Megatron ([1](https://arxiv.org/pdf/1909.08053.pdf) and[2](https://arxiv.org/pdf/2104.04473.pdf)) is a large, powerful transformer developed by the Applied Deep Learning Research team at NVIDIA. This repository is for ongoing research on training large transformer language models at scale. We developed efficient, model-parallel (tensor and pipeline), and multi-node pre-training of transformer based models such as [GPT](https://arxiv.org/abs/2005.14165), [BERT](https://arxiv.org/pdf/1810.04805.pdf), and [T5](https://arxiv.org/abs/1910.10683) using mixed precision.
Megatron ([1](https://arxiv.org/pdf/1909.08053.pdf),[2](https://arxiv.org/pdf/2104.04473.pdf), and [3](https://arxiv.org/pdf/2205.05198)) is a large, powerful transformer developed by the Applied Deep Learning Research team at NVIDIA. This repository is for ongoing research on training large transformer language models at scale. We developed efficient, model-parallel ([tensor](https://arxiv.org/pdf/1909.08053.pdf), [sequence](https://arxiv.org/pdf/2205.05198), and [pipeline](https://arxiv.org/pdf/2104.04473.pdf)), and multi-node pre-training of transformer based models such as [GPT](https://arxiv.org/abs/2005.14165), [BERT](https://arxiv.org/pdf/1810.04805.pdf), and [T5](https://arxiv.org/abs/1910.10683) using mixed precision.
Below are some of the projects where we have directly used Megatron:
*[BERT and GPT Studies Using Megatron](https://arxiv.org/pdf/1909.08053.pdf)
...
...
@@ -8,19 +8,26 @@ Below are some of the projects where we have directly used Megatron:
*[MEGATRON-CNTRL: Controllable Story Generation with External Knowledge Using Large-Scale Language Models](https://www.aclweb.org/anthology/2020.emnlp-main.226.pdf)
*[Scaling Language Model Training to a Trillion Parameters Using Megatron](https://arxiv.org/pdf/2104.04473.pdf)
*[Training Question Answering Models From Synthetic Data](https://www.aclweb.org/anthology/2020.emnlp-main.468.pdf)
*[Few-shot Instruction Prompts for Pretrained Language Models to Detect Social Biases](https://arxiv.org/abs/2112.07868)
*[Exploring the Limits of Domain-Adaptive Training for Detoxifying Large-Scale Language Models](https://arxiv.org/abs/2202.04173)
*[Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model](https://arxiv.org/abs/2201.11990)
*[Multi-Stage Prompting for Knowledgeable Dialogue Generation](https://arxiv.org/abs/2203.08745)
Megatron is also used in [NeMo Megatron](https://developer.nvidia.com/nvidia-nemo#nemo-megatron), a framework to help enterprises overcome the challenges of building and training sophisticated natural language processing models with billions and trillions of parameters.
Our codebase is capable of efficiently training very large (hundreds of billions of parameters) language models with both model and data parallelism. To demonstrate how the code scales with multiple GPUs and model sizes, we consider GPT models from 1 billion all the way to 1 trillion parameters. All models use a vocabulary size of 51,200 and a sequence length of 2048. We vary hidden size, number of attention heads, and number of layers to arrive at a specifc model size. As the model size increases, we also modestly increase the batch size. We leverage [NVIDIA's Selene supercomputer](https://www.top500.org/system/179842/) to perform scaling studies and use up to 3072 [A100](https://www.nvidia.com/en-us/data-center/a100/) GPUs for the largest model. Each cluster node has 8 NVIDIA 80GB A100 GPUs. The table below shows the model configurations along with the achieved FLOPs (both per GPU and aggregate over all GPUs). Note that these results are from benchmark runs and these models were not trained to convergence; however, the FLOPs are measured for end-to-end training, i.e., includes all operations including data loading, optimization, and even logging.
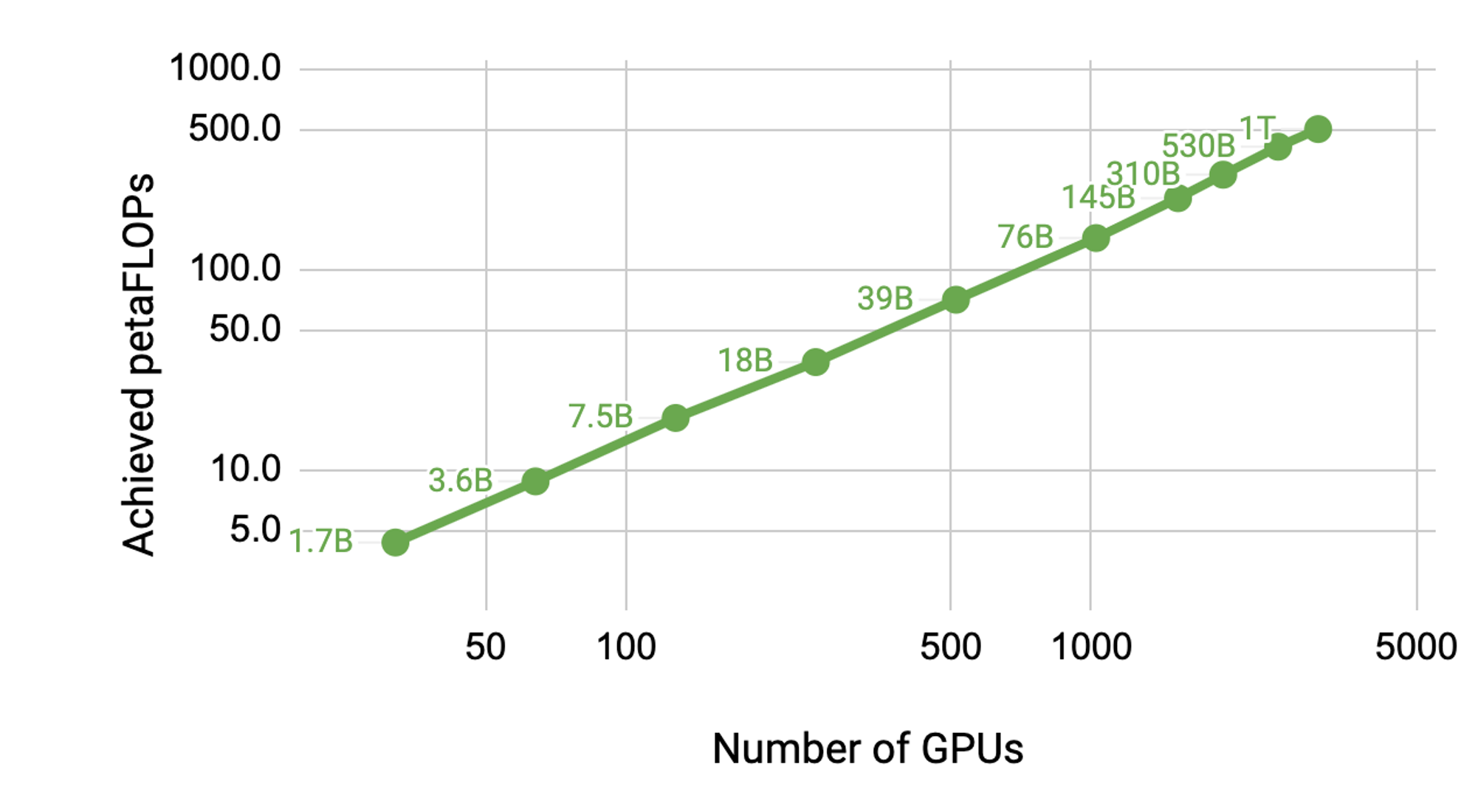
Our codebase is capable of efficiently training very large (hundreds of billions of parameters) language models with both model and data parallelism. To demonstrate how the code scales with multiple GPUs and model sizes, we consider GPT models from 1 billion all the way to 1 trillion parameters. All models use a vocabulary size of 51,200 and a sequence length of 2048. We vary hidden size, number of attention heads, and number of layers to arrive at a specifc model size. As the model size increases, we also modestly increase the batch size. We leverage [NVIDIA's Selene supercomputer](https://www.top500.org/system/179842/) to perform scaling studies and use up to 3072 [A100](https://www.nvidia.com/en-us/data-center/a100/) GPUs for the largest model. Each cluster node has 8 NVIDIA 80GB A100 GPUs. The graph below shows that we scale nearly linear up to 1 trillion parameter models running on 3072 GPUs. Note that these results are from benchmark runs and these models were not trained to convergence; however, the FLOPs are measured for end-to-end training, i.e., includes all operations including data loading, optimization, and even logging.
Additionally, the model parallel size column reports a combined tensor and pipeline parallelism degrees. For numbers larger than 8, typically tensor parallel of size 8 was used. So, for example, the 145B model reports the total model parallel size of 64, which means that this setup used TP=8 and PP=8.


All the cases from 1 billion to 1 trillion parameters achieve more than 43% half precision utilization, which is high for an end-to-end application. We observe that initially the utilization remains constant but as hidden size increases for larger models, utilization starts increasing and reaches 52% for the largest model. We also note that achieved aggregate petaFLOPs across all GPUs increases almost linearly with number of GPUs, demonstrating good weak scaling.
The following table shows both model (MFU) and hardware (HFU) FLOPs utilization for select configurations up to 1T parameters (see [our paper](https://arxiv.org/pdf/2205.05198) for a description of how these are calculated). As the model size increases, we achieve better GPU utilization and for the one trillion parameter model, we reach a MFU and HFU of 56.3% and 57.0%, respectively. Note that these numbers are also measured on benchmark runs and in this case are measured using a data parallel size of one. Data parallelism introduces some overhead due to the gradient all-reduce required between the data parallel groups. However, for large transformer models, this overhead is not large and can almost entirely eliminted by overlapping the gradient all-reduce with backpropagation.
| Model Size | Model FLOPs Utilization | Hardware FLOPs Utilization |
| :---: | :---: | :---: |
| 22B | 41.5% | 43.7% |
| 175B | 51.4% | 52.8% |
| 530B | 56.0% | 57.0% |
| 1T | 56.3% | 57.0% |
# Contents
*[Contents](#contents)
...
...
@@ -257,7 +264,9 @@ The `examples/pretrain_{bert,gpt,t5}_distributed.sh` scripts use the PyTorch dis
We use two types of parallelism: data and model parallelism. We facilitate two distributed data parallel implementations: a simple one of our own that performs gradient all-reduce at the end of back propagation step, and Torch's distributed data parallel wrapper that overlaps gradient reduction with back propagation computation. To switch between these two options use `--DDP-impl local` or `--DDP-impl torch`, respectively. As expected, Torch distributed data parallelism is more efficient at larger model sizes. For example, for the 8.3 billion parameters model running on 512 GPUs, the scaling increases from 60% to 76% when Torch's distributed data parallel is used. However, the overlapping method requires more memory and for some configurations (e.g., 2.5 billion parameters using 2-way model parallel and 1.2 billion parameters with no model parallel) can make the overall training slower as a result. We empirically found that using a smaller model in those cases improves the training time.
Second, we developed a simple and efficient two-dimensional model-parallel approach. To use tensor model parallelism (splitting execution of a single transformer module over multiple GPUs), add the `--tensor-model-parallel-size` flag to specify the number of GPUs among which to split the model, along with the arguments passed to the distributed launcher as mentioned above. To use pipeline model parallelism (sharding the transformer modules into stages with an equal number of transformer modules on each stage, and then pipelining execution by breaking the batch into smaller microbatches), use the `--pipeline-model-parallel-size` flag to specify the number of stages to split the model into (e.g., splitting a model with 24 transformer layers across 4 stages would mean each stage gets 6 transformer layers each).
Second, we developed a simple and efficient two-dimensional model-parallel approach. To use tensor model parallelism (splitting execution of a single transformer module over multiple GPUs), add the `--tensor-model-parallel-size` flag to specify the number of GPUs among which to split the model, along with the arguments passed to the distributed launcher as mentioned above. To use sequence parallelism specify `--sequence-parallel`, which requires tensor model parallel as it split among the same GPUs.
To use pipeline model parallelism (sharding the transformer modules into stages with an equal number of transformer modules on each stage, and then pipelining execution by breaking the batch into smaller microbatches), use the `--pipeline-model-parallel-size` flag to specify the number of stages to split the model into (e.g., splitting a model with 24 transformer layers across 4 stages would mean each stage gets 6 transformer layers each).
<!-- The number of microbatches in a per-pipeline minibatch is controlled by the `--num-microbatches-in-minibatch` argument. With `WORLD_SIZE` GPUs, `TENSOR_MP_SIZE` tensor-model-parallel size, `PIPELINE_MP_SIZE` pipeline-model-parallel-size, `WORLD_SIZE`/(`TENSOR_MP_SIZE` * `PIPELINE_MP_SIZE`) GPUs will be used for data parallelism. The default values for `--tensor-model-parallel-size` and `--pipeline-model-parallel-size` is 1, which will not implement either form of model parallelism. -->
@@ -298,11 +308,13 @@ The interleaved pipelining schedule (more details in Section 2.2.2 of [our paper
## Activation Checkpointing and Recomputation
To reduce GPU memory usage so deploy a large model to a training system, we support activation checkpointing and recomputation. We use a Transformer layer as the unit of checkpointing because the activation size bloats in the middle of a Transformer layer so checkpointing the input of a Transformer layer is storage-efficient. We support two activation checkpointing methods: `uniform` and `block`.
To reduce GPU memory usage so deploy a large model to a training system, we support activation checkpointing and recomputation. We support two levels of recompute granularity: `selective` and `full`. Selective recomputation is the default and recommended in almost all cases. It saves the activations that take less space and are expensive to recompute and recomputes activations that take a lot of space but are relatively cheap to recompute (see [our paper](https://arxiv.org/pdf/2205.05198) for details). To enable selective activation recompute simply use `--recompute-activations`.
For cases where memory is very tight, `full` checkpointing saves just the inputs to a transformer layer, or a block of transformer layers, and recomputes everything else. To turn on full activation recompute use `--recompute-granularity full`. When using full activation recomputation, there are two methods: `uniform` and `block`, chosen using the `--recompute-method` argument.
Uniform method uniformly divides the Transformer layers into groups of layers and stores the input activations of each group in the memory. The baseline group size is 1 and, in this case, the input activation of each Transformer layer is checkpointed. When the GPU memory is insufficient, increasing the number of layers per group reduces the memory usage thus enables running a bigger model. For example, when using the number of layers per group of 4, the input activation of each group of 4 Transformer layers is checkpointed.
*Uniform method uniformly divides the Transformer layers into groups of layers and stores the input activations of each group in the memory. The baseline group size is 1 and, in this case, the input activation of each Transformer layer is checkpointed. When the GPU memory is insufficient, increasing the number of layers per group reduces the memory usage thus enables running a bigger model. For example, when using the number of layers per group of 4, the input activation of each group of 4 Transformer layers is checkpointed.
Block method checkpoints the input activations of a set number of individual Transformer layers per pipeline stage and do the rest of layers without any checkpointing. This method can be used to skip checkpointing some Transformer layers until the GPU memory is fully used, which is applicable only when there is unused GPU memory. Checkpointing fewer transformer layers avoids unnecessary activation recomputation in the backprop thus improves training performance. For example, when we specify 5 layers to checkpoint of 8 layers per pipeline stage, the input activations of only the first 5 Transformer layers are checkpointed and activation recomputation for the rest 3 layers is not needed in the backprop.
*Block method checkpoints the input activations of a set number of individual Transformer layers per pipeline stage and do the rest of layers without any checkpointing. This method can be used to skip checkpointing some Transformer layers until the GPU memory is fully used, which is applicable only when there is unused GPU memory. Checkpointing fewer transformer layers avoids unnecessary activation recomputation in the backprop thus improves training performance. For example, when we specify 5 layers to checkpoint of 8 layers per pipeline stage, the input activations of only the first 5 Transformer layers are checkpointed and activation recomputation for the rest 3 layers is not needed in the backprop.

{kind=link}