Skip to content
GitLab
Menu
Projects
Groups
Snippets
Loading...
Help
Help
Support
Community forum
Keyboard shortcuts
?
Submit feedback
Contribute to GitLab
Sign in / Register
Toggle navigation
Menu
Open sidebar
OpenDAS
nni
Commits
543239c6
Unverified
Commit
543239c6
authored
Dec 12, 2019
by
SparkSnail
Committed by
GitHub
Dec 12, 2019
Browse files
Merge pull request #220 from microsoft/master
merge master
parents
32efaa36
659480f2
Changes
94
Hide whitespace changes
Inline
Side-by-side
Showing
20 changed files
with
429 additions
and
156 deletions
+429
-156
docs/en_US/reference.rst
docs/en_US/reference.rst
+1
-0
docs/en_US/training_services.rst
docs/en_US/training_services.rst
+2
-1
docs/img/distill.png
docs/img/distill.png
+0
-0
examples/feature_engineering/auto-feature-engineering/README.md
...es/feature_engineering/auto-feature-engineering/README.md
+0
-0
examples/feature_engineering/auto-feature-engineering/README_zh_CN.md
...ture_engineering/auto-feature-engineering/README_zh_CN.md
+0
-0
examples/feature_engineering/gradient_feature_selector/.gitignore
.../feature_engineering/gradient_feature_selector/.gitignore
+5
-0
examples/feature_engineering/gradient_feature_selector/benchmark_test.py
...e_engineering/gradient_feature_selector/benchmark_test.py
+63
-27
examples/feature_engineering/gradient_feature_selector/sklearn_test.py
...ure_engineering/gradient_feature_selector/sklearn_test.py
+18
-16
examples/feature_engineering/gradient_feature_selector/test_memory.py
...ture_engineering/gradient_feature_selector/test_memory.py
+26
-0
examples/feature_engineering/gradient_feature_selector/test_time.py
...eature_engineering/gradient_feature_selector/test_time.py
+26
-0
examples/model_compress/L1_torch_cifar10.py
examples/model_compress/L1_torch_cifar10.py
+3
-55
examples/model_compress/knowledge_distill/knowledge_distill.py
...les/model_compress/knowledge_distill/knowledge_distill.py
+75
-0
examples/model_compress/models/cifar10/vgg.py
examples/model_compress/models/cifar10/vgg.py
+63
-0
examples/model_compress/pruning_kd.py
examples/model_compress/pruning_kd.py
+132
-0
examples/model_compress/slim_torch_cifar10.py
examples/model_compress/slim_torch_cifar10.py
+3
-49
setup.py
setup.py
+1
-1
src/nni_manager/.eslintrc
src/nni_manager/.eslintrc
+6
-1
src/nni_manager/common/component.ts
src/nni_manager/common/component.ts
+0
-1
src/nni_manager/common/datastore.ts
src/nni_manager/common/datastore.ts
+3
-3
src/nni_manager/common/experimentStartupInfo.ts
src/nni_manager/common/experimentStartupInfo.ts
+2
-2
No files found.
docs/en_US/reference.rst
View file @
543239c6
...
@@ -10,3 +10,4 @@ References
...
@@ -10,3 +10,4 @@ References
Configuration<Tutorial/ExperimentConfig>
Configuration<Tutorial/ExperimentConfig>
Search Space <Tutorial/SearchSpaceSpec>
Search Space <Tutorial/SearchSpaceSpec>
TrainingService <TrainingService/HowToImplementTrainingService>
TrainingService <TrainingService/HowToImplementTrainingService>
Framework Library <SupportedFramework_Library>
docs/en_US/training_services.rst
View file @
543239c6
...
@@ -2,8 +2,9 @@ Introduction to NNI Training Services
...
@@ -2,8 +2,9 @@ Introduction to NNI Training Services
=====================================
=====================================
.. toctree::
.. toctree::
Overview <./TrainingService/SupportTrainingService>
Local<./TrainingService/LocalMode>
Local<./TrainingService/LocalMode>
Remote<./TrainingService/RemoteMachineMode>
Remote<./TrainingService/RemoteMachineMode>
OpenPAI<./TrainingService/PaiMode>
OpenPAI<./TrainingService/PaiMode>
Kubeflow<./TrainingService/KubeflowMode>
Kubeflow<./TrainingService/KubeflowMode>
FrameworkController<./TrainingService/FrameworkControllerMode>
FrameworkController<./TrainingService/FrameworkControllerMode>
\ No newline at end of file
docs/img/distill.png
0 → 100644
View file @
543239c6
270 KB
examples/
trials
/auto-feature-engineering/README.md
→
examples/
feature_engineering
/auto-feature-engineering/README.md
View file @
543239c6
File moved
examples/
trials
/auto-feature-engineering/README_zh_CN.md
→
examples/
feature_engineering
/auto-feature-engineering/README_zh_CN.md
View file @
543239c6
File moved
examples/feature_engineering/gradient_feature_selector/.gitignore
0 → 100644
View file @
543239c6
*.bz2
*.svm
*.log
*memory
*time
examples/feature_engineering/gradient_feature_selector/benchmark_test.py
View file @
543239c6
...
@@ -18,6 +18,10 @@
...
@@ -18,6 +18,10 @@
import
bz2
import
bz2
import
urllib.request
import
urllib.request
import
numpy
as
np
import
numpy
as
np
import
datetime
import
line_profiler
profile
=
line_profiler
.
LineProfiler
()
import
os
import
os
...
@@ -34,7 +38,7 @@ from nni.feature_engineering.gradient_selector import FeatureGradientSelector
...
@@ -34,7 +38,7 @@ from nni.feature_engineering.gradient_selector import FeatureGradientSelector
class
Benchmark
():
class
Benchmark
():
def
__init__
(
self
,
files
,
test_size
=
0.2
):
def
__init__
(
self
,
files
=
None
,
test_size
=
0.2
):
self
.
files
=
files
self
.
files
=
files
self
.
test_size
=
test_size
self
.
test_size
=
test_size
...
@@ -73,40 +77,72 @@ class Benchmark():
...
@@ -73,40 +77,72 @@ class Benchmark():
return
update_name
return
update_name
@
profile
def
test_memory
(
pipeline_name
,
name
,
path
):
if
pipeline_name
==
"LR"
:
pipeline
=
make_pipeline
(
LogisticRegression
())
if
pipeline_name
==
"FGS"
:
pipeline
=
make_pipeline
(
FeatureGradientSelector
(),
LogisticRegression
())
if
pipeline_name
==
"Tree"
:
pipeline
=
make_pipeline
(
SelectFromModel
(
ExtraTreesClassifier
(
n_estimators
=
50
)),
LogisticRegression
())
test_benchmark
=
Benchmark
()
print
(
"Dataset:
\t
"
,
name
)
print
(
"Pipeline:
\t
"
,
pipeline_name
)
test_benchmark
.
run_test
(
pipeline
,
name
,
path
)
print
(
""
)
def
test_time
(
pipeline_name
,
name
,
path
):
if
pipeline_name
==
"LR"
:
pipeline
=
make_pipeline
(
LogisticRegression
())
if
pipeline_name
==
"FGS"
:
pipeline
=
make_pipeline
(
FeatureGradientSelector
(),
LogisticRegression
())
if
pipeline_name
==
"Tree"
:
pipeline
=
make_pipeline
(
SelectFromModel
(
ExtraTreesClassifier
(
n_estimators
=
50
)),
LogisticRegression
())
test_benchmark
=
Benchmark
()
print
(
"Dataset:
\t
"
,
name
)
print
(
"Pipeline:
\t
"
,
pipeline_name
)
starttime
=
datetime
.
datetime
.
now
()
test_benchmark
.
run_test
(
pipeline
,
name
,
path
)
endtime
=
datetime
.
datetime
.
now
()
print
(
"Used time: "
,
(
endtime
-
starttime
).
microseconds
/
1000
)
print
(
""
)
if
__name__
==
"__main__"
:
if
__name__
==
"__main__"
:
LIBSVM_DATA
=
{
LIBSVM_DATA
=
{
"rcv1"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/rcv1_train.binary.bz2"
,
"rcv1"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/rcv1_train.binary.bz2"
,
# "avazu" : "https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/avazu-app.bz2",
"colon-cancer"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/covtype.libsvm.binary.bz2"
,
"colon-cancer"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/covtype.libsvm.binary.bz2"
,
"gisette"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/gisette_scale.bz2"
,
"gisette"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/gisette_scale.bz2"
,
# "kdd2010" : "https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/kdda.bz2",
# "kdd2012" : "https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/kdd12.bz2",
"news20.binary"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/news20.binary.bz2"
,
"news20.binary"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/news20.binary.bz2"
,
"real-sim"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/real-sim.bz2"
,
"real-sim"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/real-sim.bz2"
,
"webspam"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/webspam_wc_normalized_trigram.svm.bz2"
"webspam"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/webspam_wc_normalized_trigram.svm.bz2"
,
"avazu"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/avazu-app.bz2"
}
}
test_benchmark
=
Benchmark
(
LIBSVM_DATA
)
import
argparse
parser
=
argparse
.
ArgumentParser
()
pipeline1
=
make_pipeline
(
LogisticRegression
())
parser
.
add_argument
(
'--pipeline_name'
,
type
=
str
,
help
=
'display pipeline_name.'
)
print
(
"Test all data in LogisticRegression."
)
parser
.
add_argument
(
'--name'
,
type
=
str
,
help
=
'display name.'
)
print
()
parser
.
add_argument
(
'--object'
,
type
=
str
,
help
=
'display test object: time or memory.'
)
test_benchmark
.
run_all_test
(
pipeline1
)
args
=
parser
.
parse_args
()
pipeline2
=
make_pipeline
(
FeatureGradientSelector
(),
LogisticRegression
())
pipeline_name
=
args
.
pipeline_name
print
(
"Test data selected by FeatureGradientSelector in LogisticRegression."
)
name
=
args
.
name
print
()
test_object
=
args
.
object
test_benchmark
.
run_all_test
(
pipeline2
)
path
=
LIBSVM_DATA
[
name
]
pipeline3
=
make_pipeline
(
SelectFromModel
(
ExtraTreesClassifier
(
n_estimators
=
50
)),
LogisticRegression
())
if
test_object
==
'time'
:
print
(
"Test data selected by TreeClssifier in LogisticRegression."
)
test_time
(
pipeline_name
,
name
,
path
)
print
()
elif
test_object
==
'memory'
:
test_benchmark
.
run_all_test
(
pipeline3
)
test_memory
(
pipeline_name
,
name
,
path
)
else
:
pipeline4
=
make_pipeline
(
FeatureGradientSelector
(
n_features
=
20
),
LogisticRegression
())
print
(
"Not support test object.
\t
"
,
test_object
)
print
(
"Test data selected by FeatureGradientSelector top 20 in LogisticRegression."
)
print
()
test_benchmark
.
run_all_test
(
pipeline4
)
print
(
"Done."
)
print
(
"Done."
)
\ No newline at end of file
examples/feature_engineering/gradient_feature_selector/sklearn_test.py
View file @
543239c6
...
@@ -30,26 +30,28 @@ from sklearn.feature_selection import SelectFromModel
...
@@ -30,26 +30,28 @@ from sklearn.feature_selection import SelectFromModel
from
nni.feature_engineering.gradient_selector
import
FeatureGradientSelector
from
nni.feature_engineering.gradient_selector
import
FeatureGradientSelector
url_zip_train
=
'https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/rcv1_train.binary.bz2'
urllib
.
request
.
urlretrieve
(
url_zip_train
,
filename
=
'train.bz2'
)
f_svm
=
open
(
'train.svm'
,
'wt'
)
def
test
():
with
bz2
.
open
(
'train.bz2'
,
'rb'
)
as
f_zip
:
url_zip_train
=
'https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/rcv1_train.binary.bz2'
data
=
f_zip
.
read
()
urllib
.
request
.
urlretrieve
(
url_zip_train
,
filename
=
'train.bz2'
)
f_svm
.
write
(
data
.
decode
(
'utf-8'
))
f_svm
.
close
()
f_svm
=
open
(
'train.svm'
,
'wt'
)
with
bz2
.
open
(
'train.bz2'
,
'rb'
)
as
f_zip
:
data
=
f_zip
.
read
()
f_svm
.
write
(
data
.
decode
(
'utf-8'
))
f_svm
.
close
()
X
,
y
=
load_svmlight_file
(
'train.svm'
)
X_train
,
X_test
,
y_train
,
y_test
=
train_test_split
(
X
,
y
,
test_size
=
0.33
,
random_state
=
42
)
fgs
=
FeatureGradientSelector
(
n_features
=
10
)
X
,
y
=
load_svmlight_file
(
'train.svm'
)
fgs
.
fit
(
X_train
,
y_train
)
X_train
,
X_test
,
y_train
,
y_test
=
train_test_split
(
X
,
y
,
test_size
=
0.33
,
random_state
=
42
)
print
(
"selected features
\t
"
,
fgs
.
get_selected_features
())
pipeline
=
make_pipeline
(
FeatureGradientSelector
(
n_epochs
=
1
,
n_features
=
10
),
LogisticRegression
())
pipeline
=
make_pipeline
(
FeatureGradientSelector
(
n_epochs
=
1
,
n_features
=
10
),
LogisticRegression
())
# pipeline = make_pipeline(SelectFromModel(ExtraTreesClassifier(n_estimators=50)), LogisticRegression())
# pipeline = make_pipeline(SelectFromModel(ExtraTreesClassifier(n_estimators=50)), LogisticRegression())
pipeline
.
fit
(
X_train
,
y_train
)
print
(
"Pipeline Score: "
,
pipeline
.
score
(
X_train
,
y_train
))
pipeline
.
fit
(
X_train
,
y_train
)
\ No newline at end of file
print
(
"Pipeline Score: "
,
pipeline
.
score
(
X_train
,
y_train
))
if
__name__
==
"__main__"
:
test
()
\ No newline at end of file
examples/feature_engineering/gradient_feature_selector/test_memory.py
0 → 100644
View file @
543239c6
import
os
LIBSVM_DATA
=
{
"rcv1"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/rcv1_train.binary.bz2"
,
"colon-cancer"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/covtype.libsvm.binary.bz2"
,
"gisette"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/gisette_scale.bz2"
,
"news20.binary"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/news20.binary.bz2"
,
"real-sim"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/real-sim.bz2"
,
"avazu"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/avazu-app.bz2"
,
}
pipeline_name
=
"Tree"
device
=
"CUDA_VISIBLE_DEVICES=0 "
script
=
"setsid python -m memory_profiler benchmark_test.py "
test_object
=
"memory"
for
name
in
LIBSVM_DATA
:
log_name
=
"_"
.
join
([
pipeline_name
,
name
,
test_object
])
command
=
device
+
script
+
"--pipeline_name "
+
pipeline_name
+
" --name "
+
name
+
" --object "
+
test_object
+
" >"
+
log_name
+
" 2>&1 &"
print
(
"command is
\t
"
,
command
)
os
.
system
(
command
)
print
(
"log is here
\t
"
,
log_name
)
print
(
"Done."
)
examples/feature_engineering/gradient_feature_selector/test_time.py
0 → 100644
View file @
543239c6
import
os
LIBSVM_DATA
=
{
"rcv1"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/rcv1_train.binary.bz2"
,
"colon-cancer"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/covtype.libsvm.binary.bz2"
,
"gisette"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/gisette_scale.bz2"
,
"news20.binary"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/news20.binary.bz2"
,
"real-sim"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/real-sim.bz2"
,
"avazu"
:
"https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/binary/avazu-app.bz2"
,
}
pipeline_name
=
"LR"
device
=
"CUDA_VISIBLE_DEVICES=0 "
script
=
"setsid python benchmark_test.py "
test_object
=
"time"
for
name
in
LIBSVM_DATA
:
log_name
=
"_"
.
join
([
pipeline_name
,
name
,
test_object
])
command
=
device
+
script
+
"--pipeline_name "
+
pipeline_name
+
" --name "
+
name
+
" --object "
+
test_object
+
" >"
+
log_name
+
" 2>&1 &"
print
(
"command is
\t
"
,
command
)
os
.
system
(
command
)
print
(
"log is here
\t
"
,
log_name
)
print
(
"Done."
)
examples/model_compress/L1_
filter_pruner_torch_vgg16
.py
→
examples/model_compress/L1_
torch_cifar10
.py
View file @
543239c6
...
@@ -4,59 +4,7 @@ import torch.nn as nn
...
@@ -4,59 +4,7 @@ import torch.nn as nn
import
torch.nn.functional
as
F
import
torch.nn.functional
as
F
from
torchvision
import
datasets
,
transforms
from
torchvision
import
datasets
,
transforms
from
nni.compression.torch
import
L1FilterPruner
from
nni.compression.torch
import
L1FilterPruner
from
models.cifar10.vgg
import
VGG
class
vgg
(
nn
.
Module
):
def
__init__
(
self
,
init_weights
=
True
):
super
(
vgg
,
self
).
__init__
()
cfg
=
[
64
,
64
,
'M'
,
128
,
128
,
'M'
,
256
,
256
,
256
,
'M'
,
512
,
512
,
512
,
'M'
,
512
,
512
,
512
]
self
.
cfg
=
cfg
self
.
feature
=
self
.
make_layers
(
cfg
,
True
)
num_classes
=
10
self
.
classifier
=
nn
.
Sequential
(
nn
.
Linear
(
cfg
[
-
1
],
512
),
nn
.
BatchNorm1d
(
512
),
nn
.
ReLU
(
inplace
=
True
),
nn
.
Linear
(
512
,
num_classes
)
)
if
init_weights
:
self
.
_initialize_weights
()
def
make_layers
(
self
,
cfg
,
batch_norm
=
True
):
layers
=
[]
in_channels
=
3
for
v
in
cfg
:
if
v
==
'M'
:
layers
+=
[
nn
.
MaxPool2d
(
kernel_size
=
2
,
stride
=
2
)]
else
:
conv2d
=
nn
.
Conv2d
(
in_channels
,
v
,
kernel_size
=
3
,
padding
=
1
,
bias
=
False
)
if
batch_norm
:
layers
+=
[
conv2d
,
nn
.
BatchNorm2d
(
v
),
nn
.
ReLU
(
inplace
=
True
)]
else
:
layers
+=
[
conv2d
,
nn
.
ReLU
(
inplace
=
True
)]
in_channels
=
v
return
nn
.
Sequential
(
*
layers
)
def
forward
(
self
,
x
):
x
=
self
.
feature
(
x
)
x
=
nn
.
AvgPool2d
(
2
)(
x
)
x
=
x
.
view
(
x
.
size
(
0
),
-
1
)
y
=
self
.
classifier
(
x
)
return
y
def
_initialize_weights
(
self
):
for
m
in
self
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
n
=
m
.
kernel_size
[
0
]
*
m
.
kernel_size
[
1
]
*
m
.
out_channels
m
.
weight
.
data
.
normal_
(
0
,
math
.
sqrt
(
2.
/
n
))
if
m
.
bias
is
not
None
:
m
.
bias
.
data
.
zero_
()
elif
isinstance
(
m
,
nn
.
BatchNorm2d
):
m
.
weight
.
data
.
fill_
(
0.5
)
m
.
bias
.
data
.
zero_
()
elif
isinstance
(
m
,
nn
.
Linear
):
m
.
weight
.
data
.
normal_
(
0
,
0.01
)
m
.
bias
.
data
.
zero_
()
def
train
(
model
,
device
,
train_loader
,
optimizer
):
def
train
(
model
,
device
,
train_loader
,
optimizer
):
...
@@ -111,7 +59,7 @@ def main():
...
@@ -111,7 +59,7 @@ def main():
])),
])),
batch_size
=
200
,
shuffle
=
False
)
batch_size
=
200
,
shuffle
=
False
)
model
=
vgg
(
)
model
=
VGG
(
depth
=
16
)
model
.
to
(
device
)
model
.
to
(
device
)
# Train the base VGG-16 model
# Train the base VGG-16 model
...
@@ -162,7 +110,7 @@ def main():
...
@@ -162,7 +110,7 @@ def main():
# Test the exported model
# Test the exported model
print
(
'='
*
10
+
'Test on the pruned model after fine tune'
+
'='
*
10
)
print
(
'='
*
10
+
'Test on the pruned model after fine tune'
+
'='
*
10
)
new_model
=
vgg
(
)
new_model
=
VGG
(
depth
=
16
)
new_model
.
to
(
device
)
new_model
.
to
(
device
)
new_model
.
load_state_dict
(
torch
.
load
(
'pruned_vgg16_cifar10.pth'
))
new_model
.
load_state_dict
(
torch
.
load
(
'pruned_vgg16_cifar10.pth'
))
test
(
new_model
,
device
,
test_loader
)
test
(
new_model
,
device
,
test_loader
)
...
...
examples/model_compress/knowledge_distill/knowledge_distill.py
0 → 100644
View file @
543239c6
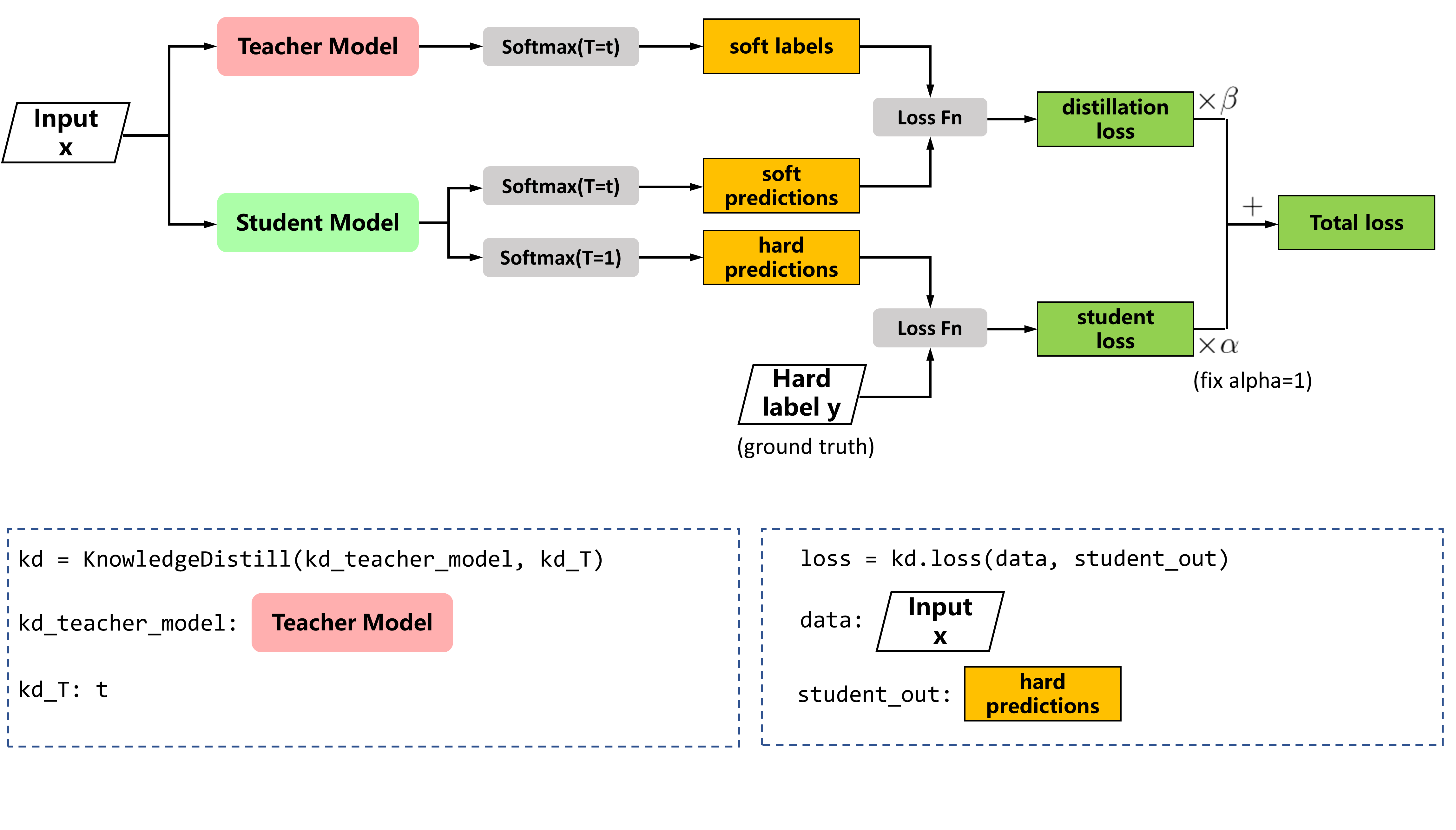
import
logging
import
torch
import
torch.nn.functional
as
F
_logger
=
logging
.
getLogger
(
__name__
)
class
KnowledgeDistill
():
"""
Knowledge Distillaion support while fine-tuning the compressed model
Geoffrey Hinton, Oriol Vinyals, Jeff Dean
"Distilling the Knowledge in a Neural Network"
https://arxiv.org/abs/1503.02531
"""
def
__init__
(
self
,
teacher_model
,
kd_T
=
1
):
"""
Parameters
----------
teacher_model : pytorch model
the teacher_model for teaching the student model, it should be pretrained
kd_T: float
kd_T is the temperature parameter, when kd_T=1 we get the standard softmax function
As kd_T grows, the probability distribution generated by the softmax function becomes softer
"""
self
.
teacher_model
=
teacher_model
self
.
kd_T
=
kd_T
def
_get_kd_loss
(
self
,
data
,
student_out
,
teacher_out_preprocess
=
None
):
"""
Parameters
----------
data : torch.Tensor
the input training data
student_out: torch.Tensor
output of the student network
teacher_out_preprocess: function
a function for pre-processing teacher_model's output
e.g. when teacher_out_preprocess=lambda x:x[0]
extract teacher_model's output (tensor1, tensor2)->tensor1
Returns
-------
torch.Tensor
weighted distillation loss
"""
with
torch
.
no_grad
():
kd_out
=
self
.
teacher_model
(
data
)
if
teacher_out_preprocess
is
not
None
:
kd_out
=
teacher_out_preprocess
(
kd_out
)
assert
type
(
kd_out
)
is
torch
.
Tensor
assert
type
(
student_out
)
is
torch
.
Tensor
assert
kd_out
.
shape
==
student_out
.
shape
soft_log_out
=
F
.
log_softmax
(
student_out
/
self
.
kd_T
,
dim
=
1
)
soft_t
=
F
.
softmax
(
kd_out
/
self
.
kd_T
,
dim
=
1
)
loss_kd
=
F
.
kl_div
(
soft_log_out
,
soft_t
.
detach
(),
reduction
=
'batchmean'
)
return
loss_kd
def
loss
(
self
,
data
,
student_out
):
"""
Parameters
----------
data : torch.Tensor
Input of the student model
student_out : torch.Tensor
Output of the student model
Returns
-------
torch.Tensor
Weighted loss of student loss and distillation loss
"""
return
self
.
_get_kd_loss
(
data
,
student_out
)
examples/model_compress/models/cifar10/vgg.py
0 → 100644
View file @
543239c6
import
math
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
defaultcfg
=
{
11
:
[
64
,
'M'
,
128
,
'M'
,
256
,
256
,
'M'
,
512
,
512
,
'M'
,
512
,
512
],
13
:
[
64
,
64
,
'M'
,
128
,
128
,
'M'
,
256
,
256
,
'M'
,
512
,
512
,
'M'
,
512
,
512
],
16
:
[
64
,
64
,
'M'
,
128
,
128
,
'M'
,
256
,
256
,
256
,
'M'
,
512
,
512
,
512
,
'M'
,
512
,
512
,
512
],
19
:
[
64
,
64
,
'M'
,
128
,
128
,
'M'
,
256
,
256
,
256
,
256
,
'M'
,
512
,
512
,
512
,
512
,
'M'
,
512
,
512
,
512
,
512
],
}
class
VGG
(
nn
.
Module
):
def
__init__
(
self
,
depth
=
16
):
super
(
VGG
,
self
).
__init__
()
cfg
=
defaultcfg
[
depth
]
self
.
cfg
=
cfg
self
.
feature
=
self
.
make_layers
(
cfg
,
True
)
num_classes
=
10
self
.
classifier
=
nn
.
Sequential
(
nn
.
Linear
(
cfg
[
-
1
],
512
),
nn
.
BatchNorm1d
(
512
),
nn
.
ReLU
(
inplace
=
True
),
nn
.
Linear
(
512
,
num_classes
)
)
self
.
_initialize_weights
()
def
make_layers
(
self
,
cfg
,
batch_norm
=
False
):
layers
=
[]
in_channels
=
3
for
v
in
cfg
:
if
v
==
'M'
:
layers
+=
[
nn
.
MaxPool2d
(
kernel_size
=
2
,
stride
=
2
)]
else
:
conv2d
=
nn
.
Conv2d
(
in_channels
,
v
,
kernel_size
=
3
,
padding
=
1
,
bias
=
False
)
if
batch_norm
:
layers
+=
[
conv2d
,
nn
.
BatchNorm2d
(
v
),
nn
.
ReLU
(
inplace
=
True
)]
else
:
layers
+=
[
conv2d
,
nn
.
ReLU
(
inplace
=
True
)]
in_channels
=
v
return
nn
.
Sequential
(
*
layers
)
def
forward
(
self
,
x
):
x
=
self
.
feature
(
x
)
x
=
nn
.
AvgPool2d
(
2
)(
x
)
x
=
x
.
view
(
x
.
size
(
0
),
-
1
)
y
=
self
.
classifier
(
x
)
return
y
def
_initialize_weights
(
self
):
for
m
in
self
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
n
=
m
.
kernel_size
[
0
]
*
m
.
kernel_size
[
1
]
*
m
.
out_channels
m
.
weight
.
data
.
normal_
(
0
,
math
.
sqrt
(
2.
/
n
))
if
m
.
bias
is
not
None
:
m
.
bias
.
data
.
zero_
()
elif
isinstance
(
m
,
nn
.
BatchNorm2d
):
m
.
weight
.
data
.
fill_
(
0.5
)
m
.
bias
.
data
.
zero_
()
elif
isinstance
(
m
,
nn
.
Linear
):
m
.
weight
.
data
.
normal_
(
0
,
0.01
)
m
.
bias
.
data
.
zero_
()
examples/model_compress/pruning_kd.py
0 → 100644
View file @
543239c6
import
math
import
torch
import
torch.nn
as
nn
import
torch.nn.functional
as
F
from
torchvision
import
datasets
,
transforms
from
nni.compression.torch
import
L1FilterPruner
from
knowledge_distill.knowledge_distill
import
KnowledgeDistill
from
models.cifar10.vgg
import
VGG
def
train
(
model
,
device
,
train_loader
,
optimizer
,
kd
=
None
):
alpha
=
1
beta
=
0.8
model
.
train
()
for
batch_idx
,
(
data
,
target
)
in
enumerate
(
train_loader
):
data
,
target
=
data
.
to
(
device
),
target
.
to
(
device
)
optimizer
.
zero_grad
()
output
=
model
(
data
)
student_loss
=
F
.
cross_entropy
(
output
,
target
)
if
kd
is
not
None
:
kd_loss
=
kd
.
loss
(
data
=
data
,
student_out
=
output
)
loss
=
alpha
*
student_loss
+
beta
*
kd_loss
else
:
loss
=
student_loss
loss
.
backward
()
optimizer
.
step
()
if
batch_idx
%
100
==
0
:
print
(
'{:2.0f}% Loss {}'
.
format
(
100
*
batch_idx
/
len
(
train_loader
),
loss
.
item
()))
def
test
(
model
,
device
,
test_loader
):
model
.
eval
()
test_loss
=
0
correct
=
0
with
torch
.
no_grad
():
for
data
,
target
in
test_loader
:
data
,
target
=
data
.
to
(
device
),
target
.
to
(
device
)
output
=
model
(
data
)
test_loss
+=
F
.
nll_loss
(
output
,
target
,
reduction
=
'sum'
).
item
()
pred
=
output
.
argmax
(
dim
=
1
,
keepdim
=
True
)
correct
+=
pred
.
eq
(
target
.
view_as
(
pred
)).
sum
().
item
()
test_loss
/=
len
(
test_loader
.
dataset
)
acc
=
100
*
correct
/
len
(
test_loader
.
dataset
)
print
(
'Loss: {} Accuracy: {}%)
\n
'
.
format
(
test_loss
,
acc
))
return
acc
def
main
():
torch
.
manual_seed
(
0
)
device
=
torch
.
device
(
'cuda'
)
train_loader
=
torch
.
utils
.
data
.
DataLoader
(
datasets
.
CIFAR10
(
'./data.cifar10'
,
train
=
True
,
download
=
True
,
transform
=
transforms
.
Compose
([
transforms
.
Pad
(
4
),
transforms
.
RandomCrop
(
32
),
transforms
.
RandomHorizontalFlip
(),
transforms
.
ToTensor
(),
transforms
.
Normalize
((
0.4914
,
0.4822
,
0.4465
),
(
0.2023
,
0.1994
,
0.2010
))
])),
batch_size
=
64
,
shuffle
=
True
)
test_loader
=
torch
.
utils
.
data
.
DataLoader
(
datasets
.
CIFAR10
(
'./data.cifar10'
,
train
=
False
,
transform
=
transforms
.
Compose
([
transforms
.
ToTensor
(),
transforms
.
Normalize
((
0.4914
,
0.4822
,
0.4465
),
(
0.2023
,
0.1994
,
0.2010
))
])),
batch_size
=
200
,
shuffle
=
False
)
model
=
VGG
(
depth
=
16
)
model
.
to
(
device
)
# Train the base VGG-16 model
print
(
'='
*
10
+
'Train the unpruned base model'
+
'='
*
10
)
optimizer
=
torch
.
optim
.
SGD
(
model
.
parameters
(),
lr
=
0.1
,
momentum
=
0.9
,
weight_decay
=
1e-4
)
lr_scheduler
=
torch
.
optim
.
lr_scheduler
.
CosineAnnealingLR
(
optimizer
,
160
,
0
)
for
epoch
in
range
(
160
):
print
(
'# Epoch {} #'
.
format
(
epoch
))
train
(
model
,
device
,
train_loader
,
optimizer
)
test
(
model
,
device
,
test_loader
)
lr_scheduler
.
step
(
epoch
)
torch
.
save
(
model
.
state_dict
(),
'vgg16_cifar10.pth'
)
# Test base model accuracy
print
(
'='
*
10
+
'Test on the original model'
+
'='
*
10
)
model
.
load_state_dict
(
torch
.
load
(
'vgg16_cifar10.pth'
))
test
(
model
,
device
,
test_loader
)
# top1 = 93.51%
# Pruning Configuration, all convolution layers are pruned out 80% filters according to the L1 norm
configure_list
=
[{
'sparsity'
:
0.8
,
'op_types'
:
[
'Conv2d'
],
}]
# Prune model and test accuracy without fine tuning.
print
(
'='
*
10
+
'Test on the pruned model before fine tune'
+
'='
*
10
)
pruner
=
L1FilterPruner
(
model
,
configure_list
)
model
=
pruner
.
compress
()
test
(
model
,
device
,
test_loader
)
# top1 = 10.00%
# Fine tune the pruned model for 40 epochs and test accuracy
print
(
'='
*
10
+
'Fine tuning'
+
'='
*
10
)
optimizer_finetune
=
torch
.
optim
.
SGD
(
model
.
parameters
(),
lr
=
0.001
,
momentum
=
0.9
,
weight_decay
=
1e-4
)
best_top1
=
0
kd_teacher_model
=
VGG
(
depth
=
16
)
kd_teacher_model
.
to
(
device
)
kd_teacher_model
.
load_state_dict
(
torch
.
load
(
'vgg16_cifar10.pth'
))
kd
=
KnowledgeDistill
(
kd_teacher_model
,
kd_T
=
5
)
for
epoch
in
range
(
40
):
pruner
.
update_epoch
(
epoch
)
print
(
'# Epoch {} #'
.
format
(
epoch
))
train
(
model
,
device
,
train_loader
,
optimizer_finetune
,
kd
)
top1
=
test
(
model
,
device
,
test_loader
)
if
top1
>
best_top1
:
best_top1
=
top1
# Export the best model, 'model_path' stores state_dict of the pruned model,
# mask_path stores mask_dict of the pruned model
pruner
.
export_model
(
model_path
=
'pruned_vgg16_cifar10.pth'
,
mask_path
=
'mask_vgg16_cifar10.pth'
)
# Test the exported model
print
(
'='
*
10
+
'Test on the pruned model after fine tune'
+
'='
*
10
)
new_model
=
VGG
(
depth
=
16
)
new_model
.
to
(
device
)
new_model
.
load_state_dict
(
torch
.
load
(
'pruned_vgg16_cifar10.pth'
))
test
(
new_model
,
device
,
test_loader
)
# top1 = 85.43% with kd, top1 = 85.04% without kd,
if
__name__
==
'__main__'
:
main
()
examples/model_compress/slim_
pruner_torch_vgg19
.py
→
examples/model_compress/slim_
torch_cifar10
.py
View file @
543239c6
...
@@ -4,53 +4,7 @@ import torch.nn as nn
...
@@ -4,53 +4,7 @@ import torch.nn as nn
import
torch.nn.functional
as
F
import
torch.nn.functional
as
F
from
torchvision
import
datasets
,
transforms
from
torchvision
import
datasets
,
transforms
from
nni.compression.torch
import
SlimPruner
from
nni.compression.torch
import
SlimPruner
from
models.cifar10.vgg
import
VGG
class
vgg
(
nn
.
Module
):
def
__init__
(
self
,
init_weights
=
True
):
super
(
vgg
,
self
).
__init__
()
cfg
=
[
64
,
64
,
'M'
,
128
,
128
,
'M'
,
256
,
256
,
256
,
256
,
'M'
,
512
,
512
,
512
,
512
,
'M'
,
512
,
512
,
512
,
512
]
self
.
feature
=
self
.
make_layers
(
cfg
,
True
)
num_classes
=
10
self
.
classifier
=
nn
.
Linear
(
cfg
[
-
1
],
num_classes
)
if
init_weights
:
self
.
_initialize_weights
()
def
make_layers
(
self
,
cfg
,
batch_norm
=
False
):
layers
=
[]
in_channels
=
3
for
v
in
cfg
:
if
v
==
'M'
:
layers
+=
[
nn
.
MaxPool2d
(
kernel_size
=
2
,
stride
=
2
)]
else
:
conv2d
=
nn
.
Conv2d
(
in_channels
,
v
,
kernel_size
=
3
,
padding
=
1
,
bias
=
False
)
if
batch_norm
:
layers
+=
[
conv2d
,
nn
.
BatchNorm2d
(
v
),
nn
.
ReLU
(
inplace
=
True
)]
else
:
layers
+=
[
conv2d
,
nn
.
ReLU
(
inplace
=
True
)]
in_channels
=
v
return
nn
.
Sequential
(
*
layers
)
def
forward
(
self
,
x
):
x
=
self
.
feature
(
x
)
x
=
nn
.
AvgPool2d
(
2
)(
x
)
x
=
x
.
view
(
x
.
size
(
0
),
-
1
)
y
=
self
.
classifier
(
x
)
return
y
def
_initialize_weights
(
self
):
for
m
in
self
.
modules
():
if
isinstance
(
m
,
nn
.
Conv2d
):
n
=
m
.
kernel_size
[
0
]
*
m
.
kernel_size
[
1
]
*
m
.
out_channels
m
.
weight
.
data
.
normal_
(
0
,
math
.
sqrt
(
2.
/
n
))
if
m
.
bias
is
not
None
:
m
.
bias
.
data
.
zero_
()
elif
isinstance
(
m
,
nn
.
BatchNorm2d
):
m
.
weight
.
data
.
fill_
(
0.5
)
m
.
bias
.
data
.
zero_
()
elif
isinstance
(
m
,
nn
.
Linear
):
m
.
weight
.
data
.
normal_
(
0
,
0.01
)
m
.
bias
.
data
.
zero_
()
def
updateBN
(
model
):
def
updateBN
(
model
):
...
@@ -114,7 +68,7 @@ def main():
...
@@ -114,7 +68,7 @@ def main():
])),
])),
batch_size
=
200
,
shuffle
=
False
)
batch_size
=
200
,
shuffle
=
False
)
model
=
vgg
(
)
model
=
VGG
(
depth
=
19
)
model
.
to
(
device
)
model
.
to
(
device
)
# Train the base VGG-19 model
# Train the base VGG-19 model
...
@@ -165,7 +119,7 @@ def main():
...
@@ -165,7 +119,7 @@ def main():
# Test the exported model
# Test the exported model
print
(
'='
*
10
+
'Test the export pruned model after fine tune'
+
'='
*
10
)
print
(
'='
*
10
+
'Test the export pruned model after fine tune'
+
'='
*
10
)
new_model
=
vgg
(
)
new_model
=
VGG
(
depth
=
19
)
new_model
.
to
(
device
)
new_model
.
to
(
device
)
new_model
.
load_state_dict
(
torch
.
load
(
'pruned_vgg19_cifar10.pth'
))
new_model
.
load_state_dict
(
torch
.
load
(
'pruned_vgg19_cifar10.pth'
))
test
(
new_model
,
device
,
test_loader
)
test
(
new_model
,
device
,
test_loader
)
...
...
setup.py
View file @
543239c6
...
@@ -40,7 +40,7 @@ setup(
...
@@ -40,7 +40,7 @@ setup(
'schema'
,
'schema'
,
'PythonWebHDFS'
,
'PythonWebHDFS'
,
'colorama'
,
'colorama'
,
'scikit-learn
=
=0.20'
'scikit-learn
>
=0.20
,<0.22
'
],
],
entry_points
=
{
entry_points
=
{
...
...
src/nni_manager/.eslintrc
View file @
543239c6
...
@@ -18,7 +18,12 @@
...
@@ -18,7 +18,12 @@
"plugin:@typescript-eslint/recommended"
"plugin:@typescript-eslint/recommended"
],
],
"rules": {
"rules": {
"@typescript-eslint/no-explicit-any": 0
"@typescript-eslint/no-explicit-any": 0,
"@typescript-eslint/no-namespace": 0,
"@typescript-eslint/consistent-type-assertions": 0,
"@typescript-eslint/no-inferrable-types": 0,
"no-inner-declarations": 0,
"@typescript-eslint/no-var-requires": 0
},
},
"ignorePatterns": [
"ignorePatterns": [
"node_modules/",
"node_modules/",
...
...
src/nni_manager/common/component.ts
View file @
543239c6
...
@@ -5,7 +5,6 @@
...
@@ -5,7 +5,6 @@
import
*
as
ioc
from
'
typescript-ioc
'
;
import
*
as
ioc
from
'
typescript-ioc
'
;
// tslint:disable-next-line:no-any
const
Inject
:
(...
args
:
any
[])
=>
any
=
ioc
.
Inject
;
const
Inject
:
(...
args
:
any
[])
=>
any
=
ioc
.
Inject
;
const
Singleton
:
(
target
:
Function
)
=>
void
=
ioc
.
Singleton
;
const
Singleton
:
(
target
:
Function
)
=>
void
=
ioc
.
Singleton
;
const
Container
=
ioc
.
Container
;
const
Container
=
ioc
.
Container
;
...
...
src/nni_manager/common/datastore.ts
View file @
543239c6
...
@@ -56,13 +56,13 @@ interface TrialJobInfo {
...
@@ -56,13 +56,13 @@ interface TrialJobInfo {
interface
HyperParameterFormat
{
interface
HyperParameterFormat
{
parameter_source
:
string
;
parameter_source
:
string
;
parameters
:
Object
;
parameters
:
Record
<
string
,
any
>
;
parameter_id
:
number
;
parameter_id
:
number
;
}
}
interface
ExportedDataFormat
{
interface
ExportedDataFormat
{
parameter
:
Object
;
parameter
:
Record
<
string
,
any
>
;
value
:
Object
;
value
:
Record
<
string
,
any
>
;
id
:
string
;
id
:
string
;
}
}
...
...
src/nni_manager/common/experimentStartupInfo.ts
View file @
543239c6
...
@@ -27,9 +27,9 @@ class ExperimentStartupInfo {
...
@@ -27,9 +27,9 @@ class ExperimentStartupInfo {
this
.
initialized
=
true
;
this
.
initialized
=
true
;
if
(
logDir
!==
undefined
&&
logDir
.
length
>
0
)
{
if
(
logDir
!==
undefined
&&
logDir
.
length
>
0
)
{
this
.
logDir
=
path
.
join
(
path
.
normalize
(
logDir
),
getExperimentId
());
this
.
logDir
=
path
.
join
(
path
.
normalize
(
logDir
),
this
.
getExperimentId
());
}
else
{
}
else
{
this
.
logDir
=
path
.
join
(
os
.
homedir
(),
'
nni
'
,
'
experiments
'
,
getExperimentId
());
this
.
logDir
=
path
.
join
(
os
.
homedir
(),
'
nni
'
,
'
experiments
'
,
this
.
getExperimentId
());
}
}
if
(
logLevel
!==
undefined
&&
logLevel
.
length
>
1
)
{
if
(
logLevel
!==
undefined
&&
logLevel
.
length
>
1
)
{
...
...
Prev
1
2
3
4
5
Next
Write
Preview
Markdown
is supported
0%
Try again
or
attach a new file
.
Attach a file
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Cancel
Please
register
or
sign in
to comment

{kind=link}