To simplify writing a new compression algorithm, we design programming interfaces which are simple but flexible enough. There are interfaces for pruning and quantization respectively. Below, we first demonstrate how to customize a new pruning algorithm and then demonstrate how to customize a new quantization algorithm.
## Customize a new pruning algorithm
To better demonstrate how to customize a new pruning algorithm, it is necessary for users to first understand the framework for supporting various pruning algorithms in NNI.
### Framework overview for pruning algorithms
Following example shows how to use a pruner:
Following example shows how to use a pruner:
...
@@ -26,11 +36,11 @@ A pruner receives `model`, `config_list` and `optimizer` as arguments. It prunes
...
@@ -26,11 +36,11 @@ A pruner receives `model`, `config_list` and `optimizer` as arguments. It prunes
From implementation perspective, a pruner consists of a `weight masker` instance and multiple `module wrapper` instances.
From implementation perspective, a pruner consists of a `weight masker` instance and multiple `module wrapper` instances.
### Weight masker
#### Weight masker
A `weight masker` is the implementation of pruning algorithms, it can prune a specified layer wrapped by `module wrapper` with specified sparsity.
A `weight masker` is the implementation of pruning algorithms, it can prune a specified layer wrapped by `module wrapper` with specified sparsity.
### Module wrapper
#### Module wrapper
A `module wrapper` is a module containing:
A `module wrapper` is a module containing:
...
@@ -43,7 +53,7 @@ the reasons to use `module wrapper`:
...
@@ -43,7 +53,7 @@ the reasons to use `module wrapper`:
1. some buffers are needed by `calc_mask` to calculate masks and these buffers should be registered in `module wrapper` so that the original modules are not contaminated.
1. some buffers are needed by `calc_mask` to calculate masks and these buffers should be registered in `module wrapper` so that the original modules are not contaminated.
2. a new `forward` method is needed to apply masks to weight before calling the real `forward` method.
2. a new `forward` method is needed to apply masks to weight before calling the real `forward` method.
### Pruner
#### Pruner
A `pruner` is responsible for:
A `pruner` is responsible for:
...
@@ -52,9 +62,9 @@ A `pruner` is responsible for:
...
@@ -52,9 +62,9 @@ A `pruner` is responsible for:
3. Use `weight masker` to calculate masks of layers while pruning.
3. Use `weight masker` to calculate masks of layers while pruning.
4. Export pruned model weights and masks.
4. Export pruned model weights and masks.
## Implement a new pruning algorithm
### Implement a new pruning algorithm
Implementing a new pruning algorithm requires implementing a `weight masker` class which shoud be a subclass of `WeightMasker`, and a `pruner` class, which should a subclass `Pruner`.
Implementing a new pruning algorithm requires implementing a `weight masker` class which shoud be a subclass of `WeightMasker`, and a `pruner` class, which should be a subclass `Pruner`.
An implementation of `weight masker` may look like this:
An implementation of `weight masker` may look like this:
...
@@ -74,7 +84,7 @@ class MyMasker(WeightMasker):
...
@@ -74,7 +84,7 @@ class MyMasker(WeightMasker):
You can reference nni provided [weight masker](https://github.com/microsoft/nni/blob/master/src/sdk/pynni/nni/compression/torch/pruning/structured_pruning.py) implementations to implement your own weight masker.
You can reference nni provided [weight masker](https://github.com/microsoft/nni/blob/master/src/sdk/pynni/nni/compression/torch/pruning/structured_pruning.py) implementations to implement your own weight masker.
On multi-GPU training, buffers and parameters are copied to multiple GPU every time the `forward` method runs on multiple GPU. If buffers and parameters are updated in the `forward` method, an `in-place` update is needed to ensure the update is effective.
On multi-GPU training, buffers and parameters are copied to multiple GPU every time the `forward` method runs on multiple GPU. If buffers and parameters are updated in the `forward` method, an `in-place` update is needed to ensure the update is effective.
Since `calc_mask` is called in the `optimizer.step` method, which happens after the `forward` method and happens only on one GPU, it supports multi-GPU naturally.
Since `calc_mask` is called in the `optimizer.step` method, which happens after the `forward` method and happens only on one GPU, it supports multi-GPU naturally.
***
## Customize a new quantization algorithm
To write a new quantization algorithm, you can write a class that inherits `nni.compression.torch.Quantizer`. Then, override the member functions with the logic of your algorithm. The member function to override is `quantize_weight`. `quantize_weight` directly returns the quantized weights rather than mask, because for quantization the quantized weights cannot be obtained by applying mask.
```python
fromnni.compression.torchimportQuantizer
classYourQuantizer(Quantizer):
def__init__(self,model,config_list):
"""
Suggest you to use the NNI defined spec for config
"""
super().__init__(model,config_list)
defquantize_weight(self,weight,config,**kwargs):
"""
quantize should overload this method to quantize weight tensors.
This method is effectively hooked to :meth:`forward` of the model.
Parameters
----------
weight : Tensor
weight that needs to be quantized
config : dict
the configuration for weight quantization
"""
# Put your code to generate `new_weight` here
returnnew_weight
defquantize_output(self,output,config,**kwargs):
"""
quantize should overload this method to quantize output.
This method is effectively hooked to `:meth:`forward` of the model.
Parameters
----------
output : Tensor
output that needs to be quantized
config : dict
the configuration for output quantization
"""
# Put your code to generate `new_output` here
returnnew_output
defquantize_input(self,*inputs,config,**kwargs):
"""
quantize should overload this method to quantize input.
This method is effectively hooked to :meth:`forward` of the model.
Parameters
----------
inputs : Tensor
inputs that needs to be quantized
config : dict
the configuration for inputs quantization
"""
# Put your code to generate `new_input` here
returnnew_input
defupdate_epoch(self,epoch_num):
pass
defstep(self):
"""
Can do some processing based on the model or weights binded
in the func bind_model
"""
pass
```
### Customize backward function
Sometimes it's necessary for a quantization operation to have a customized backward function, such as [Straight-Through Estimator](https://stackoverflow.com/questions/38361314/the-concept-of-straight-through-estimator-ste), user can customize a backward function as follow:
The paper [The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks](https://arxiv.org/abs/1803.03635) is mainly a measurement and analysis paper, it delivers very interesting insights. To support it on NNI, we mainly implement the training approach for finding *winning tickets*.
In this paper, the authors use the following process to prune a model, called *iterative prunning*:
>2. Train the network for j iterations, arriving at parameters theta_j.
>3. Prune p% of the parameters in theta_j, creating a mask m.
>4. Reset the remaining parameters to their values in theta_0, creating the winning ticket f(x;m*theta_0).
>5. Repeat step 2, 3, and 4.
If the configured final sparsity is P (e.g., 0.8) and there are n times iterative pruning, each iterative pruning prunes 1-(1-P)^(1/n) of the weights that survive the previous round.
## Reproduce Results
We try to reproduce the experiment result of the fully connected network on MNIST using the same configuration as in the paper. The code can be referred [here](https://github.com/microsoft/nni/tree/master/examples/model_compress/lottery_torch_mnist_fc.py). In this experiment, we prune 10 times, for each pruning we train the pruned model for 50 epochs.

The above figure shows the result of the fully connected network. `round0-sparsity-0.0` is the performance without pruning. Consistent with the paper, pruning around 80% also obtain similar performance compared to non-pruning, and converges a little faster. If pruning too much, e.g., larger than 94%, the accuracy becomes lower and convergence becomes a little slower. A little different from the paper, the trend of the data in the paper is relatively more clear.
We provide several pruning algorithms that support fine-grained weight pruning and structural filter pruning. **Weight pruning** generally results in unstructured models, which need specialized haredware or software to speed up the sparse network. **Filter Pruning** achieves acceleratation by removing the entire filter. We also provide an algorithm to control the **pruning schedule**.
*[Filter Pruners with Weight Rank](#weightrankfilterpruner)
*[Filter Pruners with Weight Rank](#weightrankfilterpruner)
*[FPGM Pruner](#fpgm-pruner)
*[FPGM Pruner](#fpgm-pruner)
...
@@ -15,6 +18,9 @@ Index of supported pruning algorithms
...
@@ -15,6 +18,9 @@ Index of supported pruning algorithms
*[Activation Mean Rank Pruner](#activationmeanrankfilterpruner)
*[Activation Mean Rank Pruner](#activationmeanrankfilterpruner)
*[Filter Pruners with Gradient Rank](#gradientrankfilterpruner)
*[Filter Pruners with Gradient Rank](#gradientrankfilterpruner)
*[Taylor FO On Weight Pruner](#taylorfoweightfilterpruner)
*[Taylor FO On Weight Pruner](#taylorfoweightfilterpruner)
**Pruning Schedule**
*[AGP Pruner](#agp-pruner)
## Level Pruner
## Level Pruner
...
@@ -145,7 +151,7 @@ for _ in pruner.get_prune_iterations():
...
@@ -145,7 +151,7 @@ for _ in pruner.get_prune_iterations():
...
...
```
```
The above configuration means that there are 5 times of iterative pruning. As the 5 times iterative pruning are executed in the same run, LotteryTicketPruner needs `model` and `optimizer` (**Note that should add `lr_scheduler` if used**) to reset their states every time a new prune iteration starts. Please use `get_prune_iterations` to get the pruning iterations, and invoke `prune_iteration_start` at the beginning of each iteration. `epoch_num` is better to be large enough for model convergence, because the hypothesis is that the performance (accuracy) got in latter rounds with high sparsity could be comparable with that got in the first round. Simple reproducing results can be found [here](./LotteryTicketHypothesis.md).
The above configuration means that there are 5 times of iterative pruning. As the 5 times iterative pruning are executed in the same run, LotteryTicketPruner needs `model` and `optimizer` (**Note that should add `lr_scheduler` if used**) to reset their states every time a new prune iteration starts. Please use `get_prune_iterations` to get the pruning iterations, and invoke `prune_iteration_start` at the beginning of each iteration. `epoch_num` is better to be large enough for model convergence, because the hypothesis is that the performance (accuracy) got in latter rounds with high sparsity could be comparable with that got in the first round.
*Tensorflow version will be supported later.*
*Tensorflow version will be supported later.*
...
@@ -155,6 +161,14 @@ The above configuration means that there are 5 times of iterative pruning. As th
...
@@ -155,6 +161,14 @@ The above configuration means that there are 5 times of iterative pruning. As th
***prune_iterations:** The number of rounds for the iterative pruning, i.e., the number of iterative pruning.
***prune_iterations:** The number of rounds for the iterative pruning, i.e., the number of iterative pruning.
***sparsity:** The final sparsity when the compression is done.
***sparsity:** The final sparsity when the compression is done.
### Reproduced Experiment
We try to reproduce the experiment result of the fully connected network on MNIST using the same configuration as in the paper. The code can be referred [here](https://github.com/microsoft/nni/tree/master/examples/model_compress/lottery_torch_mnist_fc.py). In this experiment, we prune 10 times, for each pruning we train the pruned model for 50 epochs.

The above figure shows the result of the fully connected network. `round0-sparsity-0.0` is the performance without pruning. Consistent with the paper, pruning around 80% also obtain similar performance compared to non-pruning, and converges a little faster. If pruning too much, e.g., larger than 94%, the accuracy becomes lower and convergence becomes a little slower. A little different from the paper, the trend of the data in the paper is relatively more clear.
***
***
## Slim Pruner
## Slim Pruner
...
@@ -181,6 +195,18 @@ pruner.compress()
...
@@ -181,6 +195,18 @@ pruner.compress()
-**sparsity:** This is to specify the sparsity operations to be compressed to
-**sparsity:** This is to specify the sparsity operations to be compressed to
-**op_types:** Only BatchNorm2d is supported in Slim Pruner
-**op_types:** Only BatchNorm2d is supported in Slim Pruner
### Reproduced Experiment
We implemented one of the experiments in ['Learning Efficient Convolutional Networks through Network Slimming'](https://arxiv.org/pdf/1708.06519.pdf), we pruned $70\%$ channels in the **VGGNet** for CIFAR-10 in the paper, in which $88.5\%$ parameters are pruned. Our experiments results are as follows:
| Model | Error(paper/ours) | Parameters | Pruned |
The experiments code can be found at [examples/model_compress](https://github.com/microsoft/nni/tree/master/examples/model_compress/)
***
## WeightRankFilterPruner
## WeightRankFilterPruner
WeightRankFilterPruner is a series of pruners which prune the filters with the smallest importance criterion calculated from the weights in convolution layers to achieve a preset level of network sparsity
WeightRankFilterPruner is a series of pruners which prune the filters with the smallest importance criterion calculated from the weights in convolution layers to achieve a preset level of network sparsity
...
@@ -238,7 +264,7 @@ You can view example for more information
...
@@ -238,7 +264,7 @@ You can view example for more information
### L1Filter Pruner
### L1Filter Pruner
This is an one-shot pruner, In ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710), authors Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet and Hans Peter Graf. The reproduced experiment results can be found [here](l1filterpruner.md)
This is an one-shot pruner, In ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710), authors Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet and Hans Peter Graf.


...
@@ -270,6 +296,17 @@ pruner.compress()
...
@@ -270,6 +296,17 @@ pruner.compress()
-**sparsity:** This is to specify the sparsity operations to be compressed to
-**sparsity:** This is to specify the sparsity operations to be compressed to
-**op_types:** Only Conv1d and Conv2d is supported in L1Filter Pruner
-**op_types:** Only Conv1d and Conv2d is supported in L1Filter Pruner
#### Reproduced Experiment
We implemented one of the experiments in ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710) with **L1FilterPruner**, we pruned **VGG-16** for CIFAR-10 to **VGG-16-pruned-A** in the paper, in which $64\%$ parameters are pruned. Our experiments results are as follows:
| Model | Error(paper/ours) | Parameters | Pruned |
The experiments code can be found at [examples/model_compress](https://github.com/microsoft/nni/tree/master/examples/model_compress/)
***
***
### L2Filter Pruner
### L2Filter Pruner
...
@@ -292,6 +329,8 @@ pruner.compress()
...
@@ -292,6 +329,8 @@ pruner.compress()
-**sparsity:** This is to specify the sparsity operations to be compressed to
-**sparsity:** This is to specify the sparsity operations to be compressed to
-**op_types:** Only Conv1d and Conv2d is supported in L2Filter Pruner
-**op_types:** Only Conv1d and Conv2d is supported in L2Filter Pruner
***
## ActivationRankFilterPruner
## ActivationRankFilterPruner
ActivationRankFilterPruner is a series of pruners which prune the filters with the smallest importance criterion calculated from the output activations of convolution layers to achieve a preset level of network sparsity.
ActivationRankFilterPruner is a series of pruners which prune the filters with the smallest importance criterion calculated from the output activations of convolution layers to achieve a preset level of network sparsity.
...
@@ -355,6 +394,7 @@ You can view example for more information
...
@@ -355,6 +394,7 @@ You can view example for more information
-**sparsity:** How much percentage of convolutional filters are to be pruned.
-**sparsity:** How much percentage of convolutional filters are to be pruned.
-**op_types:** Only Conv2d is supported in ActivationMeanRankFilterPruner.
-**op_types:** Only Conv2d is supported in ActivationMeanRankFilterPruner.
We provide Naive Quantizer to quantizer weight to default 8 bits, you can use it to test quantize algorithm without any configure.
We provide Naive Quantizer to quantizer weight to default 8 bits, you can use it to test quantize algorithm without any configure.
...
@@ -47,7 +53,8 @@ quantizer.compress()
...
@@ -47,7 +53,8 @@ quantizer.compress()
You can view example for more information
You can view example for more information
#### User configuration for QAT Quantizer
#### User configuration for QAT Quantizer
common configuration needed by compression algorithms can be found at : [Common configuration](./Overview.md#User-configuration-for-a-compression-algorithm)
common configuration needed by compression algorithms can be found at [Specification of `config_list`](./QuickStart.md).
configuration needed by this algorithm :
configuration needed by this algorithm :
...
@@ -57,13 +64,17 @@ disable quantization until model are run by certain number of steps, this allows
...
@@ -57,13 +64,17 @@ disable quantization until model are run by certain number of steps, this allows
state where activation quantization ranges do not exclude a significant fraction of values, default value is 0
state where activation quantization ranges do not exclude a significant fraction of values, default value is 0
### note
### note
batch normalization folding is currently not supported.
batch normalization folding is currently not supported.
***
***
## DoReFa Quantizer
## DoReFa Quantizer
In [DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients](https://arxiv.org/abs/1606.06160), authors Shuchang Zhou and Yuxin Wu provide an algorithm named DoReFa to quantize the weight, activation and gradients with training.
In [DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients](https://arxiv.org/abs/1606.06160), authors Shuchang Zhou and Yuxin Wu provide an algorithm named DoReFa to quantize the weight, activation and gradients with training.
### Usage
### Usage
To implement DoReFa Quantizer, you can add code below before your training code
To implement DoReFa Quantizer, you can add code below before your training code
PyTorch code
PyTorch code
...
@@ -81,12 +92,15 @@ quantizer.compress()
...
@@ -81,12 +92,15 @@ quantizer.compress()
You can view example for more information
You can view example for more information
#### User configuration for DoReFa Quantizer
#### User configuration for DoReFa Quantizer
common configuration needed by compression algorithms can be found at : [Common configuration](./Overview.md#User-configuration-for-a-compression-algorithm)
common configuration needed by compression algorithms can be found at [Specification of `config_list`](./QuickStart.md).
configuration needed by this algorithm :
configuration needed by this algorithm :
***
## BNN Quantizer
## BNN Quantizer
In [Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1](https://arxiv.org/abs/1602.02830),
In [Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1](https://arxiv.org/abs/1602.02830),
>We introduce a method to train Binarized Neural Networks (BNNs) - neural networks with binary weights and activations at run-time. At training-time the binary weights and activations are used for computing the parameters gradients. During the forward pass, BNNs drastically reduce memory size and accesses, and replace most arithmetic operations with bit-wise operations, which is expected to substantially improve power-efficiency.
>We introduce a method to train Binarized Neural Networks (BNNs) - neural networks with binary weights and activations at run-time. At training-time the binary weights and activations are used for computing the parameters gradients. During the forward pass, BNNs drastically reduce memory size and accesses, and replace most arithmetic operations with bit-wise operations, which is expected to substantially improve power-efficiency.
...
@@ -118,11 +132,13 @@ model = quantizer.compress()
...
@@ -118,11 +132,13 @@ model = quantizer.compress()
You can view example [examples/model_compress/BNN_quantizer_cifar10.py](https://github.com/microsoft/nni/tree/master/examples/model_compress/BNN_quantizer_cifar10.py) for more information.
You can view example [examples/model_compress/BNN_quantizer_cifar10.py](https://github.com/microsoft/nni/tree/master/examples/model_compress/BNN_quantizer_cifar10.py) for more information.
#### User configuration for BNN Quantizer
#### User configuration for BNN Quantizer
common configuration needed by compression algorithms can be found at : [Common configuration](./Overview.md#User-configuration-for-a-compression-algorithm)
common configuration needed by compression algorithms can be found at [Specification of `config_list`](./QuickStart.md).
configuration needed by this algorithm :
configuration needed by this algorithm :
### Experiment
### Experiment
We implemented one of the experiments in [Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1](https://arxiv.org/abs/1602.02830), we quantized the **VGGNet** for CIFAR-10 in the paper. Our experiments results are as follows:
We implemented one of the experiments in [Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1](https://arxiv.org/abs/1602.02830), we quantized the **VGGNet** for CIFAR-10 in the paper. Our experiments results are as follows:
NNI provides very simple APIs for compressing a model. The compression includes pruning algorithms and quantization algorithms. The usage of them are the same, thus, here we use slim pruner as an example to show the usage.
```eval_rst
.. contents::
```
In this tutorial, we use the [first section](#quick-start-to-compress-a-model) to quickly go through the usage of model compression on NNI. Then use the [second section](#detailed-usage-guide) to explain more details of the usage.
## Quick Start to Compress a Model
NNI provides very simple APIs for compressing a model. The compression includes pruning algorithms and quantization algorithms. The usage of them are the same, thus, here we use [slim pruner](https://nni.readthedocs.io/en/latest/Compressor/Pruner.html#slim-pruner) as an example to show the usage.
## Write configuration
### Write configuration
Write a configuration to specify the layers that you want to prune. The following configuration means pruning all the `BatchNorm2d`s to sparsity 0.7 while keeping other layers unpruned.
Write a configuration to specify the layers that you want to prune. The following configuration means pruning all the `BatchNorm2d`s to sparsity 0.7 while keeping other layers unpruned.
...
@@ -13,9 +21,9 @@ configure_list = [{
...
@@ -13,9 +21,9 @@ configure_list = [{
}]
}]
```
```
The specification of configuration can be found [here](Overview.md#user-configuration-for-a-compression-algorithm). Note that different pruners may have their own defined fields in configuration, for exmaple `start_epoch` in AGP pruner. Please refer to each pruner's [usage](Overview.md#supported-algorithms) for details, and adjust the configuration accordingly.
The specification of configuration can be found [here](#specification-of-config-list). Note that different pruners may have their own defined fields in configuration, for exmaple `start_epoch` in AGP pruner. Please refer to each pruner's [usage](./Pruner.md) for details, and adjust the configuration accordingly.
## Choose a compression algorithm
### Choose a compression algorithm
Choose a pruner to prune your model. First instantiate the chosen pruner with your model and configuration as arguments, then invoke `compress()` to compress your model.
Choose a pruner to prune your model. First instantiate the chosen pruner with your model and configuration as arguments, then invoke `compress()` to compress your model.
...
@@ -26,7 +34,7 @@ model = pruner.compress()
...
@@ -26,7 +34,7 @@ model = pruner.compress()
Then, you can train your model using traditional training approach (e.g., SGD), pruning is applied transparently during the training. Some pruners prune once at the beginning, the following training can be seen as fine-tune. Some pruners prune your model iteratively, the masks are adjusted epoch by epoch during training.
Then, you can train your model using traditional training approach (e.g., SGD), pruning is applied transparently during the training. Some pruners prune once at the beginning, the following training can be seen as fine-tune. Some pruners prune your model iteratively, the masks are adjusted epoch by epoch during training.
## Export compression result
### Export compression result
After training, you get accuracy of the pruned model. You can export model weights to a file, and the generated masks to a file as well. Exporting onnx model is also supported.
After training, you get accuracy of the pruned model. You can export model weights to a file, and the generated masks to a file as well. Exporting onnx model is also supported.
The complete code of model compression examples can be found [here](https://github.com/microsoft/nni/blob/master/examples/model_compress/model_prune_torch.py).
The complete code of model compression examples can be found [here](https://github.com/microsoft/nni/blob/master/examples/model_compress/model_prune_torch.py).
## Speed up the model
### Speed up the model
Masks do not provide real speedup of your model. The model should be speeded up based on the exported masks, thus, we provide an API to speed up your model as shown below. After invoking `apply_compression_results` on your model, your model becomes a smaller one with shorter inference latency.
Masks do not provide real speedup of your model. The model should be speeded up based on the exported masks, thus, we provide an API to speed up your model as shown below. After invoking `apply_compression_results` on your model, your model becomes a smaller one with shorter inference latency.
...
@@ -45,4 +53,119 @@ from nni.compression.torch import apply_compression_results
...
@@ -45,4 +53,119 @@ from nni.compression.torch import apply_compression_results
You can use other compression algorithms in the package of `nni.compression`. The algorithms are implemented in both PyTorch and TensorFlow (partial support on TensorFlow), under `nni.compression.torch` and `nni.compression.tensorflow` respectively. You can refer to [Pruner](./Pruner.md) and [Quantizer](./Quantizer.md) for detail description of supported algorithms. Also if you want to use knowledge distillation, you can refer to [KDExample](../TrialExample/KDExample.md)
A compression algorithm is first instantiated with a `config_list` passed in. The specification of this `config_list` will be described later.
The function call `pruner.compress()` modifies user defined model (in Tensorflow the model can be obtained with `tf.get_default_graph()`, while in PyTorch the model is the defined model class), and the model is modified with masks inserted. Then when you run the model, the masks take effect. The masks can be adjusted at runtime by the algorithms.
*Note that, `pruner.compress` simply adds masks on model weights, it does not include fine tuning logic. If users want to fine tune the compressed model, they need to write the fine tune logic by themselves after `pruner.compress`.*
### Specification of `config_list`
Users can specify the configuration (i.e., `config_list`) for a compression algorithm. For example,when compressing a model, users may want to specify the sparsity ratio, to specify different ratios for different types of operations, to exclude certain types of operations, or to compress only a certain types of operations. For users to express these kinds of requirements, we define a configuration specification. It can be seen as a python `list` object, where each element is a `dict` object.
The `dict`s in the `list` are applied one by one, that is, the configurations in latter `dict` will overwrite the configurations in former ones on the operations that are within the scope of both of them.
There are different keys in a `dict`. Some of them are common keys supported by all the compression algorithms:
* __op_types__: This is to specify what types of operations to be compressed. 'default' means following the algorithm's default setting.
* __op_names__: This is to specify by name what operations to be compressed. If this field is omitted, operations will not be filtered by it.
* __exclude__: Default is False. If this field is True, it means the operations with specified types and names will be excluded from the compression.
Some other keys are often specific to a certain algorithms, users can refer to [pruning algorithms](./Pruner.md) and [quantization algorithms](./Quantizer.md) for the keys allowed by each algorithm.
A simple example of configuration is shown below:
```python
[
{
'sparsity':0.8,
'op_types':['default']
},
{
'sparsity':0.6,
'op_names':['op_name1','op_name2']
},
{
'exclude':True,
'op_names':['op_name3']
}
]
```
It means following the algorithm's default setting for compressed operations with sparsity 0.8, but for `op_name1` and `op_name2` use sparsity 0.6, and do not compress `op_name3`.
#### Quantization specific keys
**If you use quantization algorithms, you need to specify more keys. If you use pruning algorithms, you can safely skip these keys**
* __quant_types__ : list of string.
Type of quantization you want to apply, currently support 'weight', 'input', 'output'. 'weight' means applying quantization operation
to the weight parameter of modules. 'input' means applying quantization operation to the input of module forward method. 'output' means applying quantization operation to the output of module forward method, which is often called as 'activation' in some papers.
* __quant_bits__ : int or dict of {str : int}
bits length of quantization, key is the quantization type, value is the quantization bits length, eg.
```
{
quant_bits: {
'weight': 8,
'output': 4,
},
}
```
when the value is int type, all quantization types share same bits length. eg.
```
{
quant_bits: 8, # weight or output quantization are all 8 bits
}
```
### APIs for Updating Fine Tuning Status
Some compression algorithms use epochs to control the progress of compression (e.g. [AGP](https://nni.readthedocs.io/en/latest/Compressor/Pruner.html#agp-pruner)), and some algorithms need to do something after every minibatch. Therefore, we provide another two APIs for users to invoke: `pruner.update_epoch(epoch)` and `pruner.step()`.
`update_epoch` should be invoked in every epoch, while `step` should be invoked after each minibatch. Note that most algorithms do not require calling the two APIs. Please refer to each algorithm's document for details. For the algorithms that do not need them, calling them is allowed but has no effect.
### Export Compressed Model
You can easily export the compressed model using the following API if you are pruning your model, ```state_dict``` of the sparse model weights will be stored in ```model.pth```, which can be loaded by ```torch.load('model.pth')```. In this exported ```model.pth```, the masked weights are zero.
```
pruner.export_model(model_path='model.pth')
```
```mask_dict ``` and pruned model in ```onnx``` format(```input_shape``` need to be specified) can also be exported like this:
SlimPruner is a structured pruning algorithm for pruning channels in the convolutional layers by pruning corresponding scaling factors in the later BN layers.
In ['Learning Efficient Convolutional Networks through Network Slimming'](https://arxiv.org/pdf/1708.06519.pdf), authors Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan and Changshui Zhang.

> Slim Pruner **prunes channels in the convolution layers by masking corresponding scaling factors in the later BN layers**, L1 regularization on the scaling factors should be applied in batch normalization (BN) layers while training, scaling factors of BN layers are **globally ranked** while pruning, so the sparse model can be automatically found given sparsity.
-**sparsity:** This is to specify the sparsity operations to be compressed to
-**op_types:** Only BatchNorm2d is supported in Slim Pruner
## 3. Experiment
We implemented one of the experiments in ['Learning Efficient Convolutional Networks through Network Slimming'](https://arxiv.org/pdf/1708.06519.pdf), we pruned $70\%$ channels in the **VGGNet** for CIFAR-10 in the paper, in which $88.5\%$ parameters are pruned. Our experiments results are as follows:
| Model | Error(paper/ours) | Parameters | Pruned |
L1FilterPruner is a general structured pruning algorithm for pruning filters in the convolutional layers.
In ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710), authors Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet and Hans Peter Graf.

> L1Filter Pruner prunes filters in the **convolution layers**
>
> The procedure of pruning m filters from the ith convolutional layer is as follows:
>
> 1. For each filter , calculate the sum of its absolute kernel weights
> 2. Sort the filters by 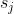.
> 3. Prune 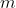 filters with the smallest sum values and their corresponding feature maps. The
> kernels in the next convolutional layer corresponding to the pruned feature maps are also
> removed.
> 4. A new kernel matrix is created for both the th and 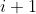th layers, and the remaining kernel
> weights are copied to the new model.
## Experiment
We implemented one of the experiments in ['PRUNING FILTERS FOR EFFICIENT CONVNETS'](https://arxiv.org/abs/1608.08710) with **L1FilterPruner**, we pruned **VGG-16** for CIFAR-10 to **VGG-16-pruned-A** in the paper, in which $64\%$ parameters are pruned. Our experiments results are as follows:
| Model | Error(paper/ours) | Parameters | Pruned |
