. Though they share similar underlying implementations, but do keep in mind that you will experience errors if you mix them up.
They are fundamentally different. :func:`model_wrapper <nni.retiarii.model_wrapper>` is used to wrap a base model (search space), :func:`basic_unit <nni.retiarii.basic_unit>` to annotate a module as primitive. :func:`nni.trace <nni.common.serializer.trace>` is to enable serialization of general objects. Though they share similar underlying implementations, but do keep in mind that you will experience errors if you mix them up.
.. seealso:: Please refer to API reference of :meth:`nni.retiarii.model_wrapper`, :meth:`nni.retiarii.basic_unit`, and :meth:`nni.trace`.
Please refer to API reference of :meth:`nni.retiarii.model_wrapper`, :meth:`nni.retiarii.basic_unit`, and :func:`nni.trace <nni.common.serializer.trace>`.

{kind=link}